Azure AI Search
An Azure search service with built-in artificial intelligence capabilities that enrich information to help identify and explore relevant content at scale.
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.

Hello All...
I have a few Excel files stored in a Blob Storage Container. Each file is of size ranging from 5 MB to 8 MB with the record counts ranging from 40K to 70K.
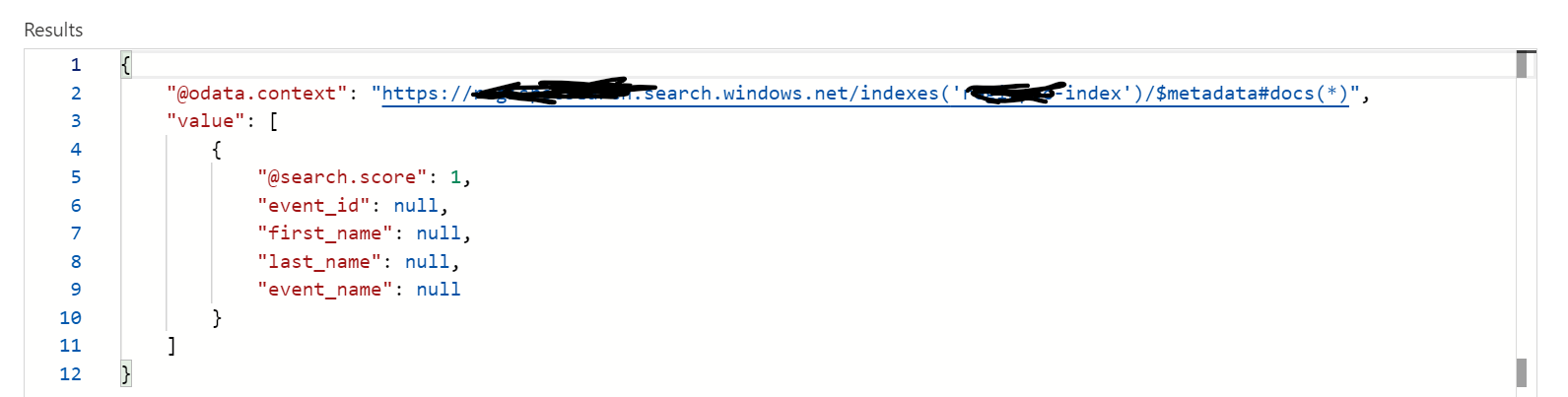
After setting up Azure Cognitive Search for these files (via Azure Blob Storage), while performing the request URL check in the Search Explorer, I got nulls for the selected fields. Please refer the screenshot "1. Search Results_31Mar".
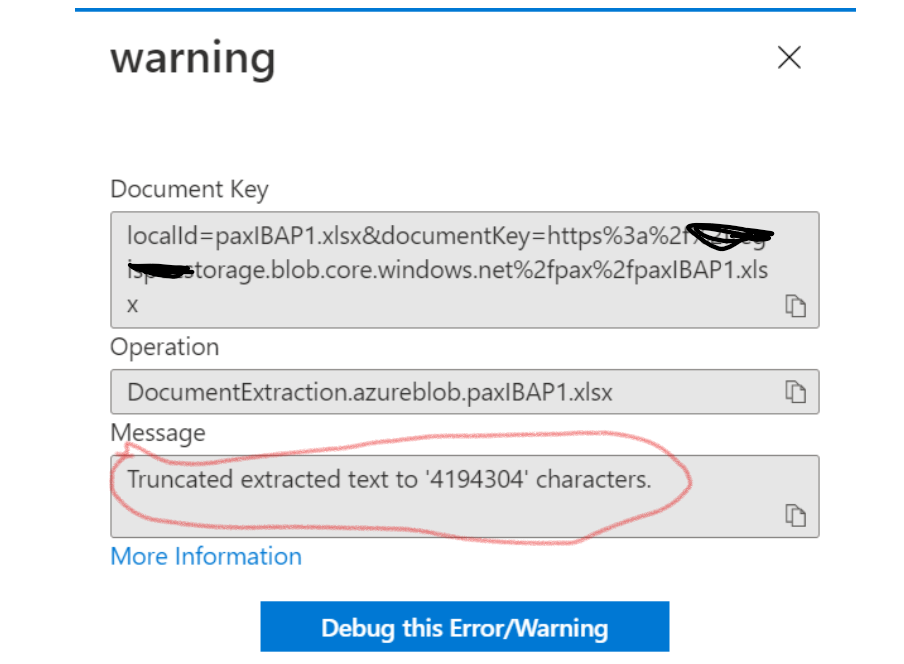
Upon investigation, there was a warning in the indexer execution denoting the truncation of the extracted text. Please refer the screenshot "2. Search Warning_31Mar".
I took out all the files from the container and placed only one file with just 10 records and 10 columns. The result is still the same.
Could anyone advise ? (Before using the blob storage, I had done some testing using the Real Estate Demo data from Azure. It worked perfectly fine).
Thank you.!
Regards,
Mahesh
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3ESM%3C/text%3E%3C/svg%3E)
Just checking in to see if the below answers helped. If this answers your query, do click “Accept Answer” and Up-Vote for the same. This will help others having similar query.
Regarding the additional queries # 2 & #3, I have not been able to test them.
But yes, the main query related to the parsing mode has been clarified. Thank you.
Regards,
Mahesh
Thanks for reply. The default parsing mode for Azure Search Blob Indexers will just extract all of the textual data in the file into the “content” field, as you saw in your second experiment. It sounds like what you want is to parse the excel document such that each row is treated as a separate document (and indexed as a separate entry), and each column a separate field? If that’s the case, consider changing the configuration on the indexer to read the document’s data as delineated records rather than a blob of text.
may be the indexer definition would look something like:
{
"name" : "my-csv-indexer",
...
"parameters" : { "configuration" : { "parsingMode" : "delimitedText", "firstLineContainsHeaders" : true, "delimitedTextDelimiter" : "," } }
}
Be sure to change the delimiter to whatever they save the files with. CSV is the most common.
The truncation warning you saw is also significant and it may mean you’re not indexing all rows in the document. You may need to split the files up into smaller chunks.
Thanks for asking question! Could you please confirm which tier you are using as Azure Cognitive Search limits how much text it extracts depending on the pricing tier. The current service limits are 32,000 characters for Free tier, 64,000 for Basic, 4 million for Standard, 8 million for Standard S2, and 16 million for Standard S3. A warning is included in the indexer status response for truncated documents.
You may refer to below document links for details:
https://learn.microsoft.com/en-us/azure/search/search-howto-indexing-azure-blob-storage#indexing-blob-content
https://learn.microsoft.com/en-us/azure/search/search-limits-quotas-capacity#indexer-limits
Let us know if issue remains.
Hello @SnehaAgrawal-MSFT ..
Thanks for your response !
I am using a Standard pricing tier. The issue does not seem to be related to the text limitations.
As I had mentioned in the 2nd portion of my post yesterday, I am just using only one file of 10 records...
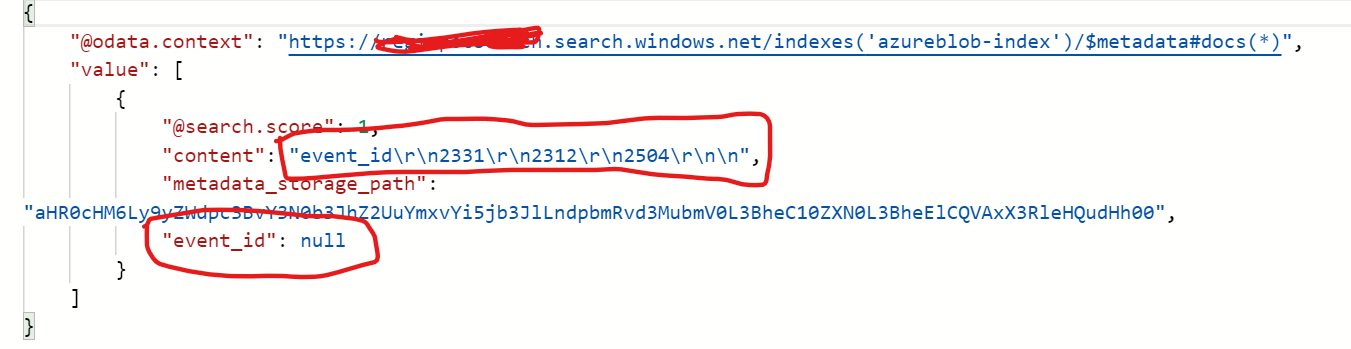
In fact, I have even reduced it to just 1 column (event_id) with 1 record. I am still only getting null for that column, though the content is properly being searched as shown in the attachment.
(I have tried rebuilding the indexes, indexers quite a few times, but of no avail).
Please advise.
Thank you.
Regards,
Mahesh
Thanks for your suggestion @SnehaAgrawal-MSFT on the parsing mode change ! It is working perfectly fine now...
A few more queries to be clarified, if you could help answer them as well..(if needed, I can create a separate post for the below queries).
Thank you.
Mahesh
Glad to to know it resolved. Below is further clarification on asked queries:
1.Now that, each record in each Excel file is treated as a separate document and a separate index entry, assuming the total number or records in all the Excel files is around 400K, will the indexer create 400K documents ?
Ans: Correct, if there are 400k rows in the excel files, there should be 400k documents in the search index once indexing is complete
2.If I have to split up the Excel files into smaller chunks, would there be any significance ? (because the number of records is still going to be the same)
Ans: It should not influence the final number of documents in the index. It’s possible the data in the index could be influenced if you are using the metadata_storage_name field for anything. The default document key also usually includes the blob file name as well.
3.Should the Excel files contain the same list of column headers and the same list of columns, if they have to be indexed together ?
Ans: That’s up to you, and contingent on your data. Each document need not have the same list of column headers. Indexers will populate null values for files that are missing columns. I encourage you to try a few different configurations until you get the results you expect.
Check: https://learn.microsoft.com/en-us/azure/search/search-howto-index-csv-blobs#setting-up-csv-indexing
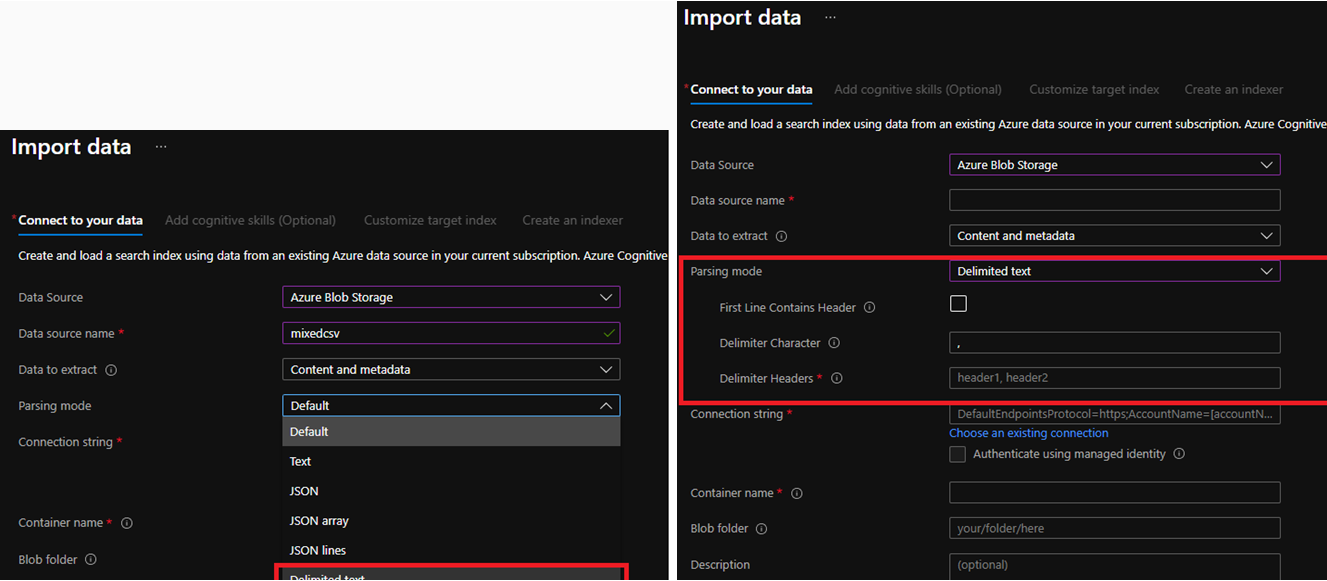
You can explicitly specify what the expected column headers should be for all documents the indexer indexes, or let the indexer determine column names from the first line of the excel files. EG:
"firstLineContainsHeaders" : true/false
"delimitedTextHeaders" : "id,datePublished,tags"
Further, This is all configurable from the azure portal as well
Hope this helps.