Azure Synapse Analytics
An Azure analytics service that brings together data integration, enterprise data warehousing, and big data analytics. Previously known as Azure SQL Data Warehouse.
5,004 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3ES%3C/text%3E%3C/svg%3E)
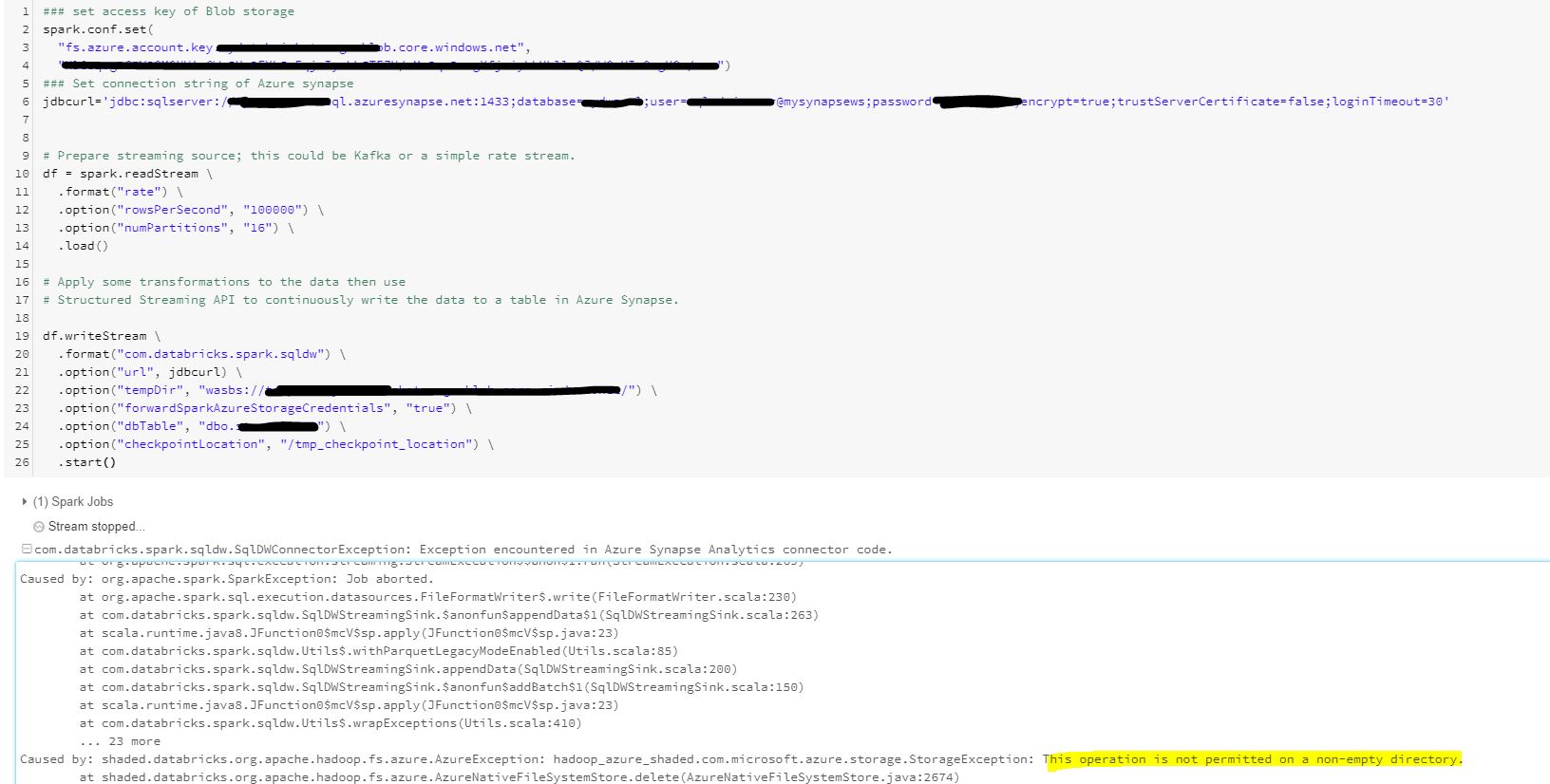
I am having an issue on writing stream to Azure synapse with the following error .
let's have a look and see if there is idea ?

Hello @sakuraime ,
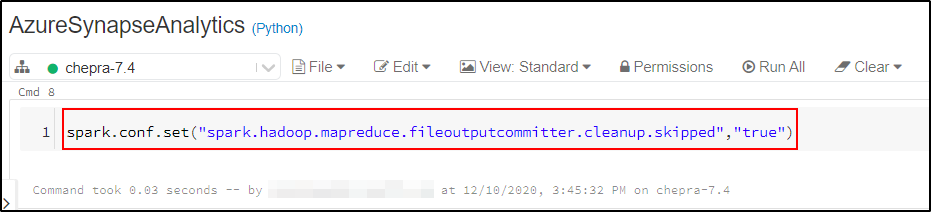
You can resolve this issue by using the below configuration:
spark.conf.set("spark.hadoop.mapreduce.fileoutputcommitter.cleanup.skipped","true")
For “tempDir”, we recommend you use a dedicated Blob storage container for the Azure Synapse Analytics SQL pools.
Here is the python example of structured streaming:
# Set up the Blob storage account access key in the notebook session conf.
spark.conf.set(
"fs.azure.account.key.<your-storage-account-name>.blob.core.windows.net",
"<your-storage-account-access-key>")
# Prepare streaming source; this could be Kafka or a simple rate stream.
df = spark.readStream \
.format("rate") \
.option("rowsPerSecond", "100000") \
.option("numPartitions", "16") \
.load()
# Apply some transformations to the data then use
# Structured Streaming API to continuously write the data to a table in Azure Synapse.
df.writeStream \
.format("com.databricks.spark.sqldw") \
.option("url", "jdbc:sqlserver://<the-rest-of-the-connection-string>") \
.option("tempDir", "wasbs://<your-container-name>@<your-storage-account-name>.blob.core.windows.net/<your-directory-name>") \
.option("forwardSparkAzureStorageCredentials", "true") \
.option("dbTable", "<your-table-name>") \
.option("checkpointLocation", "/tmp_checkpoint_location") \
.start()
The output of the Notebook:
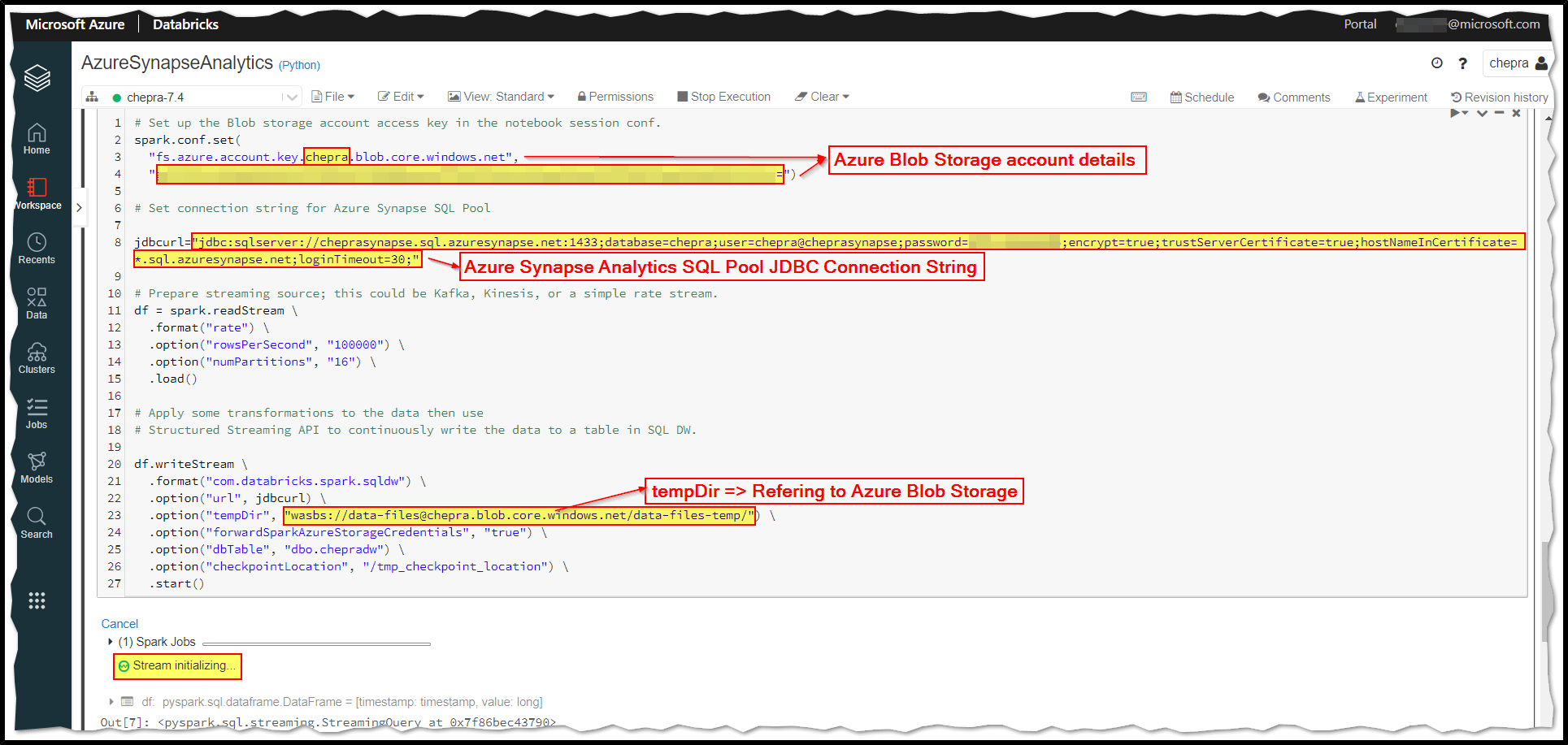
Reference: Azure Databricks - Azure Synapse Analytics - Usage (Streaming).
Hope this helps. Do let us know if you any further queries.
------------
Hello @sakuraime ,
Just checking in to see if the above answer helped. If this answers your query, do click “Accept Answer” and Up-Vote for the same. And, if you have any further query do let us know.
cool, let me have a check later thanks
Hello @sakuraime ,
Following up to see if the above suggestion was helpful. And, if you have any further query do let us know.
Take care & stay safe!