Azure Data Factory
An Azure service for ingesting, preparing, and transforming data at scale.
11,623 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EKK%3C/text%3E%3C/svg%3E)
Data Flow is not able to read the API response json file stored in blob storage, if the file is manually placed in the same location it works fine, but for the json api response dataflow says corrupted file? In dataset I'm able to preview the file but in data flow it doesn't work.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EMM%3C/text%3E%3C/svg%3E)
@Kunal Kumar Sinha I remember originally you mentioned corrupted file, are you sure it wasn't corrupted record?
If in the Dataflow source data preview, you see a column _corrupt_record like this...
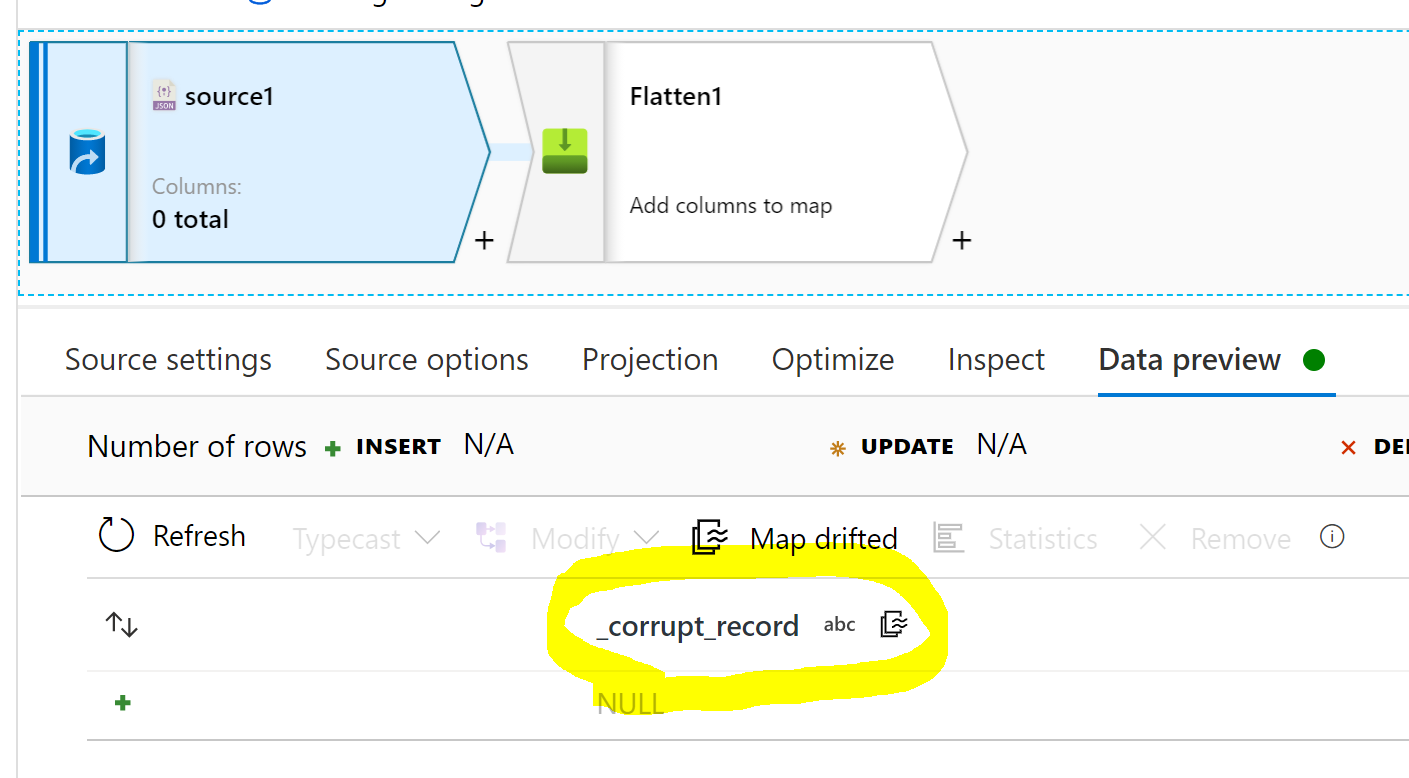
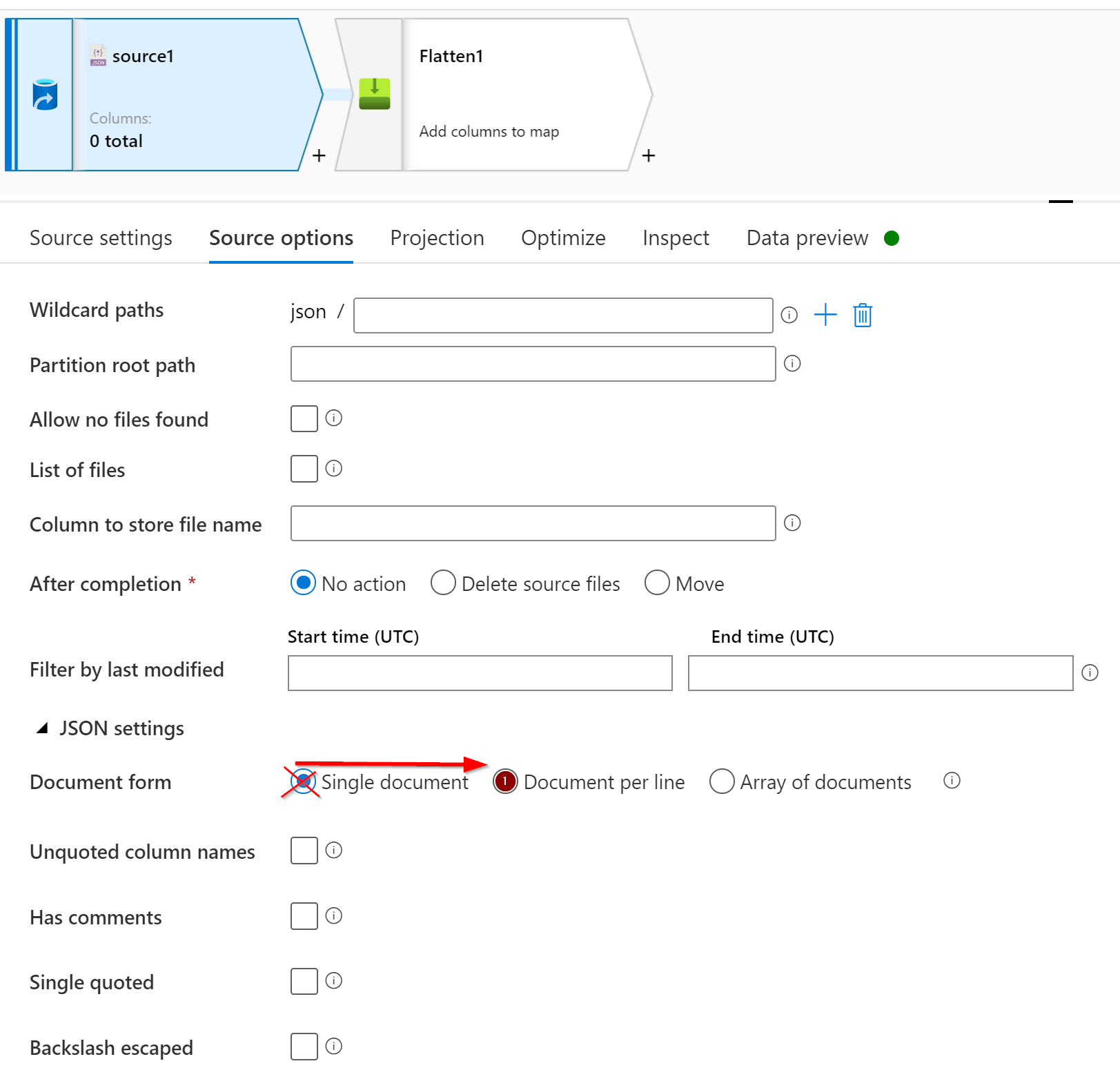
then you need to go to source options and change the JSON settings from single document to Document per line
Great! I'm glad this helped. Have a great week Hunal!
Hello @Kunal Kumar Sinha and thank you for bringing this to our attention.
If I understand correctly, you have the same file/data written to blob storage by two different mechanisms, after which Mapping Data Flow cannot read one of them.
In the happy case you made a call to some API, and then manually uploaded the blob.
In the other case some service called the same API and got same response, and wrote to blob.
First, can you compare the file sizes or MD5s? Or do a diff on them to find the difference?
Also share a few properties of the blobs, specifically the blob type and content-type
Second, can you share what service is writing the bad blob?

Hello @MartinJaffer-MSFT ,
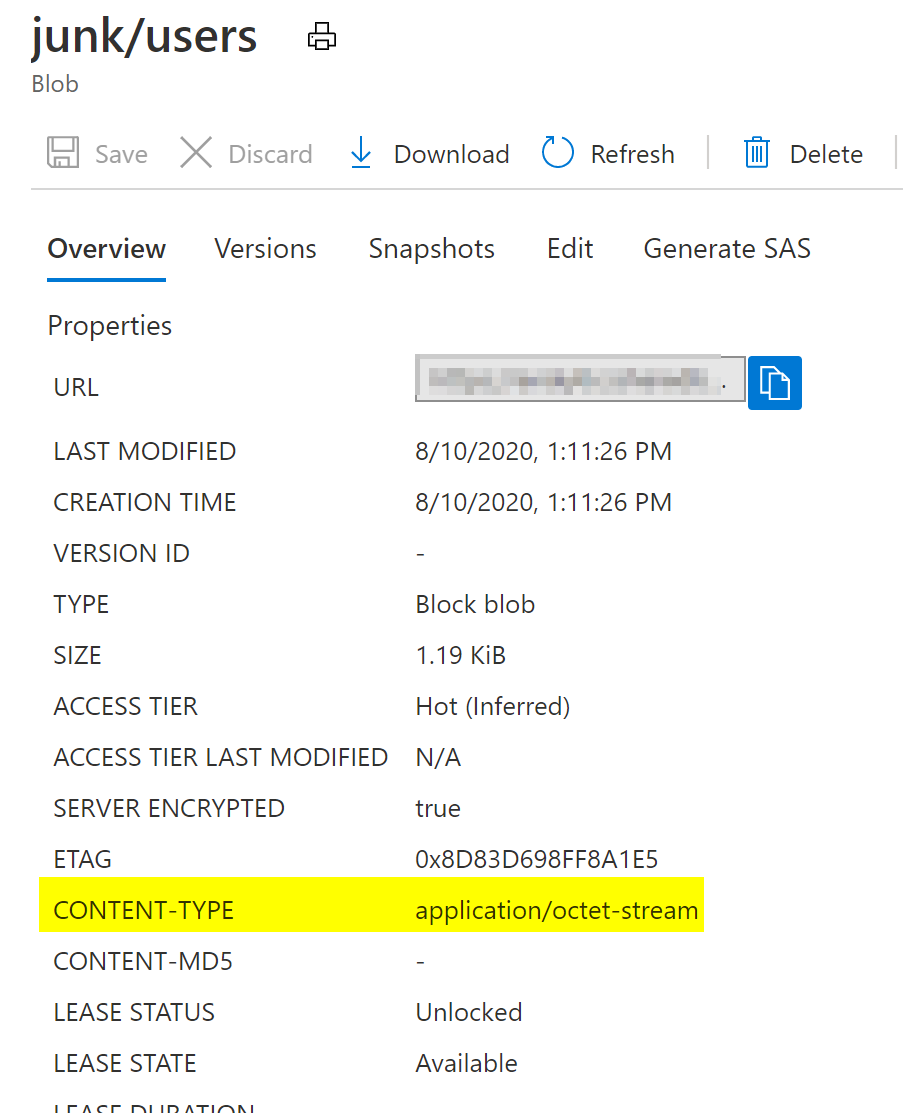
Yes you are right, the content type of the file captured through ADF is application/octet-stream while the same response manually uploaded to blob is application/json, dataflow is not able to read the file with content type octet-stream while it reads json type.
Thanks,
Kunal
@Kunal Kumar Sinha I see in the pictures, the blobs have different size, by more than a few bytes. This means the contents are different. This is not just a lable difference.
@MartinJaffer-MSFT , yes you are right the files were different I cross checked, that's why the size difference is there. But the API response file has content type application/octet-stream and dataflow is not able to preview the data , but for file having content type as application/json it previews the data , why is that ? can you please help me understand this ?
Thanks,
Kunal
@Kunal Kumar Sinha
As a test, I located a blob whose content-type is application/octect-stream and text appears to be json, and created a new dataflow and dataset pointing to it. No schema was imported to either dataset or dataflow. All other settings left as default.
The data was taken from public source reqres.in .
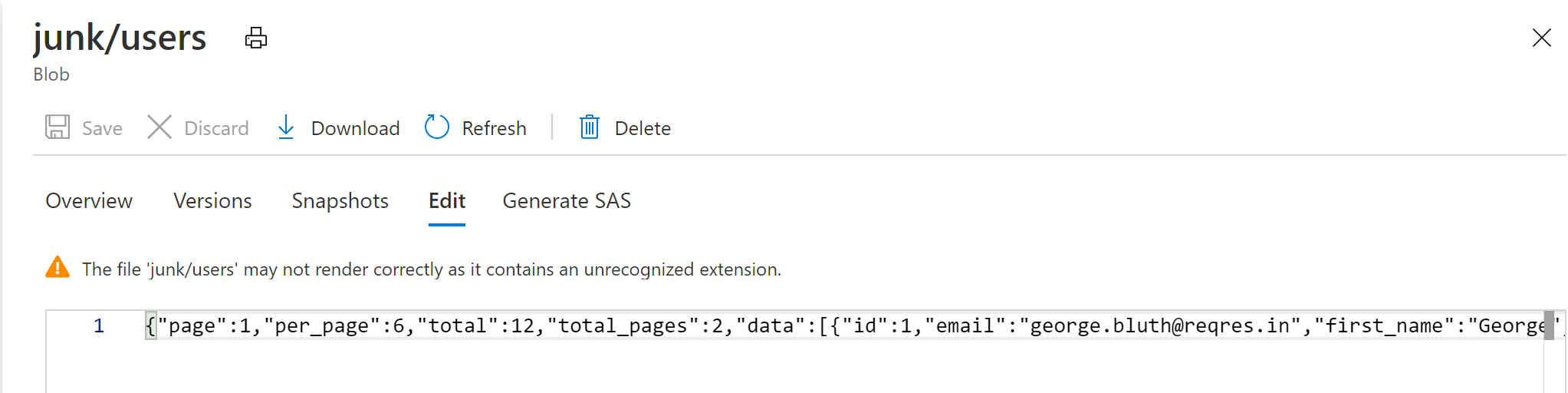
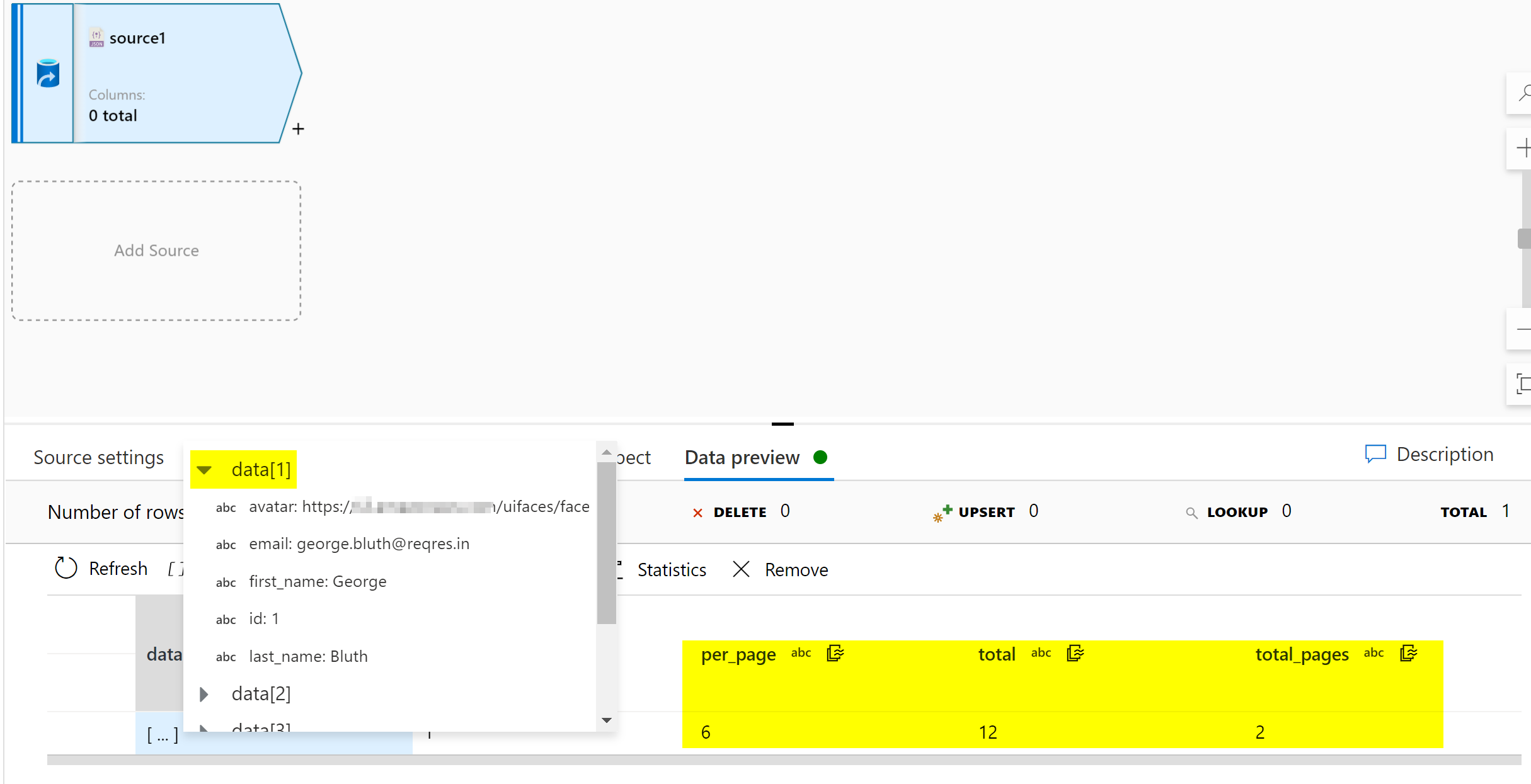
As you can see in the above image, I was able to preview the data in the source transformation in Data Flow.
This suggests the cause is not the content-type , but instead an issue in your data. Please visually inspect you data.
Hi @MartinJaffer-MSFT ,
Yes you were right, can you please help me understand why the API response JSON file I'm not able to read in dataflow as i can visualize the JSON data here - http://jsonviewer.stack.hu/ and the response seems to be valid. I'm attaching a sample json response in txt format for more details. Any help will be great !
Thanks,
Kunal
In the Data Flow preview, if you get a message sayings results has incompatible types like in below image
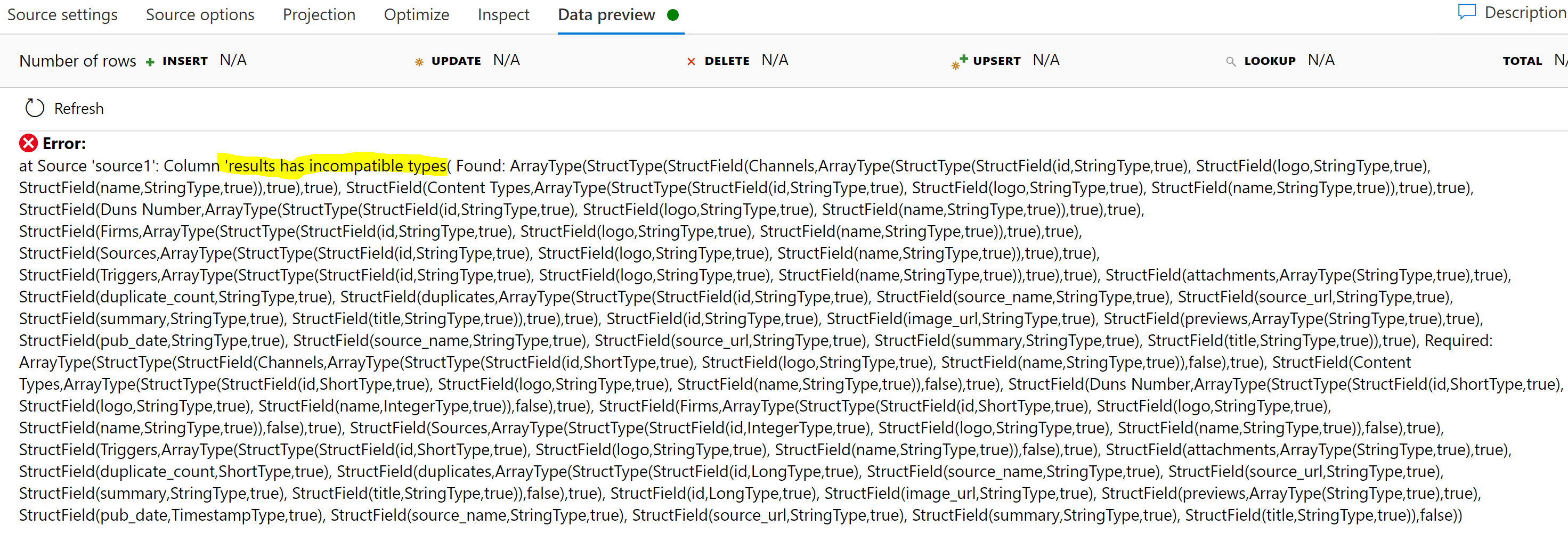
I have determined that to be rooted in how Data Flow guesses the schema. It looked at the first X records, and found they were all empty arrays, so it guessed it was an array of string. There are a few ways to fix this. The shortest is to go to source settings and enable Infer drifted column types, then goto Projection and import the projection again. You can also disable Validate schema in the source settings.
Another way to more regorously fix it, is to go to the dataset and import schema from a file. The file should be an example which has all fields filled out, no incomplete objects or empty arrays.