Azure Databricks
An Apache Spark-based analytics platform optimized for Azure.
2,091 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EAV%3C/text%3E%3C/svg%3E)
I'm reading the same CSV once in Scala with Spark and once in Python with Pandas, this is the code that I'm using:
val tabella = spark.read.option("header",true).option("mode", "DROPMALFORMED").csv("/FileStore/tables/IMMOBILI_MDRE_FACT_FENICE_INNER_DWH_CREDITI_2.csv") tabella = pd.read_csv("/dbfs/FileStore/tables/IMMOBILI_MDRE_FACT_FENICE_INNER_DWH_CREDITI_2.csv")
In both case when i count i find different rows

Hello @Auricchio Valerio ,
Welcome to the Microsoft Q&A platform.
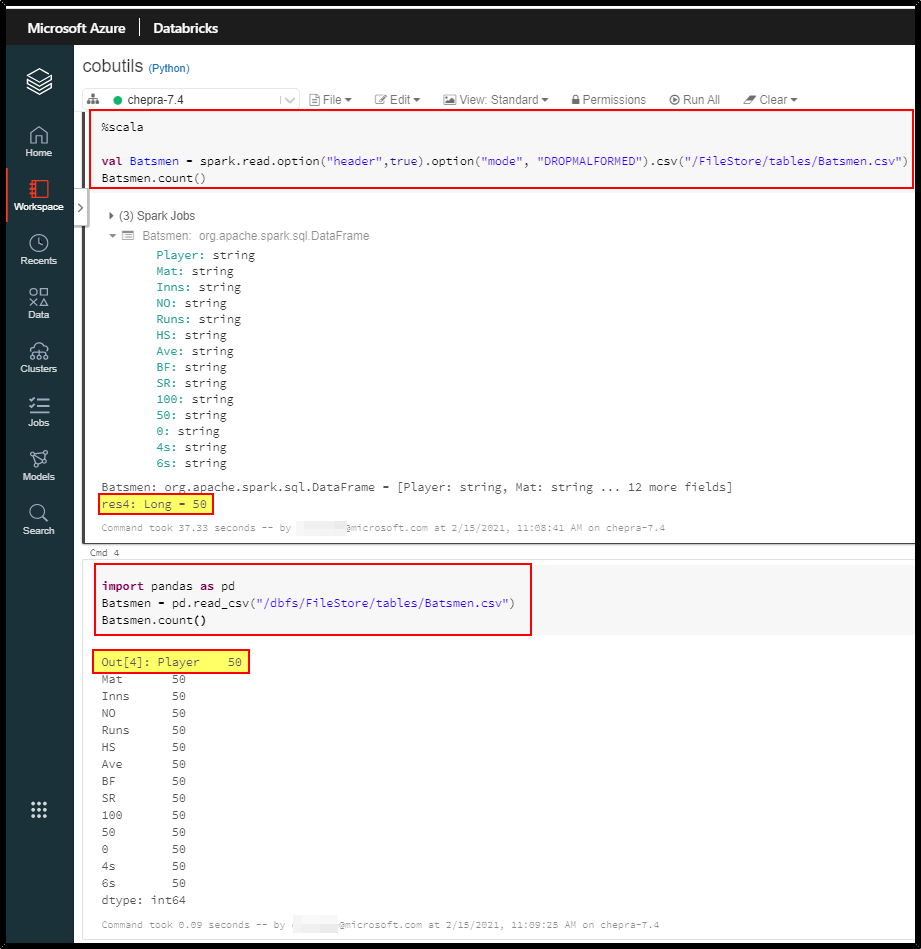
I had tested the same from our end, it results the same row count using Scala with Spark and once in Python with pandas.
Checkout the results:
Using dataframe.count:
Using display(dataframe):
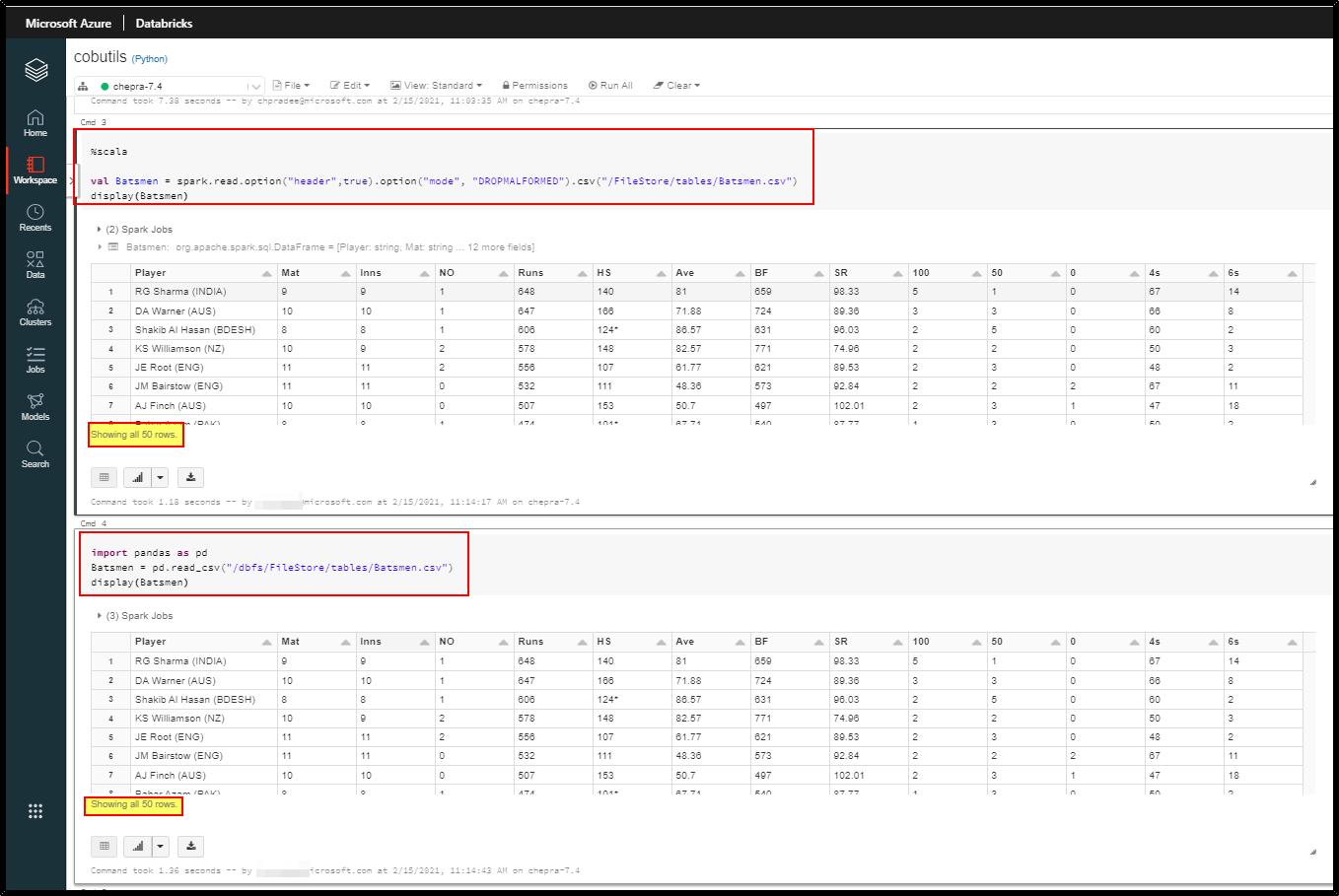
Hope this helps. Do let us know if you any further queries.
------------
Hello @Auricchio Valerio ,
Just checking in to see if the above answer helped. If this answers your query, do click Accept Answer and Up-Vote for the same. And, if you have any further query do let us know.
Hello @Auricchio Valerio ,
Following up to see if the above suggestion was helpful. And, if you have any further query do let us know.
Take care & stay safe!