Azure Synapse Analytics
An Azure analytics service that brings together data integration, enterprise data warehousing, and big data analytics. Previously known as Azure SQL Data Warehouse.
5,378 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3ES%3C/text%3E%3C/svg%3E)
I have the following questions about connecting to Azure synapse dedicated pool from databricks
spark.databricks.sqldw.jdbc.service.principal.client.id, spark.databricks.sqldw.jdbc.service.principal.client.secret,
what should be the url for df.write.format("com.databricks.spark.sqldw")? Should I need to use option(username)...??

anyone has the idea ?

Hello @sakuraime ,
Connecting Azure Synapse using OAuth 2.0 with a service principal for authentication is available from
Databricks Runtime 8.1 and above.
Below are the steps to connect Azure Synapse using OAuth 2.0 with a service principal for authentication:
Step1: Provide service Principal – permissions to Azure Synapse Analytics and storage account.
Azure Synapse Analytics: Go to workspace => Under settings => SQL Active Directory admin => Click on Set admin => Add registered application => Click on save.

Azure Storage temp account: Go to Storage account => Access Control (IAM) => Add role assignment => Select Role: Storage Blob Data Contributor Select: register application => Click on save.

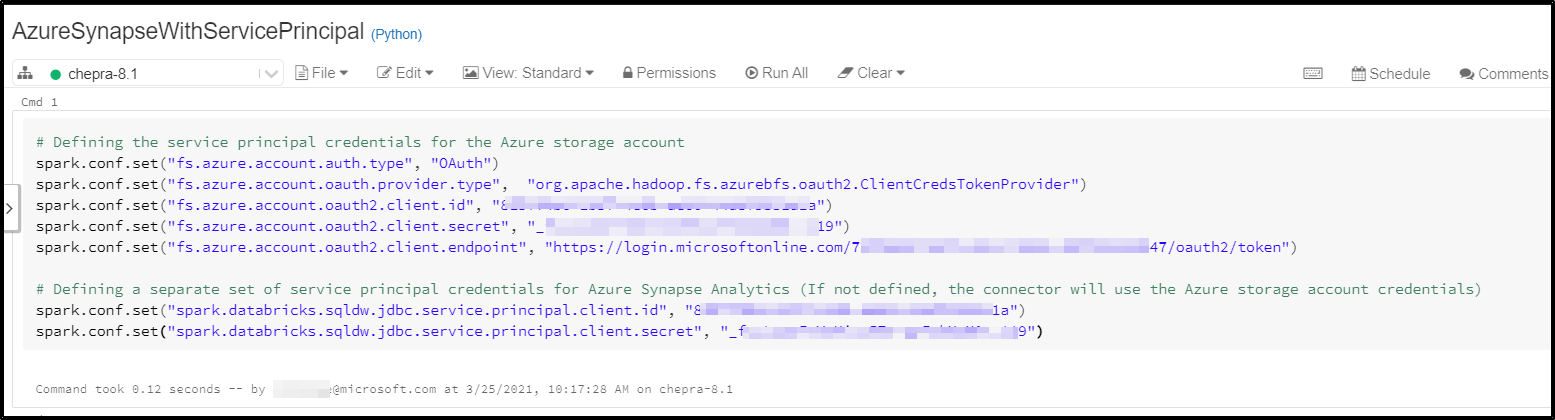
Step2: Define Service Principal credentials for the Azure Synapse Analytics and storage account.
Python Code:
# Defining the service principal credentials for the Azure storage account
spark.conf.set("fs.azure.account.auth.type", "OAuth")
spark.conf.set("fs.azure.account.oauth.provider.type", "org.apache.hadoop.fs.azurebfs.oauth2.ClientCredsTokenProvider")
spark.conf.set("fs.azure.account.oauth2.client.id", "<application-id>")
spark.conf.set("fs.azure.account.oauth2.client.secret", "<service-credential>")
spark.conf.set("fs.azure.account.oauth2.client.endpoint", "https://login.microsoftonline.com/<directory-id>/oauth2/token")
# Defining a separate set of service principal credentials for Azure Synapse Analytics (If not defined, the connector will use the Azure storage account credentials)
spark.conf.set("spark.databricks.sqldw.jdbc.service.principal.client.id", "<application-id>")
spark.conf.set("spark.databricks.sqldw.jdbc.service.principal.client.secret", "<service-credential>")
Step3: Set the enableServicePrincipalAuth option in the connection configuration.
Sample URL: "url", "jdbc:sqlserver://<workspacename>.sql.azuresynapse.net:1433;database=<databasename>;encrypt=true;trustServerCertificate=true;hostNameInCertificate=*.sql.azuresynapse.net;loginTimeout=30"
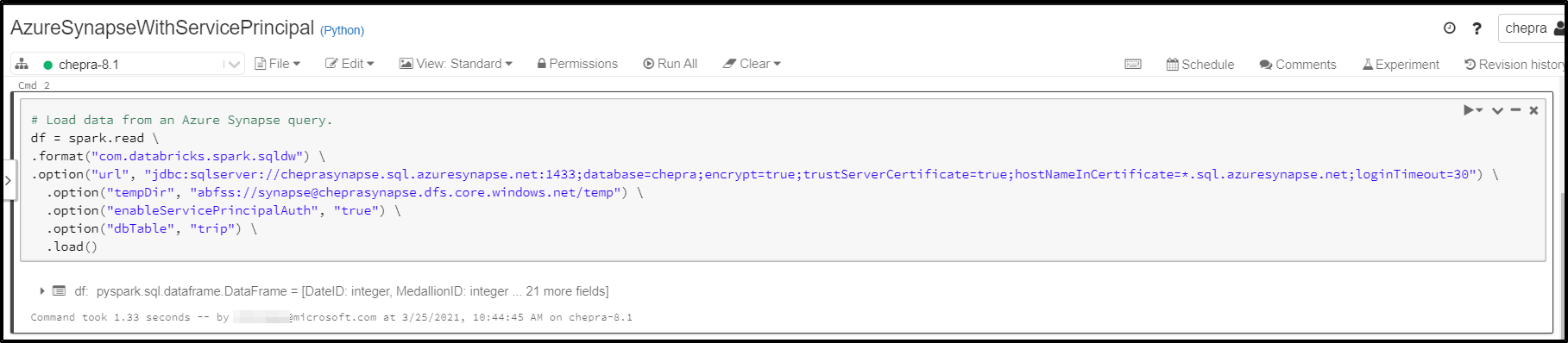
Load data from an Azure Synapse query.
Python Code:
df = spark.read \
.format("com.databricks.spark.sqldw") \
.option("url", "jdbc:sqlserver://<the-rest-of-the-connection-string>") \
.option("tempDir", "abfss://<your-container-name>@<your-storage-account-name>.dfs.core.windows.net/<your-directory-name>") \
.option("forwardSparkAzureStorageCredentials", "true") \
.option("dbTable", "<your-table-name>") \
.load()
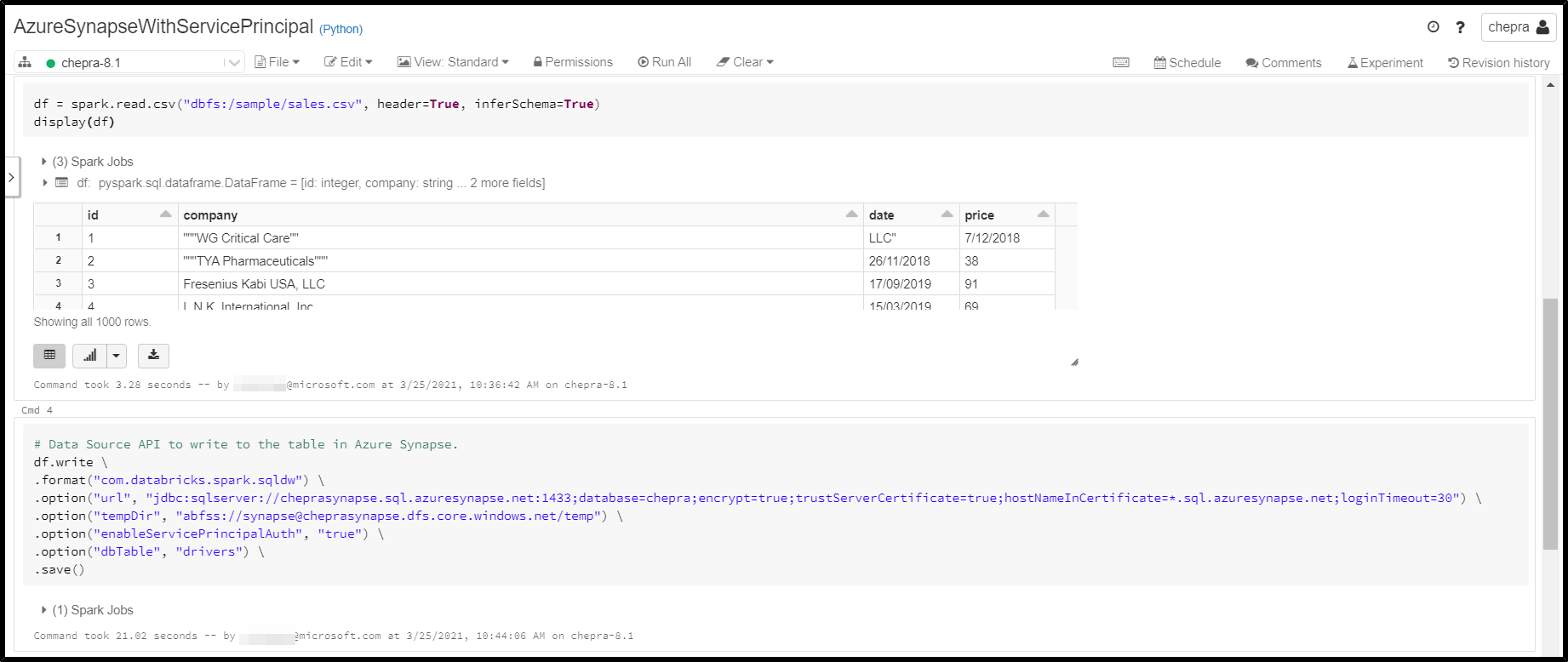
Write data to the table in Azure Synapse.
Python Code:
df.write \
.format("com.databricks.spark.sqldw") \
.option("url", "jdbc:sqlserver://<the-rest-of-the-connection-string>") \
.option("forwardSparkAzureStorageCredentials", "true") \
.option("dbTable", "<your-table-name>") \
.option("tempDir", "abfss://<your-container-name>@<your-storage-account-name>.dfs.core.windows.net/<your-directory-name>") \
.save()
Hope this helps. Do let us know if you any further queries.
------------
Please don’t forget to Accept Answer and Up-Vote wherever the information provided helps you, this can be beneficial to other community members.
Hello @sakuraime ,
Just checking in to see if the above answer helped. If this answers your query, do click Accept Answer and Up-Vote for the same. And, if you have any further query do let us know.
Hello @sakuraime ,
Following up to see if the above suggestion was helpful. And, if you have any further query do let us know.
Take care & stay safe!
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EP%3C/text%3E%3C/svg%3E)
Hello, is it necessary to set up a different app/SPN for Synapse?
Why would you and if you don't what's the issue with using the same app/SPN configured for the DLG3 storage acct?
Thank you!
I found SPN only allow when blob storage is allowing all traffic...
if you block all traffic from blob storage( even using private link) . using SPN will failed to authenticate from Azure synapse.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3ER%3C/text%3E%3C/svg%3E)
Hi
This data seems good to me. I have a doubt that how can we extract data from synapse tables using databricks.could you please explain this part separately.
Thank you.
Hello @Revathi ,
Since this thread is too old, I would recommend creating a new thread on the same forum with as much details about your issue as possible. That would make sure that your issue has better visibility in the community.