4,707 questions
Here is how to generate a unique GUID. After that you can use it to tag all relevant employees.
SQL
DECLARE @id UNIQUEIDENTIFIER;
SET @id = NEWID();
SELECT @id AS GUID;
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EPO%3C/text%3E%3C/svg%3E)
hello all - we have a software that detects duplicate employee records and spits out the duplicates in combination of two employees at a time in the format below. how can I tag all the combination of these employees with a unique id?
DECLARE @Employees TABLE (EmployeeID1 VARCHAR(50), EmployeeID2 VARCHAR(50))
INSERT INTO @Employees VALUES ('E1', 'E2')
INSERT INTO @Employees VALUES ('E2', 'E3')
INSERT INTO @Employees VALUES ('E4', 'E1')
SELECT * FROM @Employees
For example, all the employees above are one and the same according to the software. I need to generate a random number to tag these employees to indicate they are one and the same.

Show a sample output for these data. Do you need one ID for these four employees?
Just one ID (random) that is same across all the duplicate employees.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EYK%3C/text%3E%3C/svg%3E)
all the employees above are one and the same according to the software.
How do we know it?
While asking a question you need to provide a minimal reproducible example:
(1) DDL and sample data population, i.e. CREATE table(s) plus INSERT, T-SQL statements.
(2) What you need to do, i.e. logic, and your attempt implementation of it in T-SQL.
(3) Desired output based on the sample data in the #1 above.
(4) Your SQL Server version (SELECT @@version;)
I have the scripts needed to produce sample data in my question. The output is hard to describe because all we are doing is grouping the same employees into a bucket using a random ID.
I am using Azure SQL DB.
Employee ID Random ID
E1 12345
E2 12345
E3 12345
E4 12345
where random ID is any id which is same for ever duplicate employee list.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EEM%3C/text%3E%3C/svg%3E)
Is the arrangement of the data like this?

Echo
Hot issues November--What can I do if my transaction log is full?
Hot issues November--How to convert Profiler trace into a SQL Server table
Do you have any updates?
Please remember to accept the answers if they helped. Your action would be helpful to other users who encounter the same issue and read this thread.
Echo
Here is how to generate a unique GUID. After that you can use it to tag all relevant employees.
SQL
DECLARE @id UNIQUEIDENTIFIER;
SET @id = NEWID();
SELECT @id AS GUID;
Check an attempt:
declare @Employees table (EmployeeID1 varchar(50), EmployeeID2 varchar(50))
insert into @Employees values
('E1', 'E2'),
('E2', 'E3'),
('E4', 'E1'),
('E7', 'E8'),
('E9', 'E8')
select * from @Employees
---
declare c cursor for select EmployeeID1, EmployeeID2 from @Employees
open c
declare @EmployeeID1 as varchar(50)
declare @EmployeeID2 as varchar(50)
declare @t as table (EmployeeID varchar(50), ID varchar(50))
fetch next from c into @EmployeeID1, @EmployeeID2
while @@FETCH_STATUS = 0
begin
declare @id1 as varchar(50) = null
declare @id2 as varchar(50) = null
select @id1 = ID from @t where EmployeeID = @EmployeeID1
select @id2 = ID from @t where EmployeeID = @EmployeeID2
if @id1 is not null and @id2 is not null
update @t set ID = @id2 where ID = @id1
if @id1 is not null and @id2 is null
insert @t values (@EmployeeID2, @id1)
if @id1 is null and @id2 is not null
insert @t values (@EmployeeID1, @id2)
if @id1 is null and @id2 is null
insert @t values (@EmployeeID1, @EmployeeID1), (@EmployeeID2, @EmployeeID1)
fetch next from c into @EmployeeID1, @EmployeeID2
end
close c deallocate c
select EmployeeID, convert(varchar(max), cast(ID as varbinary(max)), 2) as UniqueID from @t
order by UniqueID, EmployeeID
/*
EmployeeID UniqueID
E1 4531
E2 4531
E3 4531
E4 4531
E7 4537
E8 4537
E9 4537
*/
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EG%3C/text%3E%3C/svg%3E)
How about this:
DECLARE @Employees TABLE (EmployeeID1 VARCHAR(50), EmployeeID2 VARCHAR(50))
INSERT INTO @Employees VALUES ('E1', 'E2')
INSERT INTO @Employees VALUES ('E2', 'E3')
INSERT INTO @Employees VALUES ('E4', 'E1')
INSERT INTO @Employees VALUES ('E5', 'E6')
INSERT INTO @Employees VALUES ('E6', 'E7')
DECLARE @Employees_Temp TABLE (
EmployeeID1 VARCHAR(50),
EmployeeID2 VARCHAR(50),
EmployeeID3 VARCHAR(50),
EmployeeID4 VARCHAR(50)
);
INSERT INTO @Employees_Temp
SELECT e1.EmployeeID1, e1.EmployeeID2, e2.EmployeeID1, e2.EmployeeID2
FROM @Employees AS e1
FULL JOIN @Employees AS e2 ON e2.EmployeeID2 = e1.EmployeeID1 OR e1.EmployeeID1 = e2.EmployeeID2;
DECLARE @Outputs TABLE (
EmployeeID VARCHAR(50),
RandomID int
);
DECLARE @employeeID1 VARCHAR(50);
DECLARE @employeeID2 VARCHAR(50);
DECLARE @employeeID3 VARCHAR(50);
DECLARE @employeeID4 VARCHAR(50);
DECLARE @randomID int = 12345;
DECLARE Employee_CURSOR CURSOR FOR
SELECT * FROM @Employees_Temp;
OPEN Employee_CURSOR;
FETCH NEXT FROM Employee_CURSOR INTO @employeeID1, @employeeID2, @employeeID3, @employeeID4;
WHILE @@FETCH_STATUS = 0
BEGIN
IF @employeeID1 IS NULL OR @employeeID2 IS NULL OR @employeeID3 IS NULL OR @employeeID4 IS NULL
BEGIN
SET @randomID = @randomID + 100;
END
ELSE
BEGIN
IF NOT EXISTS(SELECT 1 FROM @Outputs WHERE EmployeeID = @employeeID1 AND RandomID = @randomID)
BEGIN
INSERT INTO @Outputs(EmployeeID, RandomID) VALUES(@employeeID1, @randomID);
END
IF NOT EXISTS(SELECT 1 FROM @Outputs WHERE EmployeeID = @employeeID2 AND RandomID = @randomID)
BEGIN
INSERT INTO @Outputs(EmployeeID, RandomID) VALUES(@employeeID2, @randomID);
END
IF NOT EXISTS(SELECT 1 FROM @Outputs WHERE EmployeeID = @employeeID3 AND RandomID = @randomID)
BEGIN
INSERT INTO @Outputs(EmployeeID, RandomID) VALUES(@employeeID3, @randomID);
END
IF NOT EXISTS(SELECT 1 FROM @Outputs WHERE EmployeeID = @employeeID4 AND RandomID = @randomID)
BEGIN
INSERT INTO @Outputs(EmployeeID, RandomID) VALUES(@employeeID4, @randomID);
END
END
FETCH NEXT FROM Employee_CURSOR INTO @employeeID1, @employeeID2, @employeeID3, @employeeID4;
END
CLOSE Employee_CURSOR;
DEALLOCATE Employee_CURSOR;
SELECT * FROM @Outputs;
Here is the output:
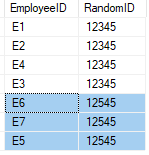
It does not seem to work with these sample data:
INSERT INTO @Employees VALUES ('E1', 'E2')
INSERT INTO @Employees VALUES ('E3', 'E2')
(Nothing is returned).

It seems the software generates a "chain" of duplicate employees based on your sample data. In this case, EmployeeID1 and EmployeeID2 values will be unique, only one EmployeeID1 value will not have a corresponding EmployeeID2 row (start of chain), and only one EmployeeID2 value will not have a corresponding EmployeeID1 row (end of chain).
A recursive CTE could be used to assign a common id to each row of the duplicate employee chain if my assumption about a chain is true. The anchor member of the example CTE below identifies the start of each chain and assigns a unique id for that employee (EmployeeID1 could be used instead for this value). The recursive recursive member follows the chain of dups, returning the unique id from the anchor member so that all rows in the chain have the same value.
DECLARE @Employees TABLE (
RowID int NOT NULL IDENTITY
, EmployeeID1 VARCHAR(50) UNIQUE
, EmployeeID2 VARCHAR(50) UNIQUE
);
INSERT INTO @Employees VALUES
('E1', 'E2')
, ('E2', 'E3')
, ('E4', 'E1')
, ('E5', 'E6')
, ('E8', 'E9')
, ('E7', 'E8')
, ('E6', 'E7')
, ('E10', 'E11')
, ('E12', 'E13')
, ('E13', 'E14');
WITH
duplicate_employees AS (
SELECT e.EmployeeID1, e.EmployeeID2, NEWID() AS UniqueEmployeeID
FROM @Employees AS e
WHERE
e.EmployeeID1 NOT IN(
SELECT EmployeeID2
FROM @Employees AS b
WHERE b.EmployeeID2 <> e.EmployeeID2
)
UNION ALL
SELECT e.EmployeeID1, e.EmployeeID2, duplicate_employees.UniqueEmployeeID
FROM duplicate_employees
JOIN @Employees AS e ON e.EmployeeID1 = duplicate_employees.EmployeeID2
)
SELECT EmployeeID1, EmployeeID2, UniqueEmployeeID
FROM duplicate_employees
ORDER BY UniqueEmployeeID, EmployeeID1;
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EJC%3C/text%3E%3C/svg%3E)
You have a bunch of misconceptions about how RDBMS works. In order to be a table. we must have a key and by definition, a key is a unique. That is, you can't have duplicate rows. That was your old punchcards and filesystems. Also, according to ISO, a table name should be a collective noun that names a set. I seriously doubt that you really have employer identification numbers that are 50 characters long, or even variable length.
Please note that besides the primary key constraint, we also need to make sure that you don't have two identical employees in separate columns. You will find that most of the work in SQL is done with predicates, constraints, normalization and other declarative techniques. We don't like doing this with any kind of procedural code.
CREATE TABLE Personnel
(emp_id1 CHAR(10) NOT NULL,
emp_id2 CHAR(10) NOT NULL,
CHECK (emp_id1 < emp_id2),
PRIMARY KEY (emp_id1, emp_id2));
INSERT INTO Personnel
VALUES ('E1', 'E2'), ('E2', 'E3'),
--- ('E4', 'E1'); wrong ordering
( 'E1', 'E4');
> For example, all the employees above are one and the same according to the software. I need to generate a random number to tag these employees to indicate they are one and the same. <<
I'm not sure exactly what you mean. Given a pair of employees, can I apply this software to the pair and get an equal/not equal result? Or do I have to find that an employee identifier already exists? I also disagree with the idea of creating a random number; why don't you just use the lowest (presumably the first) employee identifier assigned in a matched pair? A few more passes, and you'll eliminate the duplicates. .