Azure Data Factory
An Azure service for ingesting, preparing, and transforming data at scale.
10,196 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EAY%3C/text%3E%3C/svg%3E)
Hi,
I am beginner and learning Data factory.
I am doing below requirement.
---a Table is having data like Bird name and Bird Type ( Mourning Dove , Dove).
--- Want to generate flat files as per Bird types dynamically.
1) used lookup on table to fetch distinct Bird Type and keeping in array variable
2) For each loop will read the array values in loop and this array value has to be passed to generate through query in "copy data" and with same above table as source.
3) Can some one suggest how can i use value getting into append variable during iteration in SQL query for generating flat file.
Not able to use append variable in Use query of source (copy data) through For each loop

Hi @abhilash yadav ,
Thank you for asking this question. In my opinion, the solution you want to achieve in the pipeline using CopyActivity would be too much expensive as too many Activities (i.e., CopyActivities and other Activities) will run just for a single pipeline run. You can achieve the same output in a way more simpler and cleaner way by using DataFlow.
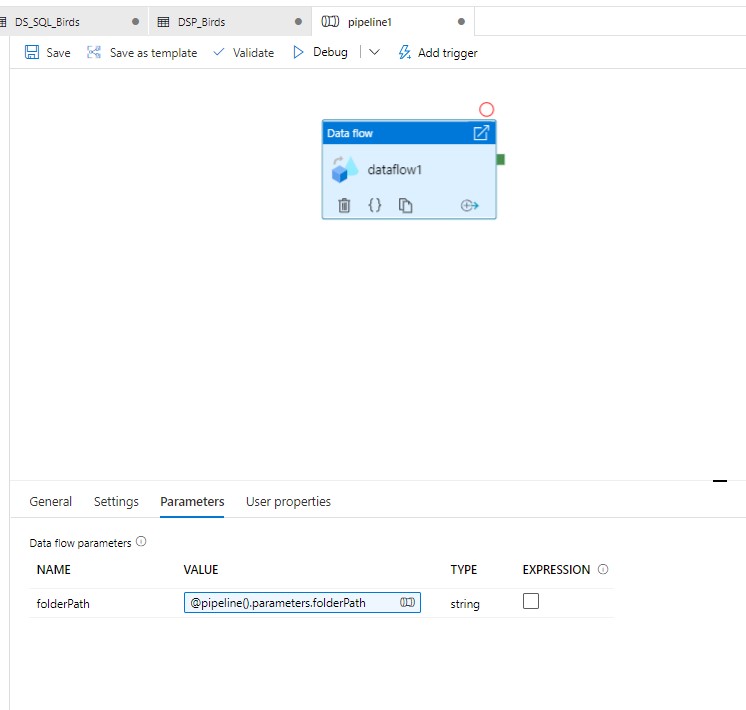
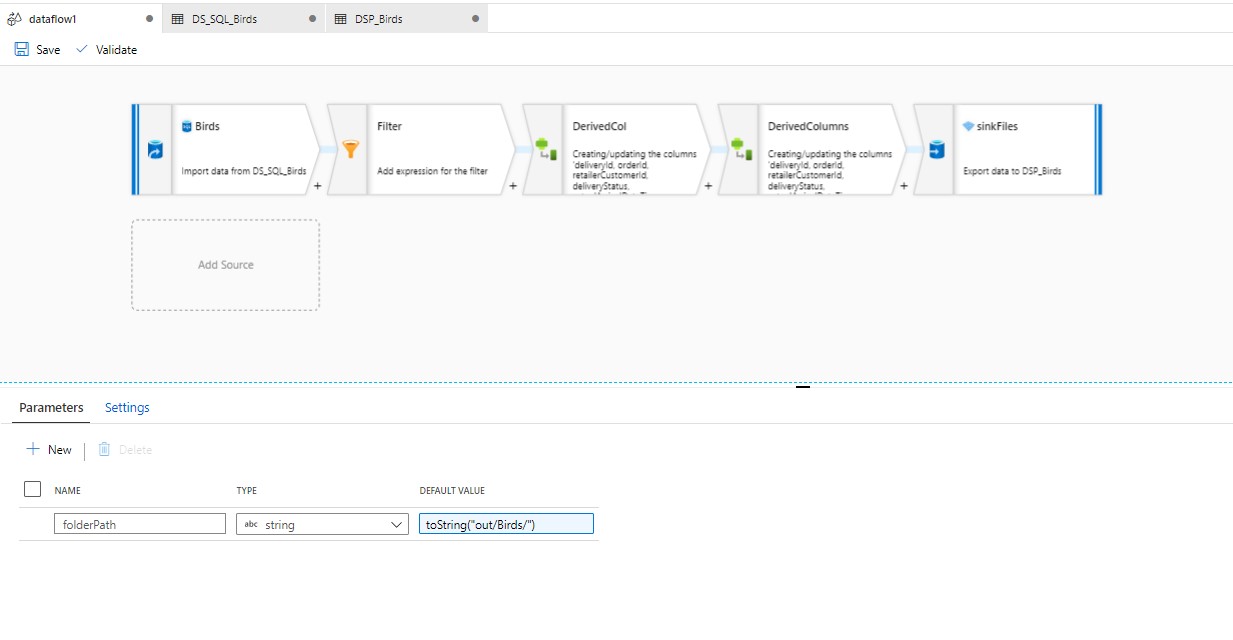
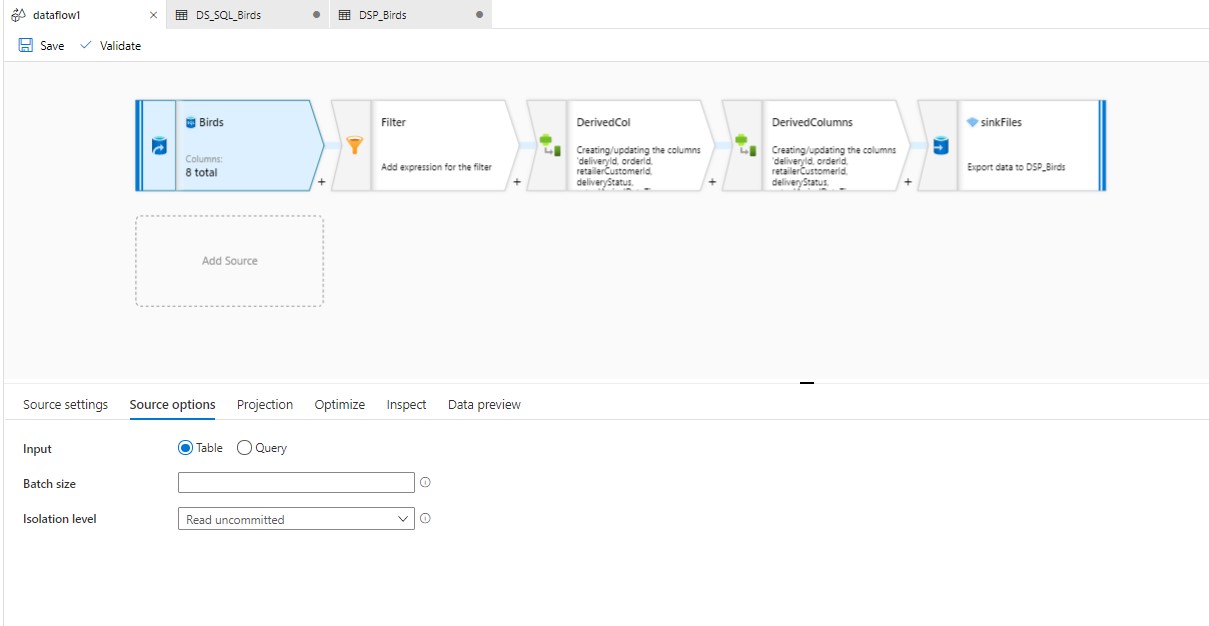
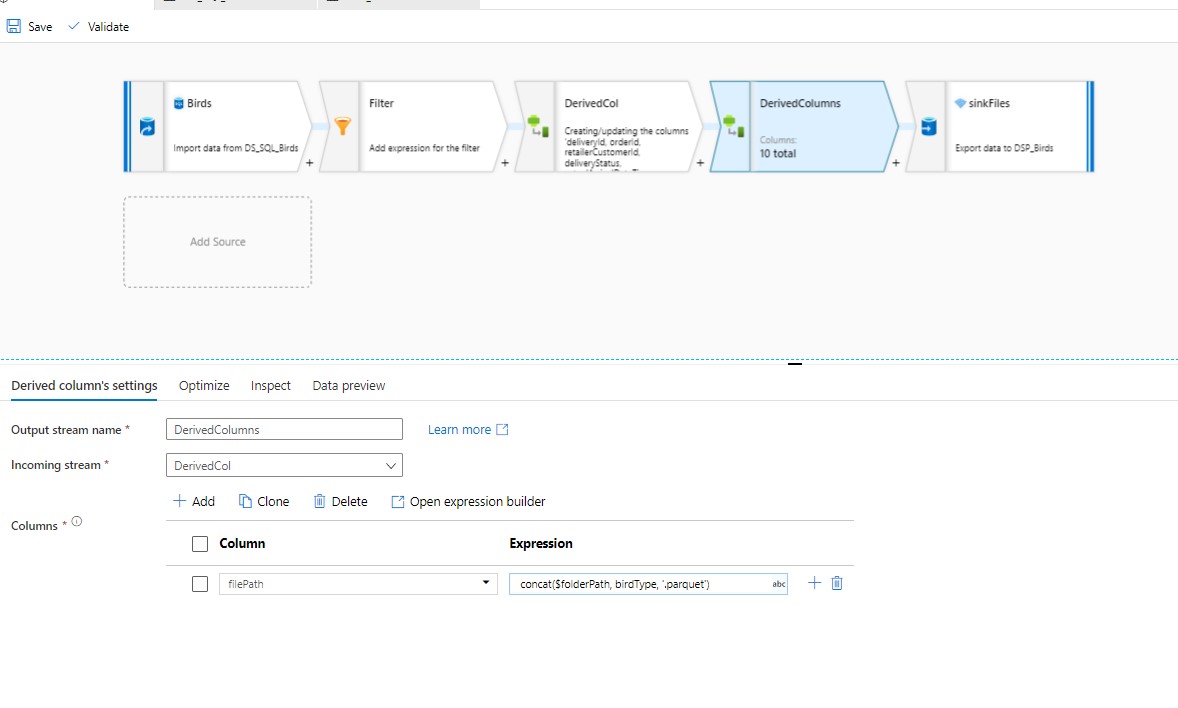
The steps you have to do are:
That's all. All the data with the same filePath, will be written in that specific file. You will get all the files in the folderPath you mentioned in the pipeline.
Please see screenshots attached and let me know if you have any questions. If the above response helped, please "accept as answer" and "up-vote" the same! Thanks!
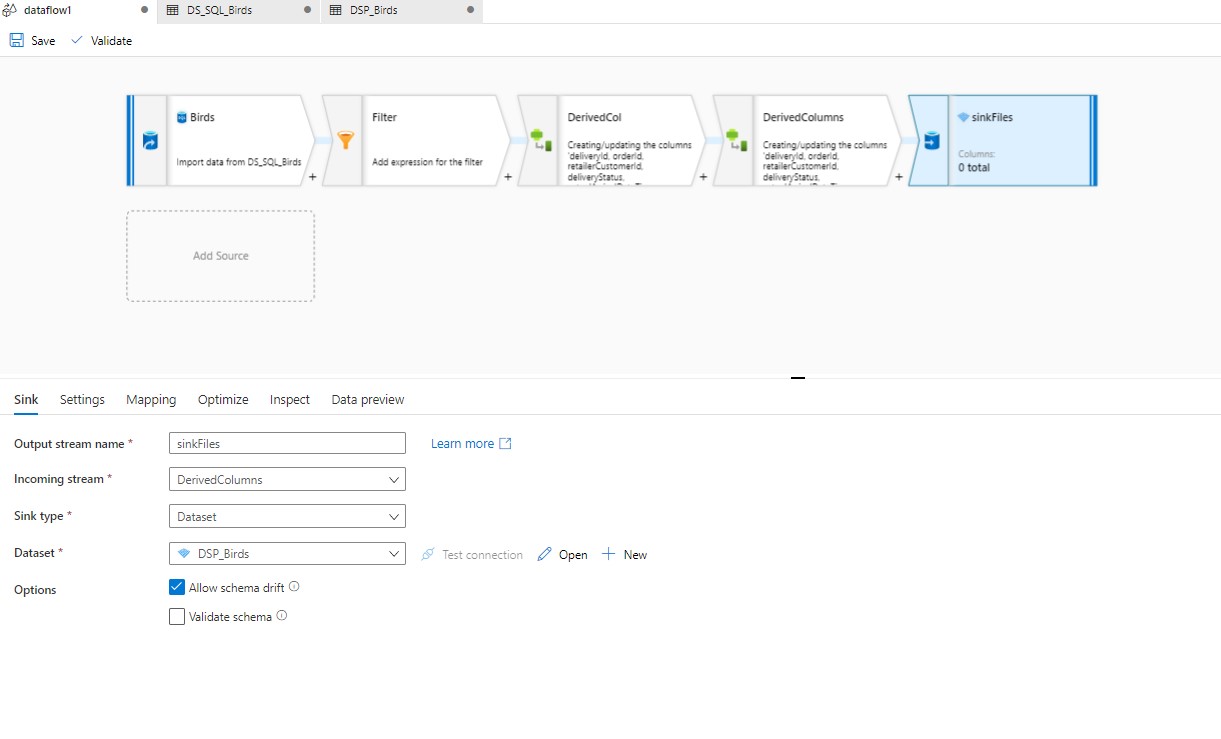
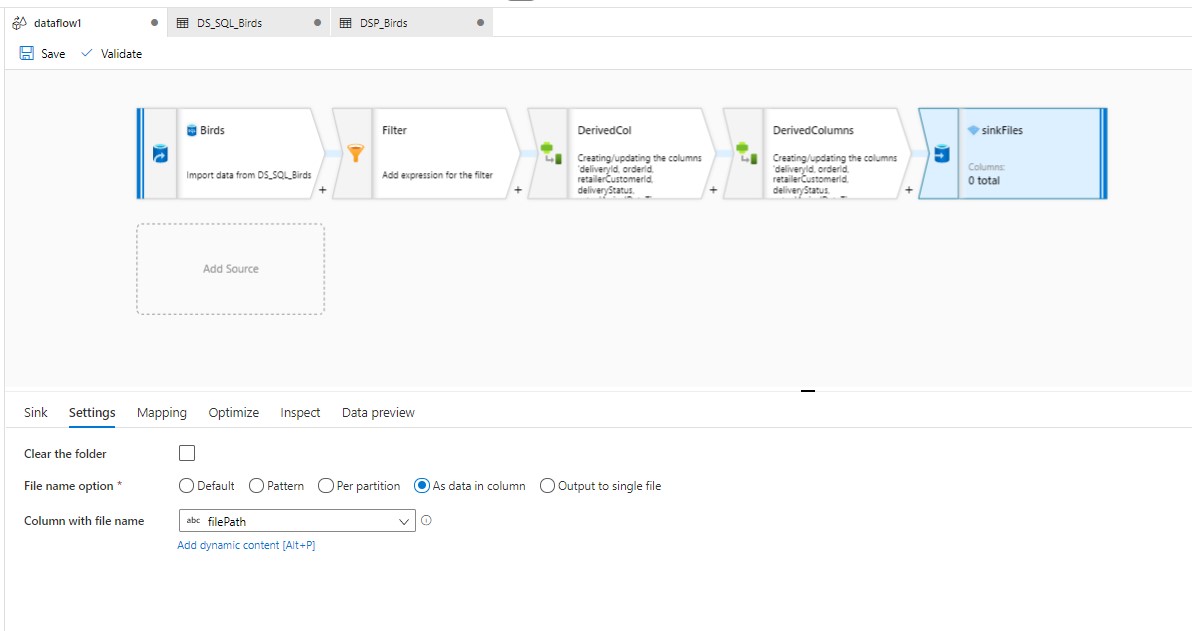
Hi Nasreen, Thanks alot for solution and post. i need to try your dataflow.
Apart from solution, i would like to know how can append variable value to be used in use query.
in my pipeline, append variable is getting value for each iteration as expected. in Dynamic content , this append variable not visible.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EHM%3C/text%3E%3C/svg%3E)
Hi @abhilash yadav ,
Welcome to Microsoft Q&A Platform. Thanks for posting the query.
When you say append variable, please suggest if you are referring to array variables. I would recommend you to use @item() variables inside foreach loop that are iteration session variables and can be used in all expressions. Example, in your case, the query can be written in copy activity using @item() variables as below

Copy activity source query: In this example, type is the column name coming from source table
@concat('select spname,type from controltable where type=''',item().type,'''')
Array variables can be used in copy activity by passing the index value to it and for looping, we can use them directly.
Please let us know if these details help or for further queries and we will be glad to assist.
Hi @abhilash yadav ,
We have not received a response from you. Please suggest if above suggested details are helpful. Otherwise, let us know and we will continue to engage with you on the query.
Please do consider to click on "Accept Answer" and "Up-vote" on the post that helps you, as it can be beneficial to other community members.
Hi @abhilash yadav ,
We still have not heard back from you. Following up to check if above suggested details are helpful. Otherwise, let us know and we will continue to engage with you on the query.
Please do consider to click on "Accept Answer" and "Up-vote" on the post that helps you, as it can be beneficial to other community members.