Azure Data Factory
An Azure service for ingesting, preparing, and transforming data at scale.
10,199 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.

Hi,
I'm using mapping data flow and xml file as a source which is around 2.5 GB. While Importing projection in the source and executing the pipeline facing the below issue
Error:
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EKM%3C/text%3E%3C/svg%3E)
Hi @Vidyashree Salimath ,
Thanks for reaching out in Microsoft Q&A forum.
By looking at the error message it seems like issue is due to spark resources overloaded. I would recommend you to please try with bigger Integration runtime (more cores)
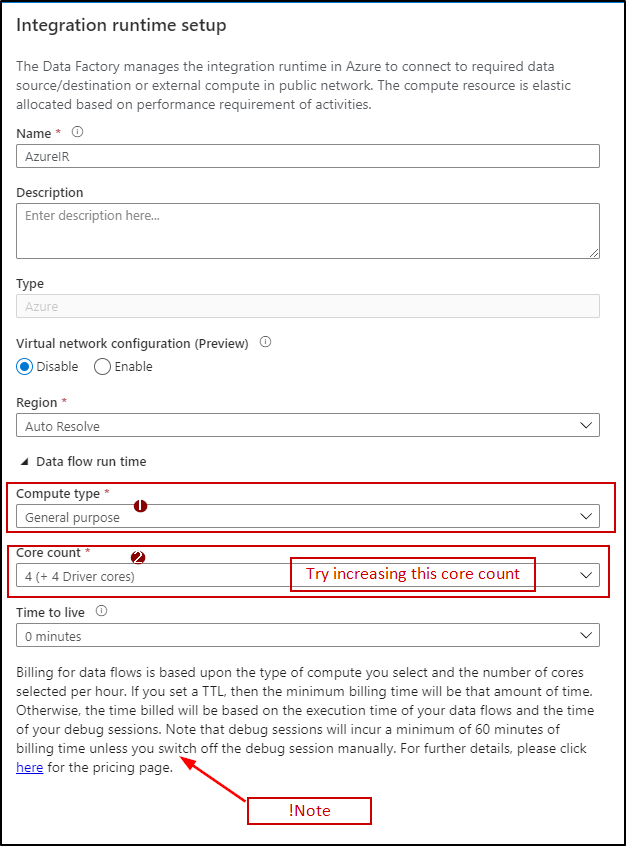
Please try with General Purpose compute type incase if you are using Memory optimized and also if you have configured some custom key partition in transformations, try defaulting to current partitioning so that spark can handle that optimization for you.
NOTE: Billing for data flows is based upon the type of compute you select and the number of cores selected per hour. If you set a TTL, then the minimum billing time will be that amount of time. Otherwise, the time billed will be based on the execution time of your data flows and the time of your debug sessions. Note that debug sessions will incur a minimum of 60 minutes of billing time unless you switch off the debug session manually. For further details, please click here for the pricing page.
In case if you still encounter the issue even after using bigger IR, please share below details for further investigation.
Hope the above info helps. Looking forward to your confirmation.
----------
Thank you
Please do consider to click on "Accept Answer" and "Upvote" on the post that helps you, as it can be beneficial to other community members.
Hi Kranthi,
Thanks for the Inputs, after increasing the core counts till 32 still issue persists. Below are the details
Looking forward for the support on this issue.
Hi @Vidyashree Salimath ,
Thanks for additional details. We will work with internal team to verify the logs and will get back to you as soon as we have an update.
Thank you for your patience.
Hi @Vidyashree Salimath ,
Following up to see if you have a got a chance to see my private message requesting to share few details over email for deeper analysis. Please do let me know here once the email is sent.
We look forward to your email.
Thank you
Hi @Vidyashree Salimath ,
We still have not heard back from you. Just wanted to check if you are you still facing the issue? In case If you already found a solution, would you please share it here with the community? Otherwise, let us know and we will continue to engage with you on the issue.
Thank you
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3ESK%3C/text%3E%3C/svg%3E)
Hi , I am facing the issue.
This issue is when I am running the pipeline from Synapse. I the dataflow , when I am trying to read data from change feed.
When I am running the full load , it is working. But when I choose to load for incremental load , it is giving below error.
Pipeline Id - 0b97ec95-15a8-4348-94e5-524802dc76b1
and DF run Id - ef6ffd02-ef05-4c3d-99d2-ac78a8dcfe52
Job failed due to reason: Job aborted due to stage failure: Task 0 in stage 12.0 failed 1 times, most recent failure: Lost task 0.0 in stage 12.0 (TID 12, vm-03612025, executor 1): java.io.FileNotFoundException: Operation failed: "The specified filesystem does not exist.", 404, HEAD, https://c4tpubdatalake.dfs.core.windows.net/c4tpubdatalakefs/?upn=false&action=getAccessControl&timeout=90 at org.apache.hadoop.fs.azurebfs.AzureBlobFileSystem.checkException(AzureBlobFileSystem.java:1071) at org.apache.hadoop.fs.azurebfs.AzureBlobFileSystem.create(AzureBlobFileSystem.java:189) at org.apache.hadoop.fs.FileSystem.create(FileSystem.java:1067) at org.apache.hadoop.fs.FileSystem.create(FileSystem.java:1048) at org.apache.hadoop.fs.FileSystem.create(FileSystem.java:937) at org.apache.hadoop.fs.FileSystem.create(FileSystem.java:925) at com.microsoft.azure.cosmosdb.spark.util.HdfsUtils$$anonfun$write$1.apply$mcV$sp(HdfsUtils.scala:50) at com.microsoft.azure.cosmosdb.spark.util.HdfsUtils$$anonfun$write$1.apply(Hd