Computer Vision
An Azure artificial intelligence service that analyzes content in images and video.
417 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EN%3C/text%3E%3C/svg%3E)
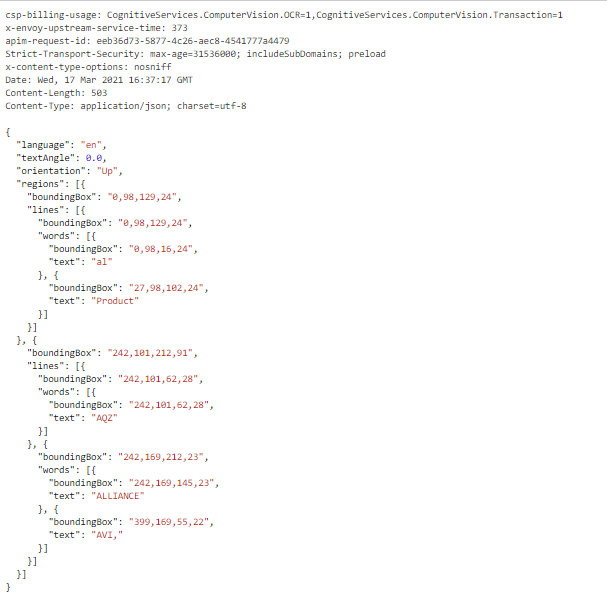
I am throwing a few documents at computer vision in order to extract the text within them. These documents contain no hand-written characters, and the font used in the document seems to be reasonably easy to read. (however I am not a computer),
Unfortunately I am encountering a lot of consistency issues, as computer vision seems to mistake characters frequently.
examples:
Does anybody have any experience/ advice on what can be done to resolve this?
attached example screenshot. I was scanning the forums for similar issues, and it might be caused by the issue: read-ocr-bounding-box-accuracy.html


@nick Did you get a chance to review the above response and try the scenario again?
hey @romungi-MSFT , sorry for not coming back sooner.
After your comment, I noticed that the c# sdk I was using was using the v2 computer vision api, instead of the v3. After updating to the latest, that particular OCR issue was resolved.
Thanks for your help!