Azure Data Factory
An Azure service for ingesting, preparing, and transforming data at scale.
9,751 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EIM%3C/text%3E%3C/svg%3E)
Hi Team,
I am trying to Load CSV file to table storage which is taking more than 30 minutes to load 300MB file to table, Please suggest how can I improve the performance of this copy .
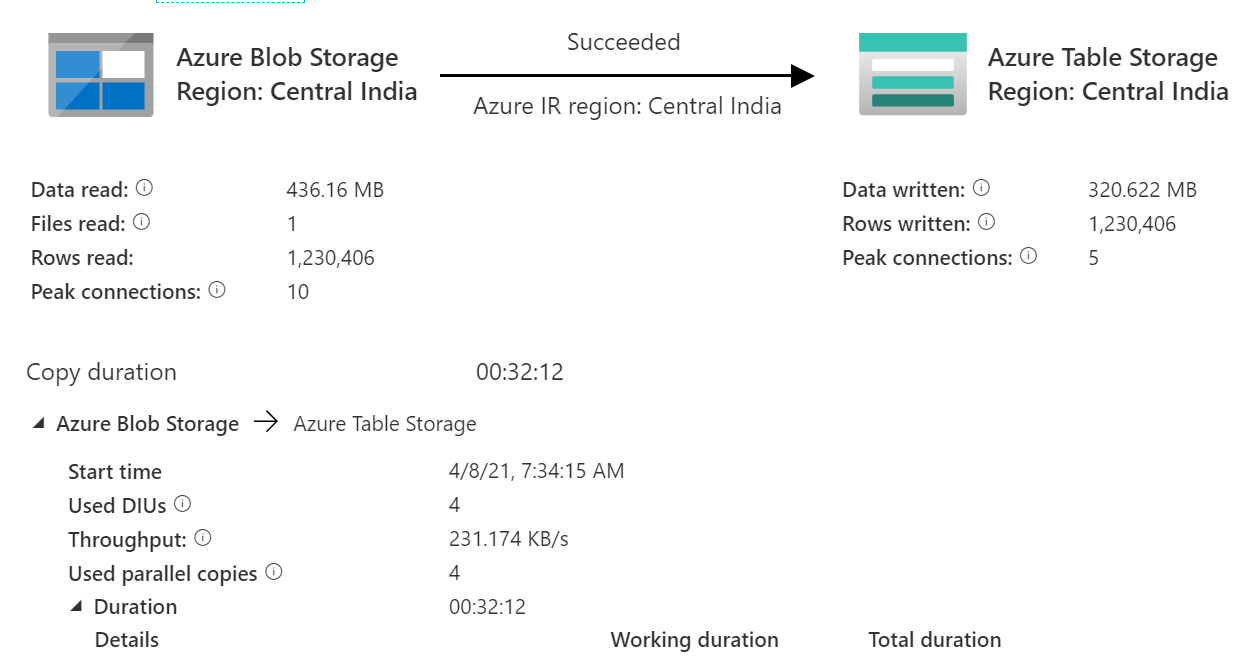
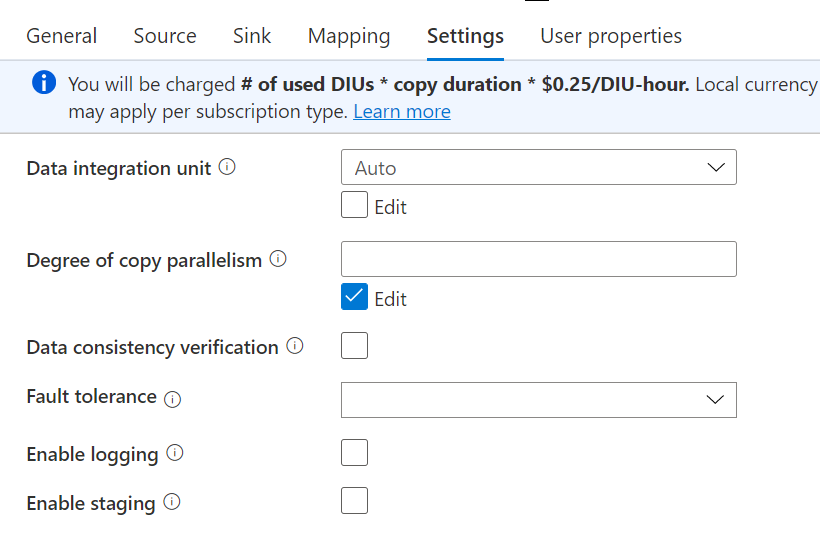
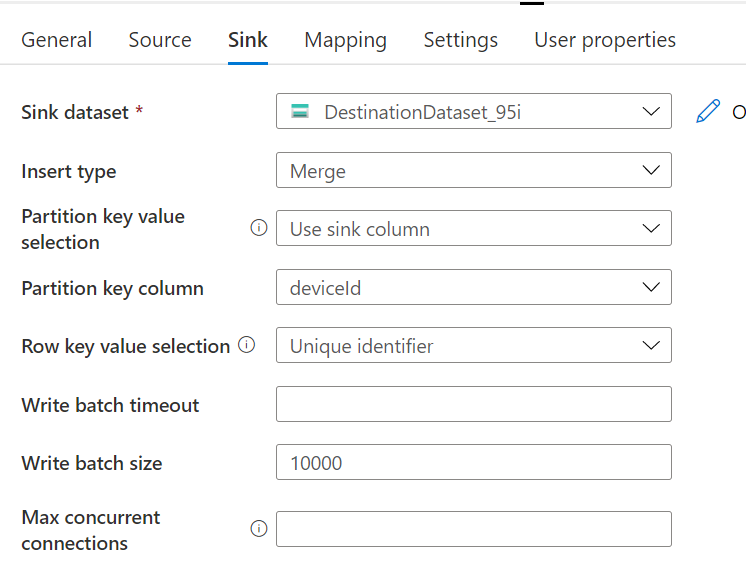
after changing few settings also, it is taking a huge time to load. Please help me resolve this.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EMM%3C/text%3E%3C/svg%3E)
Hello @Imran Mondal I am bringing in others to help on your case.
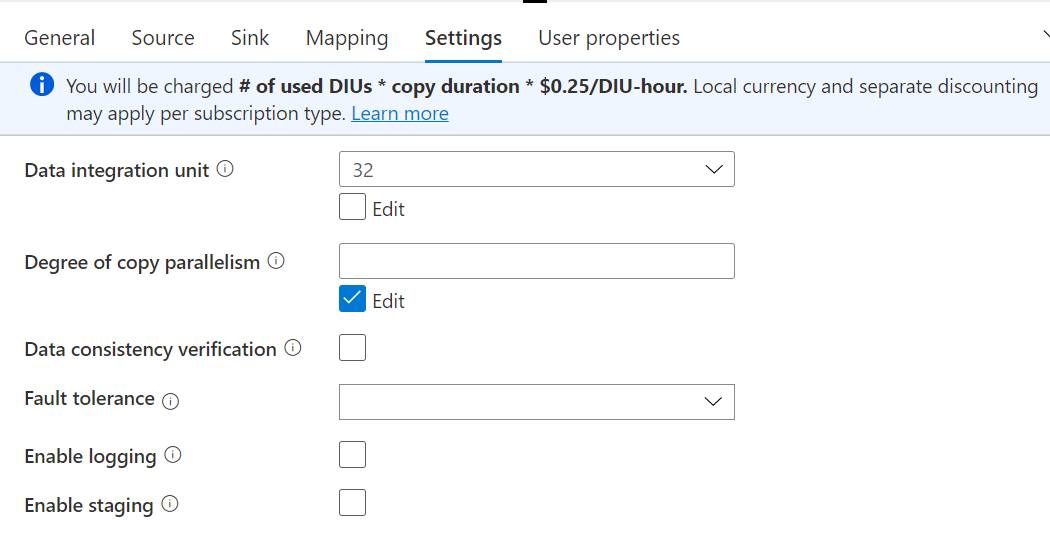
In the short term you can try increasing DIU to 20.
The long term may involve an analysis of the table partition and data skew.
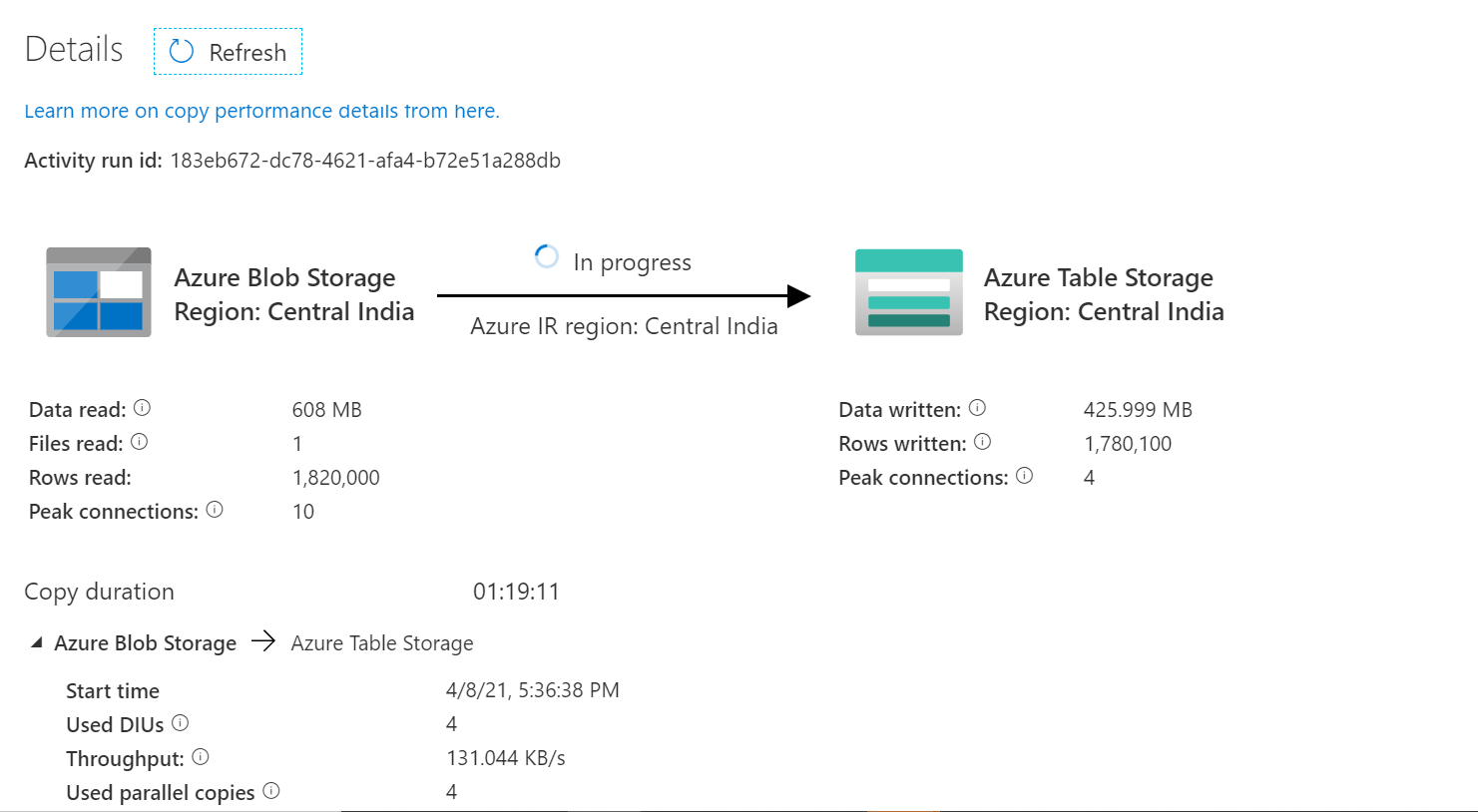
Thank you @MartinJaffer-MSFT , I have tried increasing DIU to 32 also, but still the same. I have attached the sample file for your reference. we are getting more than millions of rows in a file..
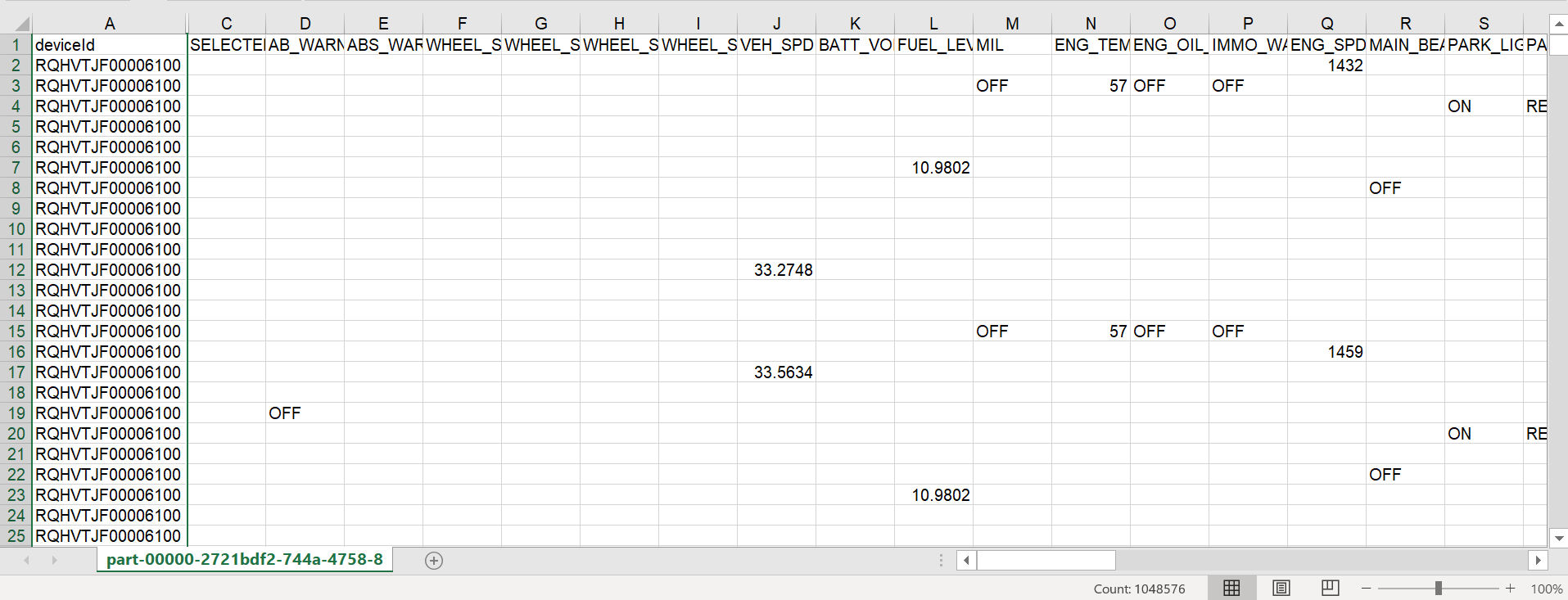
Is deviceId the partitionkey? From this sample it looks like deviceId is always the same.
@Imran Mondal
I suspect the slowdown is caused by the "unique rowkey" option. My hypothesis, is that since ADF uses the "Insert or Merge" and "Insert or Replace" operations, instead of the "Insert" operation, the task of finding a new unique rowkey value is harder. It would have to guess a value, then query the table to find out if it is already in use or not. If rowkey is already in use, guess again, if not in use, insert. The more rows in the table, the more likely it will have to guess again.
If this is the case, then adding a unique value to your data, and specifying that as rowkey would speed things up. The table storage locates a row as a combination of partitionkey and rowkey.