Azure Data Factory
An Azure service for ingesting, preparing, and transforming data at scale.
10,199 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EGS%3C/text%3E%3C/svg%3E)
Hi ,
I am copying data from on prem db to azure blob storage using ADF copy.
But few of the on prem tables are having huge data like 1 trillion rows.
Can you please advice the best way to approach for this amount of data ?
Kind Regards,
Gowri Shankar
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EMM%3C/text%3E%3C/svg%3E)
Hello @Gowri Shankar and welcome back to Microsoft Q&A. Thank you for your question.
My understanding is that you would like to copy a trillion row table to blob. You want performance suggestions.
The specific options available may vary by type of database, and how your table is set up. Can you please share what type of on prem db you are using (SQL, MySQL, Oracle, etc.)?
Thanks for your reply . My onprem db is Netezza.
Thank you for clarifying the database type, @Gowri Shankar .
There is a tutorial specifically for Netezza migration. This tutorial includes many performance tips. While this tutorial eventually targets Synapse, it also works for blob. There is a section I would like to call out explicitly:
For larger tables (that is, tables with a volume of 100 GB or greater or that can't be migrated to Azure within two hours), we recommend that you partition the data by custom query and then make each copy-job copy one partition at a time. For better throughput, you can run multiple Azure Data Factory copy jobs concurrently. For each copy-job target of loading one partition by custom query, you can increase throughput by enabling parallelism via either data slice or dynamic range
I meant to post the below yesterday, but my message got eaten.
I do have some recommendations that are database agnostic.
First I would like to suggest partitioning your data. Given that it takes a long time to read all of a 1 trillion row table, it will also take a long time to read all of a 1 trillion row blob. If you have any plans to use this blob downstream, breaking this 1 blob up into many smaller blobs can help later services with ingestion speed.
One way to do this when you do not have partitions on source, is to use the Max rows per file feature in the copy activity sink. This works for delimited text dataset, when no filename is specified in the dataset. We can use the File name prefix feature to give it a custom name.
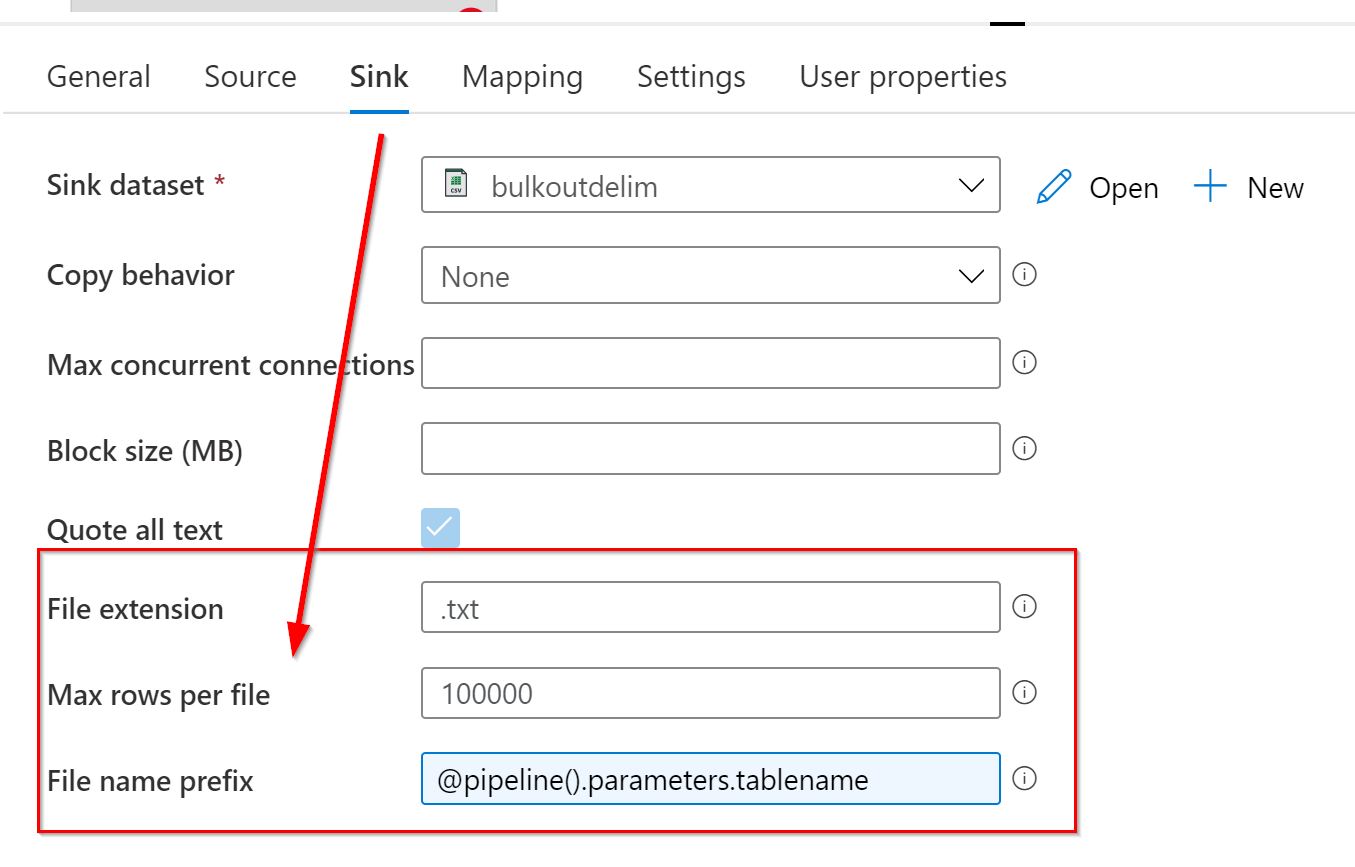
If you do have partitions on source, target your queries or other options to use those instead.
Since your database is on-prem, it is probably in its own network behind a firewall, and not accessible to Azure directly. This means you would be using a Self-Hosted Integration Runtime (SHIR). Since the job is so big, scaling out the SHIR might be helpful. Scaling out consists of installing the same SHIR on multiple machines and registering with the same key. Each "node" increases the available parallelism by 4 or 5. The SHIR can be very resource-hungry, so decent hardware helps.
Parallelism is important. With too little parallelism, you are left with idle I/O on the database, and the copy takes a long time. With too much parallelism, threads are competing for I/O to the database , outgoing bandwidth, or other resources. This competition ends up slowing down the overall process and it takes too long.