SQL Server Integration Services
A Microsoft platform for building enterprise-level data integration and data transformations solutions.
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3ET%3C/text%3E%3C/svg%3E)
Hi I need to set up an SSIS package to import data from experiments (excel files) that are run in duplicate and triplicate this will be done on a multitude of files so it needs to be fully automated. I only need help with the data flow task not the foreach loop container task.
The table I have looks like this:
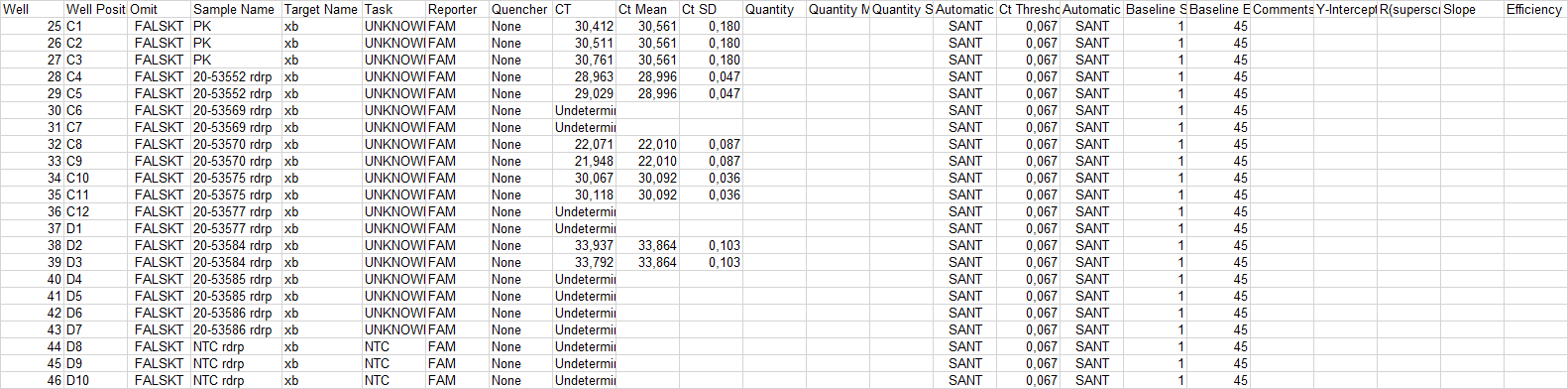
As you can see under sample name there are samples that are run in duplicates and triplicates.
What I would like in the destination table would be this: Where the columns for CT, Well and Well position are pivoted so that each sample only has one row.

' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EMM%3C/text%3E%3C/svg%3E)
Hi @Turgor ,
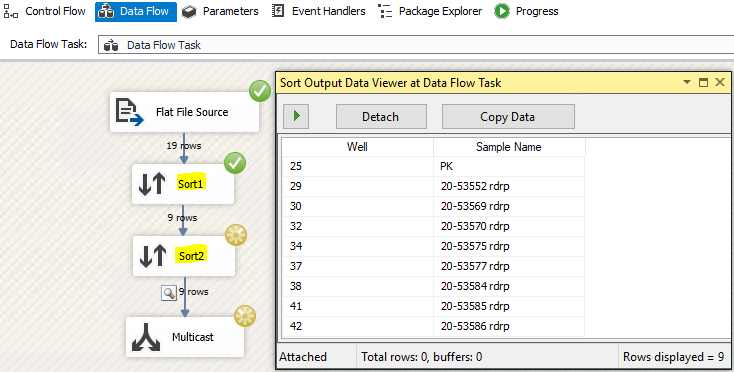
We can use Sort Transformation in Data Flow Task to sort input data in ascending or descending order.
The Sort transformation can also remove duplicate rows as part of its sort. Duplicate rows are rows with the same sort key values. The sort key value is generated based on the string comparison options being used, which means that different literal strings may have the same sort key values. The transformation identifies rows in the input columns that have different values but the same sort key as duplicates.
Please refer to the following pictures:
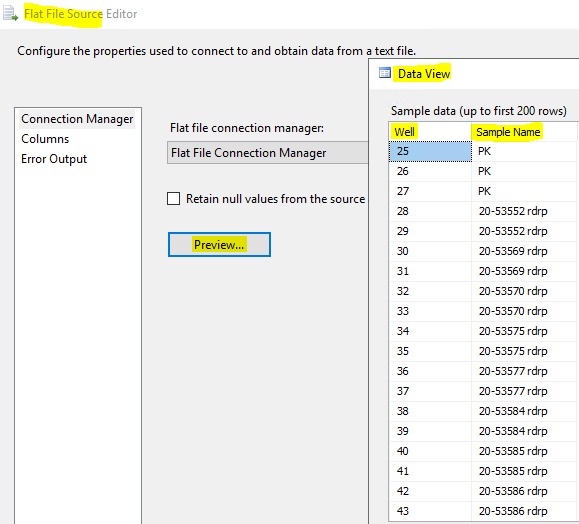
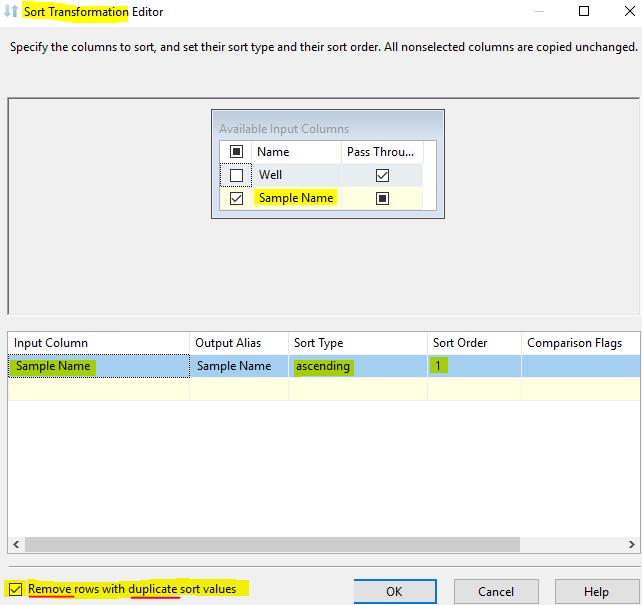
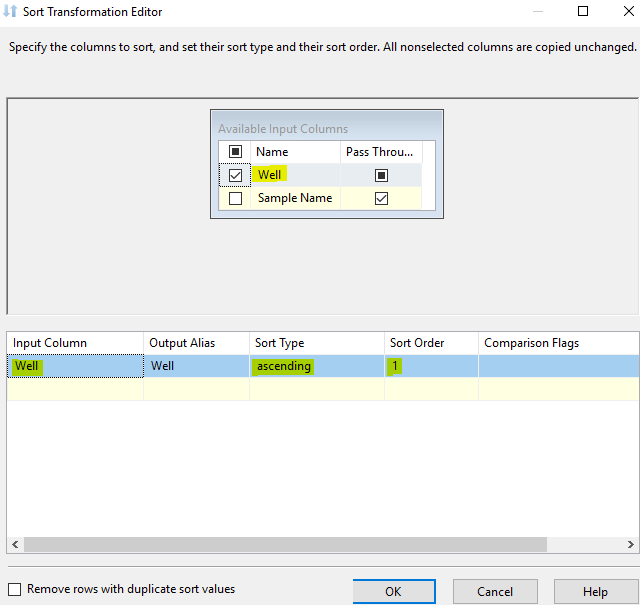
Best regards,
Mona
----------
If the answer is helpful, please click "Accept Answer" and upvote it.
Note: Please follow the steps in our documentation to enable e-mail notifications if you want to receive the related email notification for this thread.