Azure Data Factory
An Azure service for ingesting, preparing, and transforming data at scale.
11,623 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3ESD%3C/text%3E%3C/svg%3E)
Help Needed ! Increase speed of data transfer between Oracle database on AWS to Azure data lake server ADLS We have an Oracle database hosted in AWS private cloud with large amount of data. We need to transfer the data from the database to the Azure data lake storage ADLS in the azure cloud. We have a 1 Gbps virtual network gateway connecting the 2 cloud environments. We are using ADF pipelines to transfer the data from source to sink. The speed we are getting for data transfer is between 400KBps - 5 MBps which is low considering the 1Gbps connection. We need to increase the data transfer speed to shorten the time taken for data transfer.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EMM%3C/text%3E%3C/svg%3E)
Hello @Sabyasachi Dash and welcome to Microsoft Q&A.
There are a number of things that can be done to increase throughput. In your case, I suspect it is caused by a low degree of parallelism (1) and/or not using partitioned copy.
I am not overly familiar with the AWS ecosystem, but it sounds like you have an established connection, and so are using Azure Integration Runtime, rather than a Self-Hosted Integration Runtime. Please correct me if this is not the case.
If you are using Self-Hosted Integration Runtime, then you could try adding more nodes and/or scaling up the nodes, in addition to the following recommendations.
There are optimizations which are specific to Oracle, and there are generic optimizations. There is some interplay between them.
First, the generic optimizations. In the Copy Activity > Settings you can find Data Integration Units and Degree of copy parallelism. The Data Integration Units are a measure of how much "power" is assigned to the task. The Degree of copy parallelism is how many processes are available to read/write simultaneously. More is better.
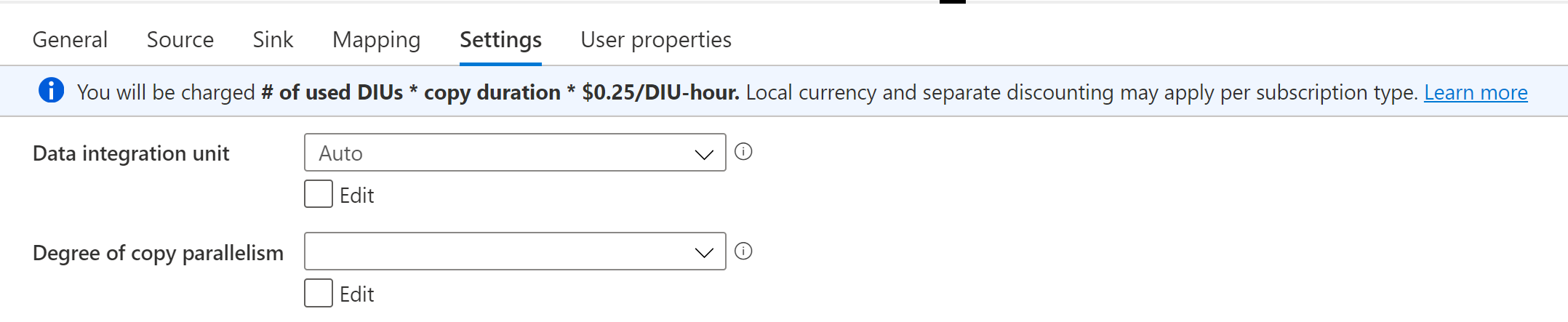
In the Copy Data > Sink (for both Azure Data Lake Gen 1 and Gen 2), there is Max Concurrent connections. Max concurrent connections is how many simultaneous writers you will allow. More is better, but the default value is 'no limit'.
Depending upon the type of dataset, more options may be available (i.e. delimited text vs binary).
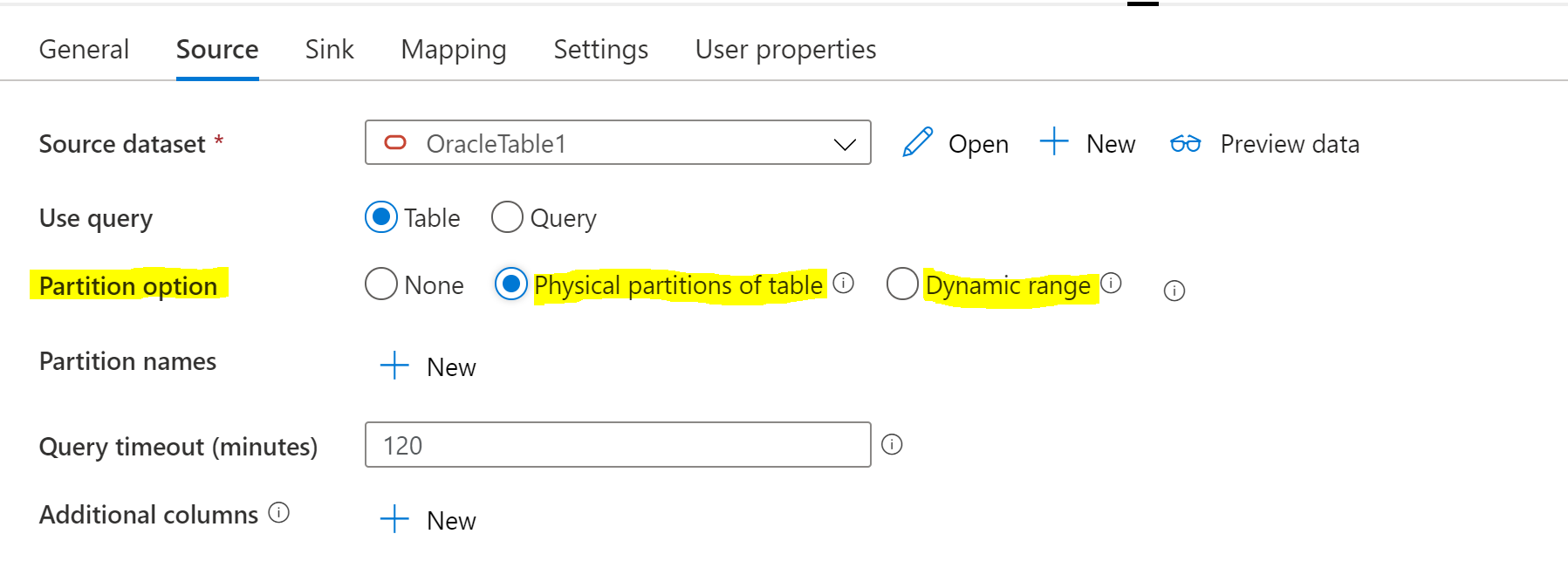
For the optimizations specific to Oracle, there is Partition Options. If you are currently using None, this would explain the low throughput. Whether you should select Physical partitions of table or Dynamic range depends on the particulars of your situation. Please see the article Parallel Copy from Oracle for details on determining which is right for you. The article also explains how the aforementioned Degree of parallelism interacts with the Partition options.
Please let me know if this helps you at all. Thank you for your patience.
Martin
Hey @MartinJaffer-MSFT ,
When we see the statistics for copy activity, it is clearly visible that reading from source is the time consuming one. For 50 Gb of oracle source data with 1.1 mbps speed it is taking around 14 hours.
Our goal is to increase throughput for a single copy activity to 30+ MBPS so that we can copy huge amount of data within stipulated timeframe.
Thank you for sharing the details and findings @Sabyasachi Dash . This has helped shape my understanding.
There is one more thing to try. In the Copy activity settings, enable staged copy. Specify a staging storage account different from your destination storage account.
Beyond this, a deeper investigation is needed. For a deeper investigation, some sensitive information is needed. More about this in next post.