{kind=link}
Computer Vision
An Azure artificial intelligence service that analyzes content in images and video.
415 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EO3%3C/text%3E%3C/svg%3E)
In the computer vision client there are 2 different ways to tag an image. --> computervision_client.tag_image_in_stream and ** computervision_client.describe_image_in_stream**
Code is as following
from azure.cognitiveservices.vision.computervision import ComputerVisionClient
from azure.cognitiveservices.vision.computervision.models import OperationStatusCodes
from azure.cognitiveservices.vision.computervision.models import VisualFeatureTypes
from msrest.authentication import CognitiveServicesCredentialsfrom array import array
import os
from PIL import Image
import sys
import time
subscription_key = "53f32bba50f1443cb9ae7e927441db83" #I randomized it
endpoint = "https://azurehackforaccessibility.cognitiveservices.azure.com/"
computervision_client = ComputerVisionClient(endpoint, CognitiveServicesCredentials(subscription_key))
local_image_path = "/Users/kunal/Documents/AzureCompetition/Testing_img_NEW290_.jpg"
The image is 
When I run the code of
print("===== Tag an Image - local =====")
local_image = open(local_image_path, "rb")
tags_result_local = computervision_client.tag_image_in_stream(local_image)
print("== OutPut ==")
for tag in tags_result_local.tags:
print("\t'{}' with confidence {:.2f}% and with hints of {}".format(tag.name, tag.confidence * 100, tag.hint))
Result is
===== Tag an Image - local =====
== OutPut ==
'outdoor' with confidence 99.94% and with hints of None
'sky' with confidence 99.91% and with hints of None
'tree' with confidence 99.47% and with hints of None
'way' with confidence 94.48% and with hints of None
'scene' with confidence 89.64% and with hints of None
'plant' with confidence 72.12% and with hints of None
'road' with confidence 63.33% and with hints of None
'highway' with confidence 18.62% and with hints of None
And for the description
print("===== Describe an Image - local =====")
local_image = open(local_image_path, "rb")
description_result = computervision_client.describe_image_in_stream(local_image)
print("== Description ==")
if (len(description_result.captions) == 0):
print("No description detected.")
else:
for caption in description_result.captions:
print("\t'{}' with confidence {:.2f}%".format(caption.text, caption.confidence * 100))
print("== TAGS ==")
for i in description_result.tags:
print("\tTags: {}".format(i))
===== Describe an Image - local =====
== Description ==
'a road with trees and buildings' with confidence 32.45%
== TAGS ==
Tags: outdoor
Tags: sky
Tags: tree
Tags: way
Tags: scene
Tags: road
Tags: highway
So key thing is that the tags from the tag_image_in_stream is outdoor', 'sky' , 'tree', 'way', 'scene', 'plant', 'road', 'highway',
and from describe_image_in_stream is outdoor', 'sky' , 'tree', 'way', 'scene', 'plant', 'road', 'highway',
These are the same
When I run using the example API using this link https://azure.microsoft.com/en-us/services/cognitive-services/computer-vision/#features
The result is 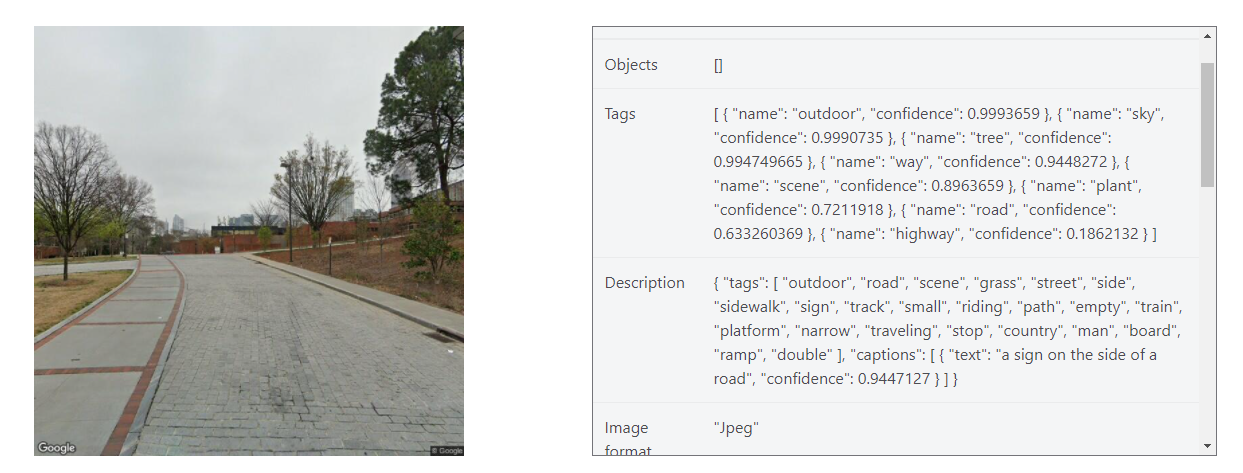
The tags are
Tags [ { "name": "outdoor", "confidence": 0.9993659 }, { "name": "sky", "confidence": 0.9990735 }, { "name": "tree", "confidence": 0.994749665 }, { "name": "way", "confidence": 0.9448272 }, { "name": "scene", "confidence": 0.8963659 }, { "name": "plant", "confidence": 0.7211918 }, { "name": "road", "confidence": 0.633260369 }, { "name": "highway", "confidence": 0.1862132 } ]
and
Description { "tags": [ "outdoor", "road", "scene", "grass", "street", "side", "sidewalk", "sign", "track", "small", "riding", "path", "empty", "train", "platform", "narrow", "traveling", "stop", "country", "man", "board", "ramp", "double" ], "captions": [ { "text": "a sign on the side of a road", "confidence": 0.9447127 } ] }
In description it includes a lot more tags (i need result of sidewalk) so why is there a different result.
Same thing if I use the PIP Install and same thing if I use the ** REST API Directly from curl**
curl -H "Ocp-Apim-Subscription-Key: 53f32bba50f1443cb9ae7e927441db83" -H "Content-Type: application/json" "https://azurehackforaccessibility.cognitiveservices.azure.com/vision/v3.1/analyze?visualFeatures=Categories,Description&details=Landmarks" -d "{\"url\":\"https://raw.githubusercontent.com/Kunal2341/testDeleteBS/main/Testing_img_NEW290_.jpg\"}"
{"categories":[{"name":"outdoor_road","score":0.5703125,"detail":{"landmarks":[]}}],"description":{"tags":["outdoor","sky","tree","way","scene","road","highway"],"captions":[{"text":"a road with trees and buildings","confidence":0.3245285749435425}]},"requestId":"2afd8806-2fff-4611-a9c2-24bccf49bf10","metadata":{"height":640,"width":640,"format":"Jpeg"}}
Same image everywhere
Img link is https://raw.githubusercontent.com/Kunal2341/testDeleteBS/main/Testing_img_NEW290\_.jpg

@ODL_User 310106 Thanks for the details in your question. I think the reason you are seeing a different result from the REST API and the python library is because the demo page is using an older version(v2.1) of the REST API behind the hood which also uses Analyze API instead of Tag and Describe image APIs. You can verify that by running the older python package or REST API directly.
I have run the request for visual features description and tags for Analyze API and it returns the same response as in the screen shot you mentioned above.
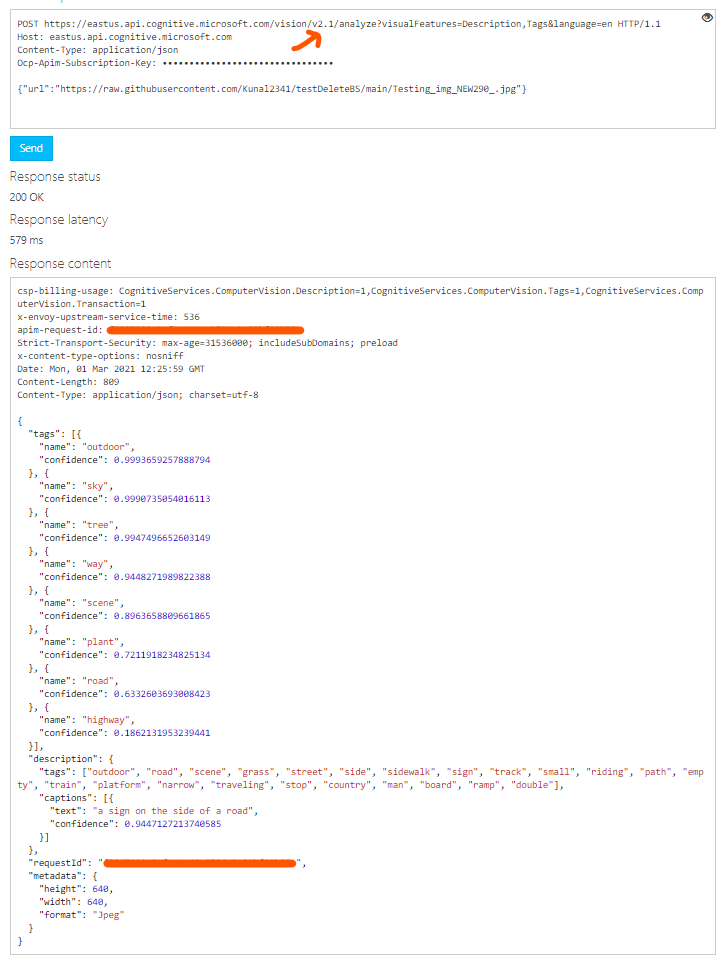
The different versions of the API run with different models mostly because of upgrades in the models so the result could be different. You can choose to use the older version if the results seem accurate or upgrade to newer version. The older versions of the API are available until the team announces retirement for these versions. I hope this helps!!
@ODL_User 310106 Did you get a chance to review the above response and try the scenario again?