System Center Virtual Machine Manager
A family of System Center products that enable enterprise-wide management of virtual machines.
392 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.

Hi All,
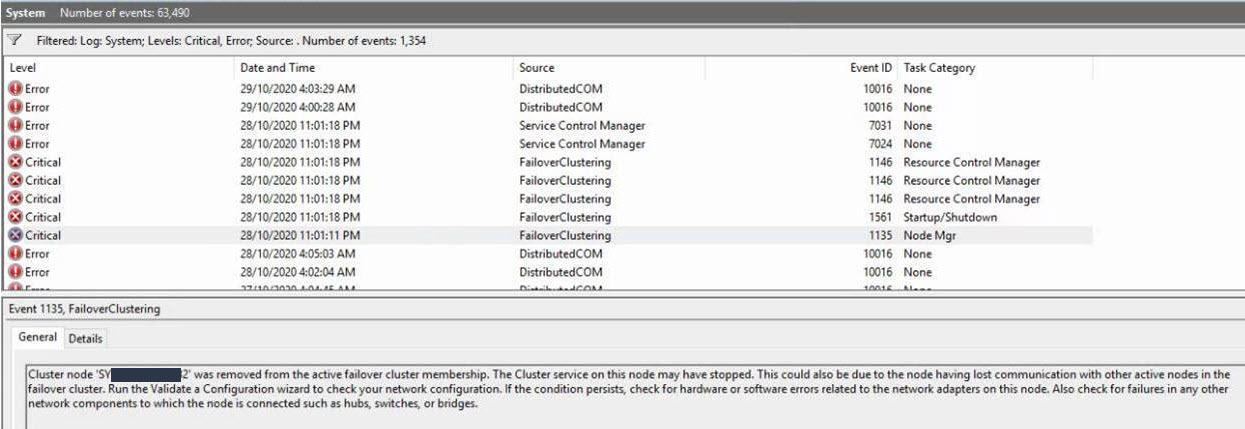
we have a SQL failover cluster with 2 nodes. However, every time we run a snapshot of those nodes as a part of our backup process it will be a getting event ID 1135 which is a cluster node disconnecting. further, we have configured our File Server as a file share witness and it also gets break as a result of that. our two nodes are VMWare hosts.
I have run the validate configuration wizard on fail over a cluster to identify whether there are ongoing network configuration issues from the cluster ends. However, there are no identified network issues from the cluster end by the time I have run the Configuration validation.
appreciate if anyone can let me know the proper solution for this.

I believe the culprits might be snapshots. Microsoft has detailed article on resolving 1135 event ID troubleshooting-cluster-event-id-1135. Did you got a chance to look through it.
Some threads with similar issue
Thank you all...

Hi,
every time we run a snapshot of those nodes as a part of our backup process it will be a getting event ID 1135
As far as I'm concerned, it's better to ask the question "VMWare snapshot cause network drops" instead of troubleshooting cluster 1135.
You may use network monitor tool to capture UDP 3343 packet on the cluster nodes when creating snapshots on VMware hosts, if the traffic always dropped when creating snapshots, then it seems there are some issue with VMWare creating snapshot cause network drop. It's better to turn to VMWare forum for more information.
After research, I found some examples below:
(Please note: Information posted in the given link is hosted by a third party. Microsoft does not guarantee the accuracy and effectiveness of information.)
Thanks for your time!
Best Regards,
Anne
-----------------------------
If the Answer is helpful, please click "Accept Answer" and upvote it.
Note: Please follow the steps in our documentation to enable e-mail notifications if you want to receive the related email notification for this thread.

Hi there,
possible that it is still network related in the combination with taking a snapshot.
I think that for a short amount of time neither heartbeat connection nor connection to witness share is available and therefore one node "goes down".
Also, I'd setup a test environment where you can play around a bit. You don't need to take snapshots then but just quickly disable and enable the virt. NICs (try powershell ) on one Node and see, if you get the same error.
As a workaround, although it is quite uncomfortable:
You may need to work with pre and post commands, e.g. pre command against the passive node to stop clustsvc, take snapshot, start clustsvc.
Node should connect properly again.