Azure Open Datasets
An Azure service that provides curated open data for machine learning workflows.
30 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EM%3C/text%3E%3C/svg%3E)
Hi, I am new to Azure ML, and I have been trying to replicate the same structure presented in the MNIST tutorial, but I don't understand how to adapt it to my case.
I am running a python file from the experiment, but I don't understand how I can access data that is currently in a folder in the cloud file system from the script running in the experiment.
I have found many examples about accessing one single .csv file, but my data is made of many images.
From my understanding I should first load the folder to a datastore, then use Dataset.File.upload_directory to create a dataset containing my folder, and here is how I tried to do it:
# Create dataset from data directory
datastore = Datastore.get(ws, 'workspaceblobstore')
dataset = Dataset.File.upload_directory(path_data, target, pattern=None, overwrite=False, show_progress=True)
file_dataset = dataset.register(workspace=ws, name='reduced_classification_dataset',
description='reduced_classification_dataset',
create_new_version=True)
But then I don't understand if and how I can access this data like a normal file system from my python script, or I need further steps to be able to do that.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3ERM%3C/text%3E%3C/svg%3E)
@Matzof Thanks for the question. Please follow the below code for writing.
datastore = ## get your defined in Workspace as Datastore
datastore.upload(src_dir='./files/to/copy/...',
target_path='target/directory',
overwrite=True)
Datastore.upload only support blob and fileshare. For adlsgen2 upload, you can try our new dataset upload API:
from azureml.core import Dataset, Datastore
datastore = Datastore.get(workspace, 'mayadlsgen2')
Dataset.File.upload_directory(src_dir='./data', target=(datastore,'data'))
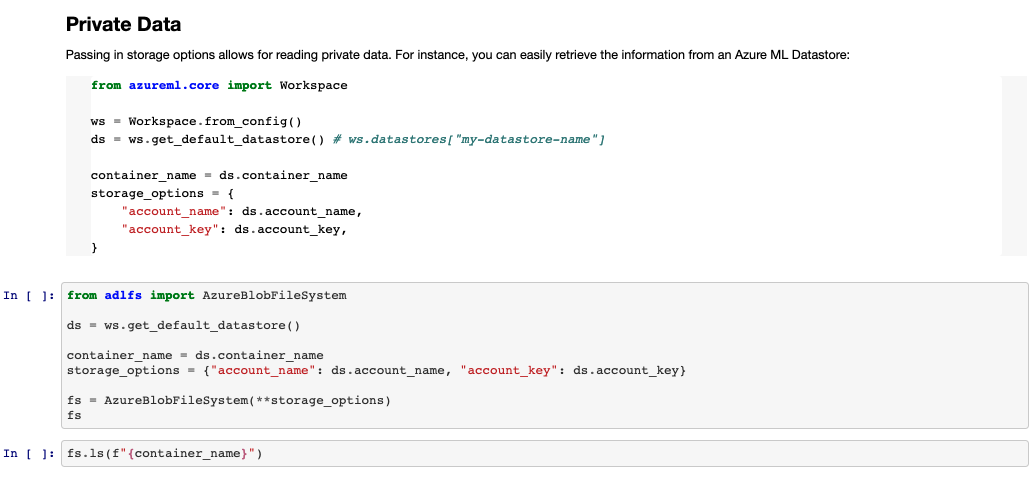
Pandas is integrated with fsspec which provides Pythonic implementation for filesystems including s3, gcs, and Azure. You can check the source for Azure here: dask/adlfs: fsspec-compatible Azure Datake and Azure Blob Storage access (github.com). With this you can use normal filesystem operations like ls, glob, info, etc.
You can find an example (for reading data) here: azureml-examples/1.intro-to-dask.ipynb at main · Azure/azureml-examples (github.com)
Writing is essentially the same as reading, you need to switch the protocol to abfs (or az), slightly modify how you're accessing the data, and provide credentials unless your blob has public write access.
You can use the Azure ML Datastore to retrieve credentials like this (taken from example):