Azure Data Factory
An Azure service for ingesting, preparing, and transforming data at scale.
11,623 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EPV%3C/text%3E%3C/svg%3E)
Hi
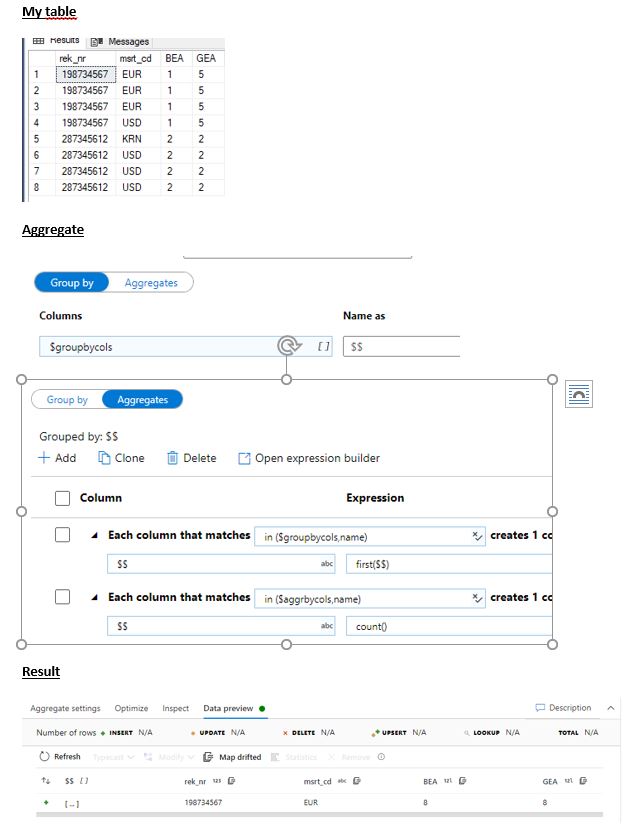
I wanted to try to create a generic aggregation pipeline which can be used for multiple scenarios.
Always more than 1 column to aggregate on, always 1 or more measures to be aggregated.
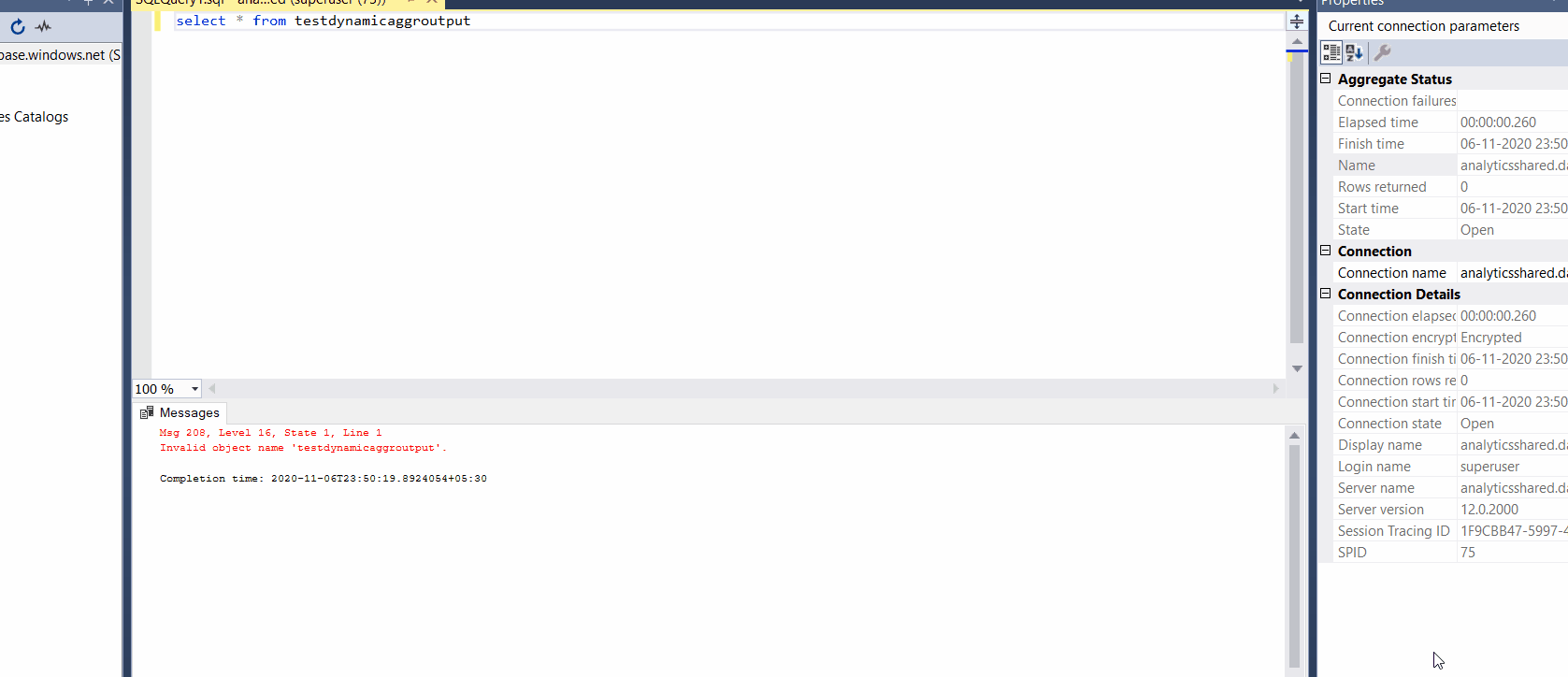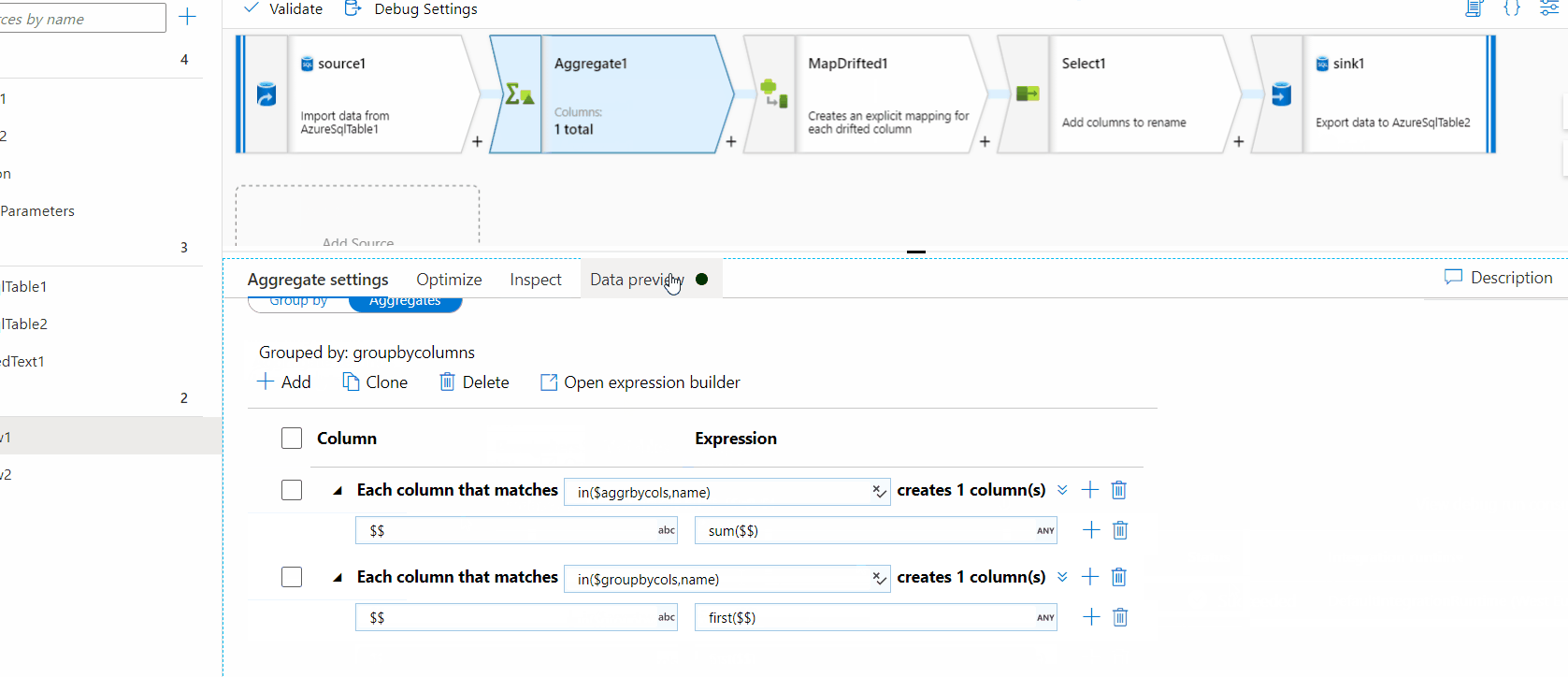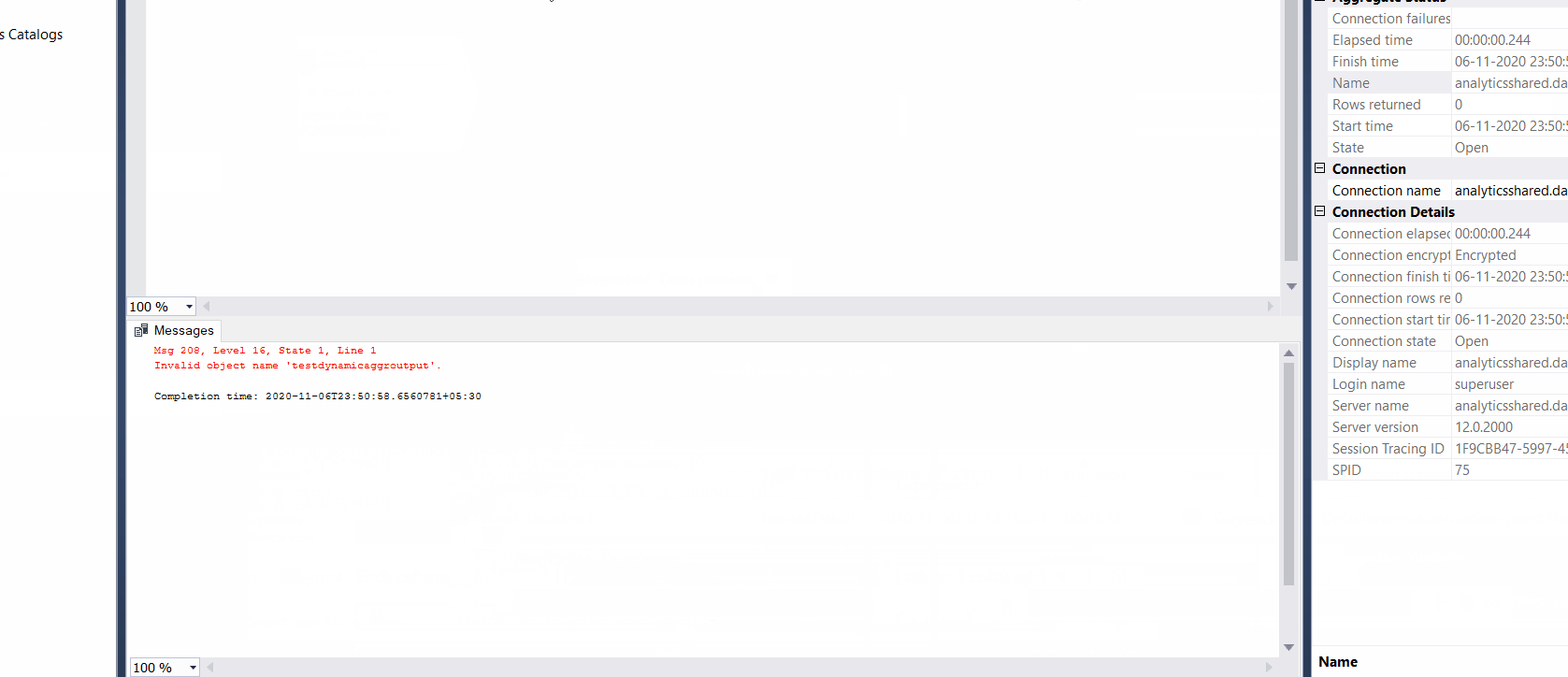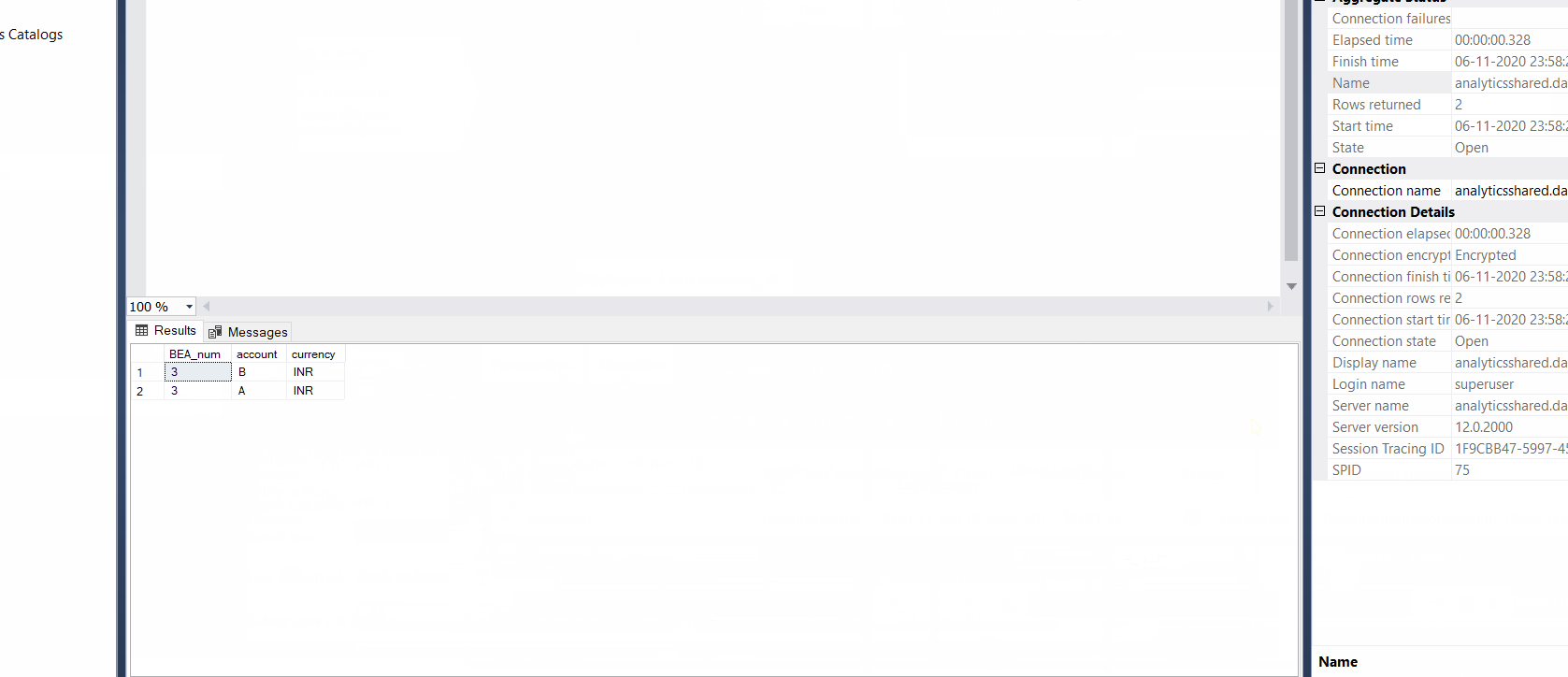
See attachment
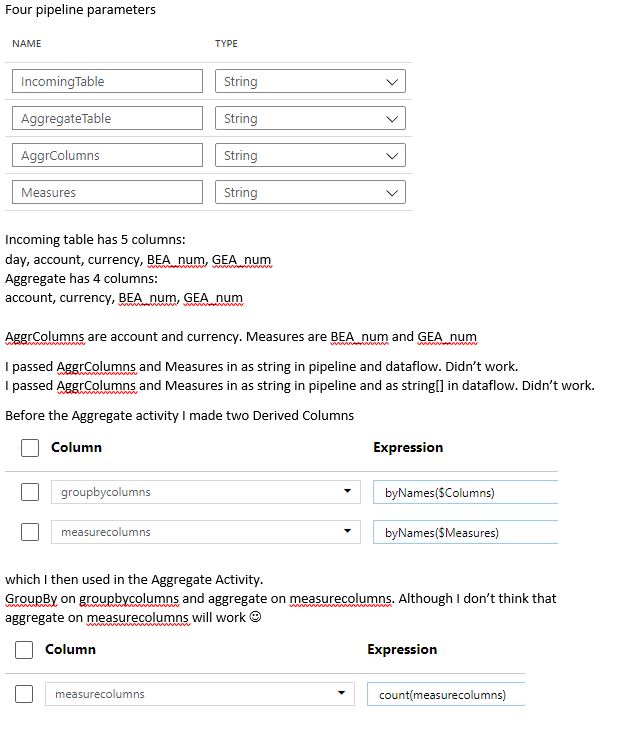
Is there a way to get this working?
regards
Ron
PS Maybe @DanielP-MSFT or @HarithaMaddi-MSFT have a suggestion :)
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EMM%3C/text%3E%3C/svg%3E)
Hello @Poel van der, RE (Ron) and thank you for your question.
Before jumping in and trying to create the data flow, I have a question.
Your source is a table, this suggests SQL or other database. Databases can do this same aggregation in a query. Why not do it directly in the database?
in my example the source is a SQLDB table, but it could also be a Parquet file.
When only having tables, a generic stored procedure could be an option and using dynamic SQL.
Although, not every DBA is happy with dynamic SQL.
ADF is rather new for me, so I am also looking for the boundaries of automating things. And meanwhile learning (although the expression builder sometimes gives me a headache :) )
Aggregation is rather simple. You have some columns where to group by upon, some columns to count.
So, I thought that would be a good candidate to make generic. Invent it once and use it many.
regards
Ron
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EHM%3C/text%3E%3C/svg%3E)
Welcome to Microsoft Q&A Platform. Thanks for posting the query.
Below is one approach I used to implement it. Please use below GIF and attached JSONs for the same.
37719-dataflowjson.txt
37720-pipelinejson.txt
Dynamic Approach:
Also, as the above approach needs knowing the number of columns ahead that are used for aggregations, I added few more transformations(map drifted and select) in addition to suggestions from @DanielP-MSFT and below is the solution for dynamic number of columns. Below is the GIF and attached the code.
38152-dynamicdataflowcodejson.txt
Hope this helps! Please suggest if the requirement is different or for further queries and we will be glad to assist.
--------------------------
Yes, in our approach the number of group by columns and aggregate columns is dynamic. Any idea how to build that in?
I tested you solution, Two points.
In the aggregation it is just counting the number of row, Replacing it with 'sum' fixed this.
The names of outgoing columns should be equal to incoming. Now outgoing is called col1, col2 etc.
regards
Ron
Thanks @Poel van der, RE (Ron) for sharing the observations.

Please suggest if this helps!
your suggestion works. I only left out the Derived Column since it adds nothing of value.
The outcome of the measures is now BEA_num and GEA_num.
In the Aggregation I add '_per_month' to the outgoing measures, so it becomes BEA_num_per_month and GEA_num_per_month
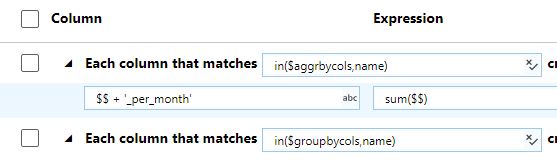
Is it even possible to make 'per_month' a parameter? So that sometimes you call the pipeline whereby one of the parameters = 'per_month' and next time it = 'per_week'??
Regards
Ron
Thanks @Poel van der, RE (Ron) for confirming the design. Yes, it is possible to do so , please find below snap showing the approach to do the same where $append is the parameter I have created for passing "per_month" or "per_week" value.

Please suggest for any further queries and we will be glad to assist.
this works
Thnx for all the work and of course also thanks to @DanielP-MSFT for giving the starting point.
With much regards
Ron

Hey @Poel van der, RE (Ron) ,
What it looks like you are missing is wrapping the byNames() function with array() as byNames() returns an any type.
In the aggregation groupBy, you will select groupByColumns as your grouping condition (this will create a single row for each unique array value).
In the aggregation columns, you will need two column patterns.
in($columns, name) and output first($$) with column name $$ in($measures, name) and output count() with column name $$ Can you try this out and see if it works?
Thanks,
Daniel
Side note: you can also create a computed column to use as your aggregation group by condition and avoid the derive column.
Hi @HarithaMaddi-MSFT and @DanielP-MSFT
this works
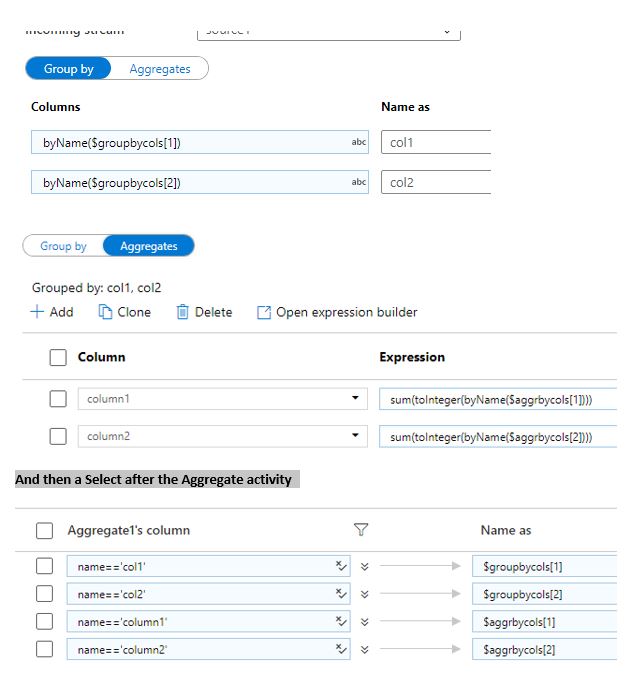
Concerning the dynamic part, I think you mean we can parameterize the script part?
@DanielP-MSFT I will try your suggestion tomorrow. Still get confused by byNames(), array(), when to use split etc.
What exactly do you mean with: you can also create a computed column to use as your aggregation group by condition and avoid the derive column.??
regards
Ron
Hai @DanielP-MSFT couldn'' t wait till tomorrow :)
This is what I did. But what happens is that it takes the first combination of rek_nr, msrt_cd and than counts all rows.
This should be the result
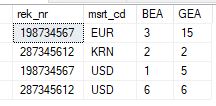
So somewhere something goes wrong
Thanks @Poel van der, RE (Ron) for sharing the observations. Apologies for the delay in responding as I was OOF today. Yes, for dynamic part, I was referring to parameterization of script value in ARM Templates.
I looked at approach suggested by @DanielP-MSFT and facing the same issue as you mentioned. I will also reach out to product team to get more insights on this approach and get back to you as soon as I hear from them.
Thnx @HarithaMaddi-MSFT
Thanks @Poel van der, RE (Ron) for your patience.
I was able to discuss with product team to understand the above suggestion from @DanielP-MSFT and slightly enhanced it to make it dynamic mapping. Added GIF to the above answer. Attached JSON and GIF, please take a look and suggest if that works.
Looking forward for your reply!
We have not received a response from you. Please let us know if above details helped in implementing the requirement and we will be glad to assist for any further queries.
Please do consider to click on "Accept Answer" and "Up-vote" on the post that helps you, as it can be beneficial to other community members