Azure Synapse Analytics
An Azure analytics service that brings together data integration, enterprise data warehousing, and big data analytics. Previously known as Azure SQL Data Warehouse.
4,368 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EGJ%3C/text%3E%3C/svg%3E)
The Synapse documentation states that the %%time magic command can be used in Spark notebooks in Synapse. This does not seem to be the case when calling those notebooks from a pipeline. Here's what I'm experiencing, using PySpark notebooks in Synapse pipelines:
MS, is this a bug, or is the Synapse documentation wrong and %%time is not supposed to work?
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3ESS%3C/text%3E%3C/svg%3E)
@Grant, Josh Thanks for using Microsoft Q&A !!
I am able to reproduce this issue and checking internally with the products team and I believe you are talking about the below where cell having magic command is being excluded from the result -


Command executed successfully with %

@Saurabh Sharma That's correct. This notebook shows that the cell is not just missing from the output, but it was never executed at all:
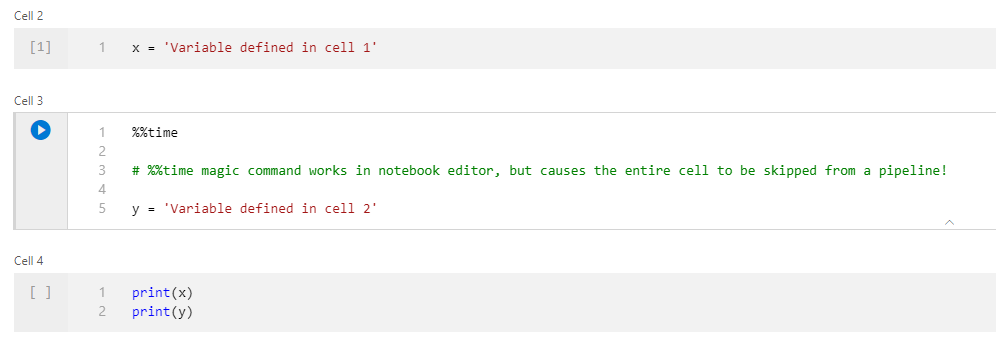

... and changing the magic command from %%time to %time also fails in the pipeline, with a different error:

@Grant, Josh Thanks for confirming. Sure, I have already started an internal discussion with the products team and I will share the updates as soon as I hear back.
@Grant, Josh I have received confirmation from the products team that -
%time 2*4 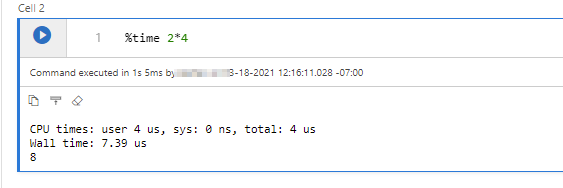
----------
Please do not forget to "Accept the answer" wherever the information provided helps you to help others in the community.
@Grant, Josh Following up as I have not heard back from you. Did my answer solve your issue? If so, please mark as accepted answer. If not, please let me know how I may better assist.
@Grant, Josh I have not heard back from you. Did my answer solve your issue? If so, please mark as accepted answer. If not, please let me know how I may better assist.