Community Center | Not monitored
Tag not monitored by Microsoft.
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EJN%3C/text%3E%3C/svg%3E)
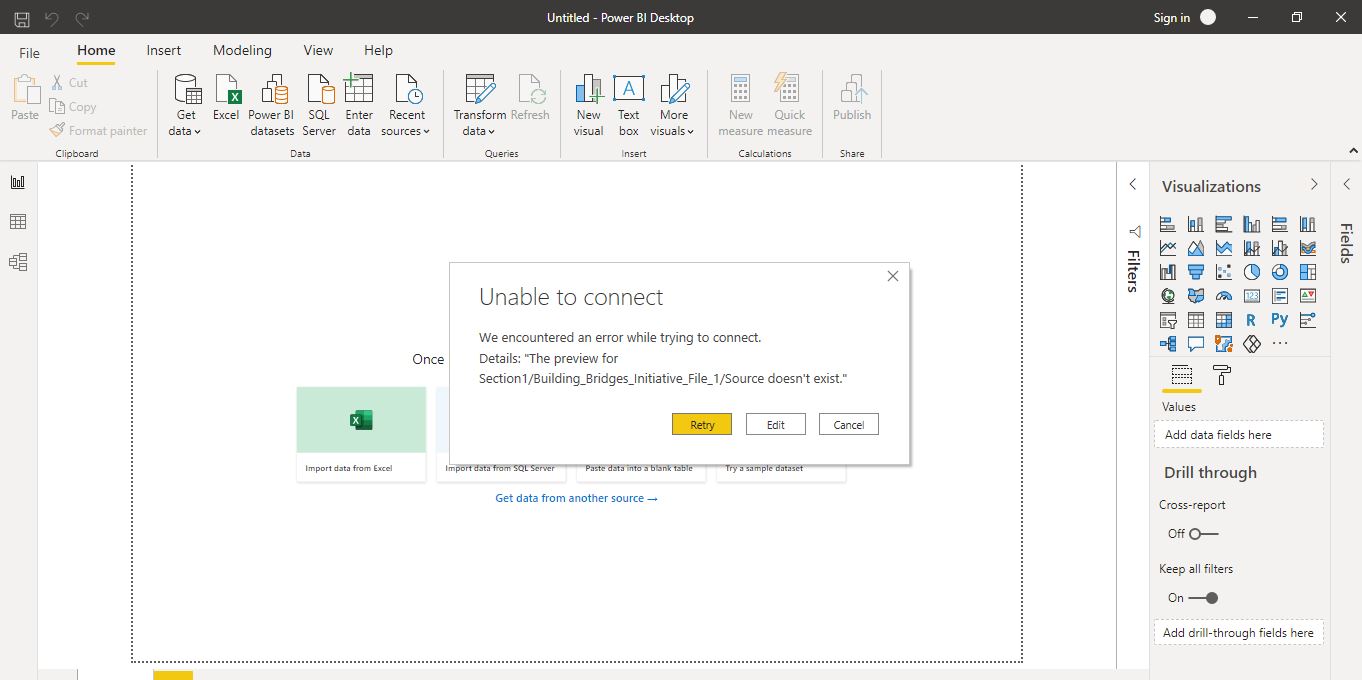
I have a pdf file relating to data i want to extract into excel using Power Query and perform some analysis. I have tried to use Power Query from native excel and Power BI and am getting the same Error captioned image attached. Kindly note the files are downloaded and saved in my desktop despite the Error caption attached stating the source does not exist.
The file path is located in the website link as text 👉 (https://www.iebc.or.ke/election/?Building_Bridges_Initiative)
Building_Bridges_Initiative_File_1
Building_Bridges_Initiative_File_2
If there is anyone with a solution as to why am getting errors can share a work around on how to extract the data from the PDF. Thanks
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EEM%3C/text%3E%3C/svg%3E)
We'll take a look at this. In the meantime, can you try creating a blank query and entering the following?
= Pdf.Tables(File.Contents("c:\the file name.pdf"))
Wow, these PDF files are huge (around 15k pages)! The error is unrelated to PDF per se, but is likely a side effect of the PDF query taking up a lot of memory, due to the large size. Here are a couple suggestions:
= Table.Combine(List.Skip(List.Generate(() => [Page=1, NavTable=null], each (if [NavTable] = null then true else Table.RowCount([NavTable]) > 0), each [Page=[Page]+1, NavTable=Pdf.Tables(File.Contents("C:\your_path_here\Building_Bridges_Initiative_File_1.pdf"), [StartPage=[Page], EndPage=[Page]])], each if [NavTable] is null then null else [NavTable]{[Id="Table001"]}[Data]), 1))