Azure SQL Database
An Azure relational database service.
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EA%3C/text%3E%3C/svg%3E)
Hello,
I am trying to use databricks (jdbc connector) to connect to an SQL database. I am getting the following error:
"com.microsoft.sqlserver.jdbc.SQLServerException: The TCP/IP connection to the host [REDACTED], port 1433 has failed. Error: "[REDACTED]. Verify the connection properties. Make sure that an instance of SQL Server is running on the host and accepting TCP/IP connections at the port. Make sure that TCP connections to the port are not blocked by a firewall."."
This is the code:
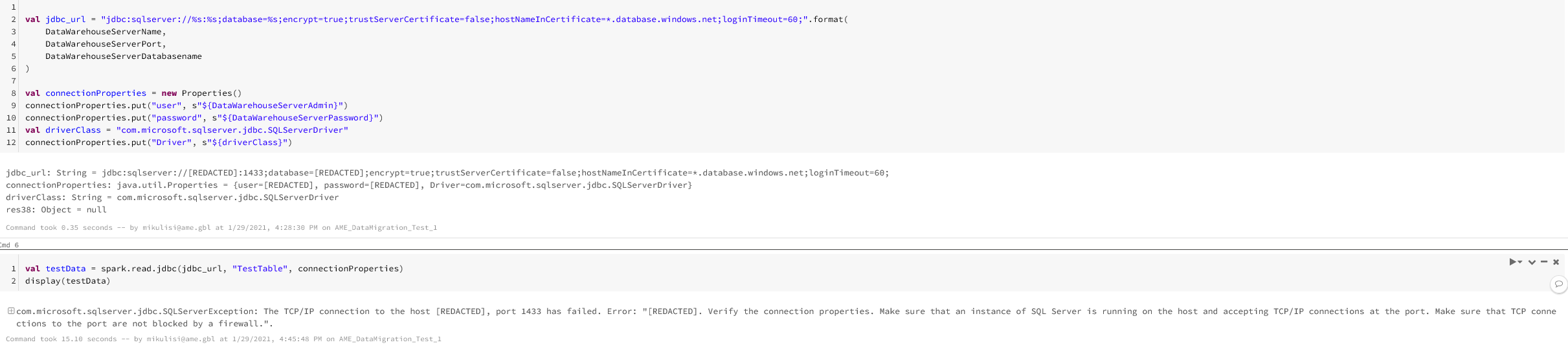
All the answers I've found so far tell me to use SQL management studio to properly configure the TCP port. This won't work for me as I need to automate this process. Currently I'm deploying the SQL server through a deployment template and using the az cli to configure the firewall (allow azure processes + databricks IP address)

Hello @Anonymous ,
If you have already configured your Azure SQL database to listen on TCP/IP traffic on port 1433 then it could be any of following three reasons:
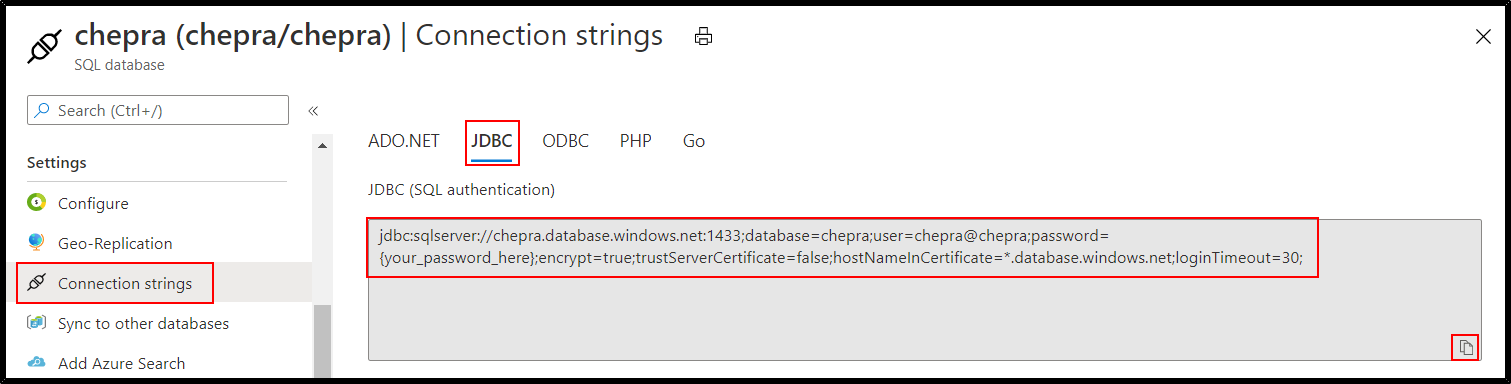
From Azure Portal get the Azure SQL Database JDBC connection string.
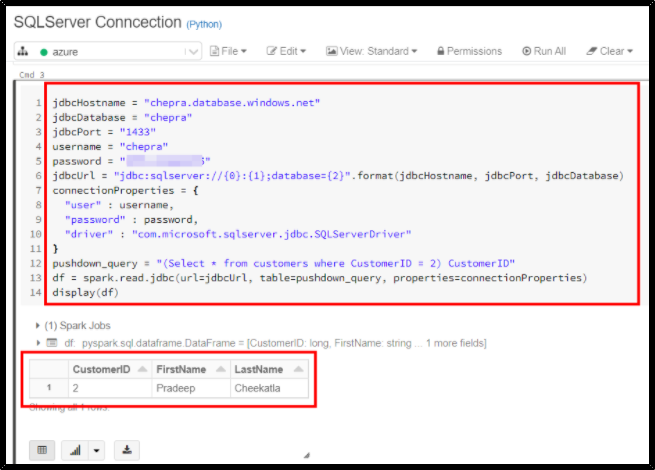
SQL Databases using JDBC using Python:
jdbcHostname = "chepra.database.windows.net"
jdbcDatabase = "chepra"
jdbcPort = "1433"
username = "chepra"
password = "XXXXXXXXXX"
jdbcUrl = "jdbc:sqlserver://{0}:{1};database={2}".format(jdbcHostname, jdbcPort, jdbcDatabase)
connectionProperties = {
"user" : username,
"password" : password,
"driver" : "com.microsoft.sqlserver.jdbc.SQLServerDriver"
}
pushdown_query = "(Select * from customers where CustomerID = 2) CustomerID"
df = spark.read.jdbc(url=jdbcUrl, table=pushdown_query, properties=connectionProperties)
display(df)
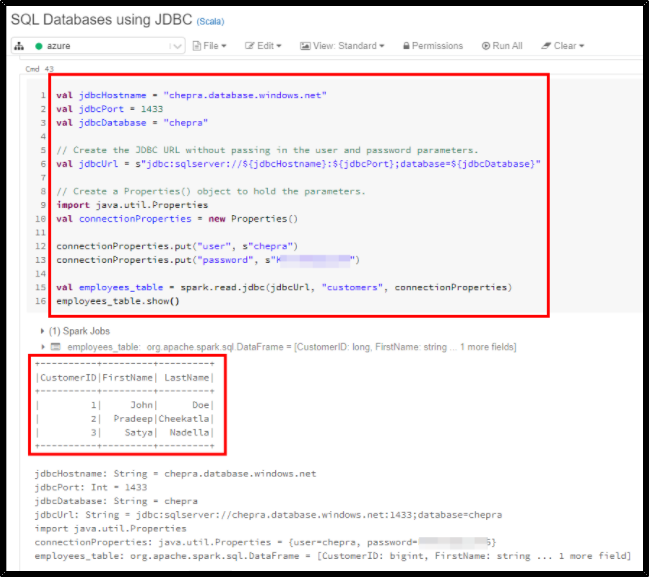
SQL Databases using JDBC using Scala:
val jdbcHostname = "chepra.database.windows.net"
val jdbcPort = 1433
val jdbcDatabase = "chepra"
// Create the JDBC URL without passing in the user and password parameters.
val jdbcUrl = s"jdbc:sqlserver://${jdbcHostname}:${jdbcPort};database=${jdbcDatabase}"
// Create a Properties() object to hold the parameters.
import java.util.Properties
val connectionProperties = new Properties()
connectionProperties.put("user", s"chepra")
connectionProperties.put("password", s"XXXXXXXXXX")
val employees_table = spark.read.jdbc(jdbcUrl, "customers", connectionProperties)
employees_table.show()
Hope this helps. Do let us know if you any further queries.
------------