Azure Machine Learning
An Azure machine learning service for building and deploying models.
3,334 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EI%3C/text%3E%3C/svg%3E)
Hi,
i deployed a real-time inference pipeline using ML Designer. Training and deploying works fine. But when I'm consuming/testing my API it doesn't work. Postman gives me Errorcode 500 and "Internal Server Error. Run: Server internal error is from Module Extract N-Gram Features from Text".
This is my training pipeline:
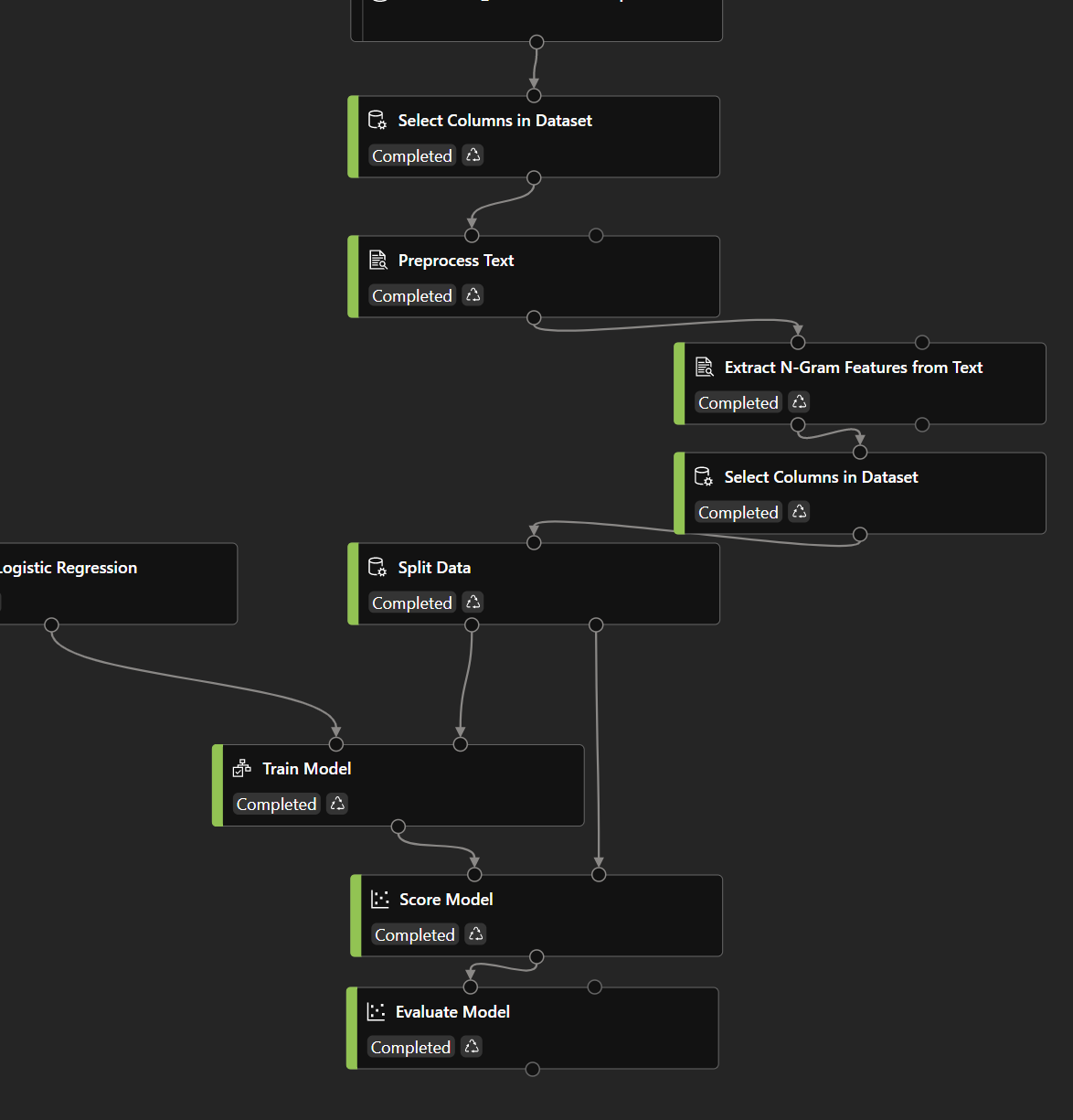
But I don't know how to achieve this.
Thanks in advance.

Once you create a real-time inference pipeline, please make the further modifications below:


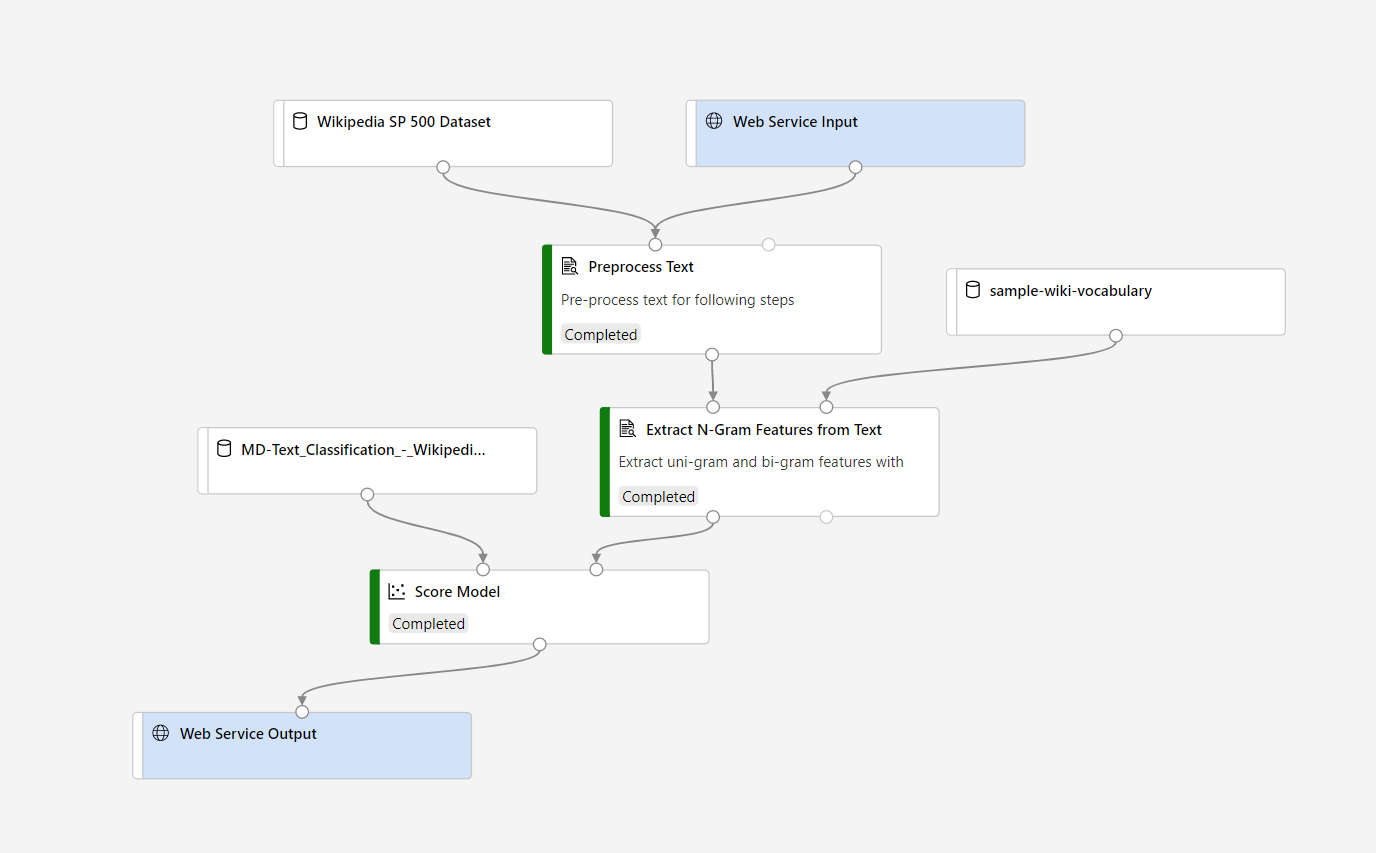
We will improve the documentation accordingly. Thanks for reporting the issue!
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EVS%3C/text%3E%3C/svg%3E)
Hi @Lu Zhang (MSFT) do not see Output datasets to select for registering them. How should I proceed? I have also attached screenshot.

Input datasets
None
Output datasets
None