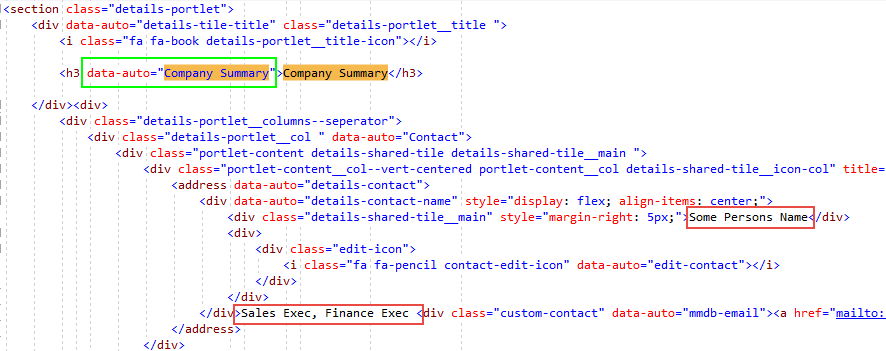
I'm not convinced that using the anchor element gains you anything. The relationship to the nodes you want is a simple child/sibling so you'd have to navigate a little. Assuming that this is not part of some page that has a bunch of this HTML on it then I think it is simply easier to query for the exact items you want. For purposes of an example I'm going to assume you already have a variable section that contains the node that is pointing to the root section item you posted. How you get to there is up to you.
var contactName = "";
var contactTitle = "";
//Find the contact information
var contactNode = section.SelectSingleNode("//address[@data-auto='details-contact']");
if (contactNode != null)
{
//Now find the contact name by looking for the class
// Approach 1 would be to use the class path //div[@class='details-shared-tile__main']
// Approach 2 is to get the contact-name element and work down, since we need this for the title
// anyway we'll go that route
var contactNameNode = contactNode.SelectSingleNode("//div[@data-auto='details-contact-name'][1]"); ;
if (contactNameNode != null)
{
contactName = contactNameNode?.InnerText?.Trim();
//Get the title which is a paragraph in the middle of the divs
//Could rely on the fact that it immediately follows the contact name section though
var titleNode = contactNameNode.NextSibling;
contactTitle = titleNode.InnerText?.Trim();
};
};
Note that you could convert this to a function to make it easier but ultimately this code is using what should be unique within the section to find things. This is heavily dependent upon the HTML being generated so if there are any changes then finding the data will have to change. To get the contact name we first find the contact div. We'll need this as it is the parent of all the data we want. To find the name we could either search for the CSS class or just assume the name is the first child div. I went the latter route as it is more reliable in this case given that the CSS class looks like it came from a master/detail webforms page and therefore may change. Once we have the name then the title (which is a paragraph in the middle of divs) is found by jumping to the next sibling.
This isn't guaranteed to work in all cases so some heuristics may need to be added to try to detect things if you don't find them initially but this should give you a good start.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EM%3C/text%3E%3C/svg%3E)


' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EKW%3C/text%3E%3C/svg%3E)
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EMT%3C/text%3E%3C/svg%3E)

