Azure Data Factory
An Azure service for ingesting, preparing, and transforming data at scale.
11,639 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EA%3C/text%3E%3C/svg%3E)
I know you used to be able to get row counts from files in directories with Data Lake Analytics U-SQL, but is there a way to get row counts on all files in a given directory directly from Azure Data Factory? I need to perform some validation tasks and don't have the ability to use U-SQL in the environment and Mapping Dataflows doesn't support MSI so I also can't use that. I feel like there's no options other than spinning up a Databricks resource and mounting directories and writing python. It seems like there should be an easy way to do this though in ADF but I'm not finding one.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EJA%3C/text%3E%3C/svg%3E)
Probably not the cheapest or quickest option and assuming that you are using CSV, but you could create a generic dataset (one column) and run a copy activity over whatever folders you want to count to a temp folder. Get the rowcount of the copy activity and save it.
At the end, delete everything in your temp folder.
Something like this:
Lookup Activity (Get's your list of base folders - Just for easy rerunning)
For Each (Base Folder)
Copy Recursively to temp folder
Store proc activity which stores the Copy Activity.output.rowsCopied
Delete temp files recursively.
I actually thought about doing something like this as well. You're saying to iterate over all the files with a Source that represents my files, but a SINK that is a dummy file with one column so that it doesn't take up much storage and processes faster. That might be an option, thanks!
The source dataset would be the single column - That way it would not matter what the actual columns are. This is assuming that you have different columns in your source files. If they are all the same structure, then yes, just copy one column for improved speed and smaller storage.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3ECM%3C/text%3E%3C/svg%3E)
Hi @AzureHero ,
Yes you can very easily get the row counts from files stored in an Azure Blob Storage account. To do so, you would do the following :

@activity('getListOfFiles').output.childItems as shown below : 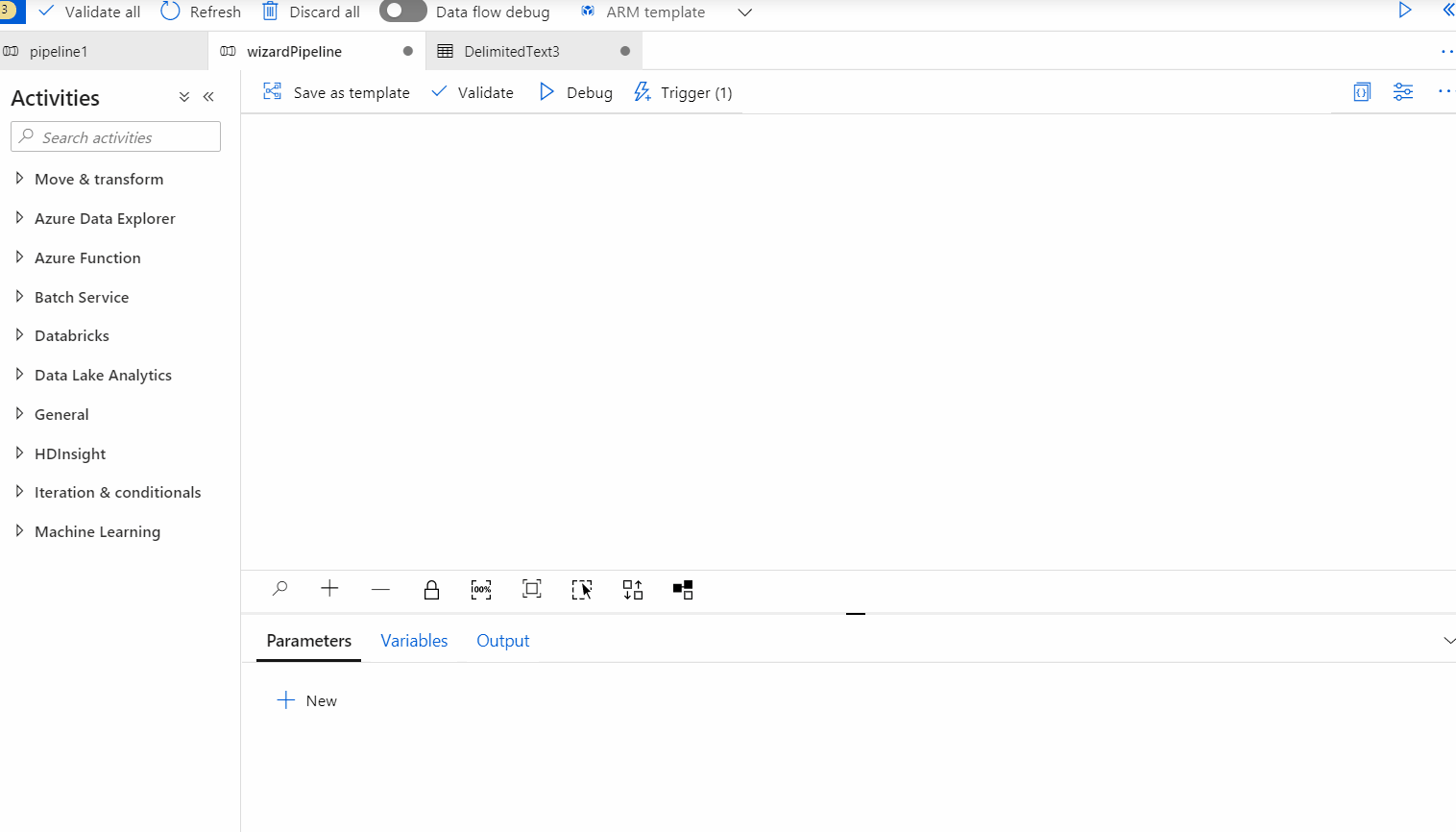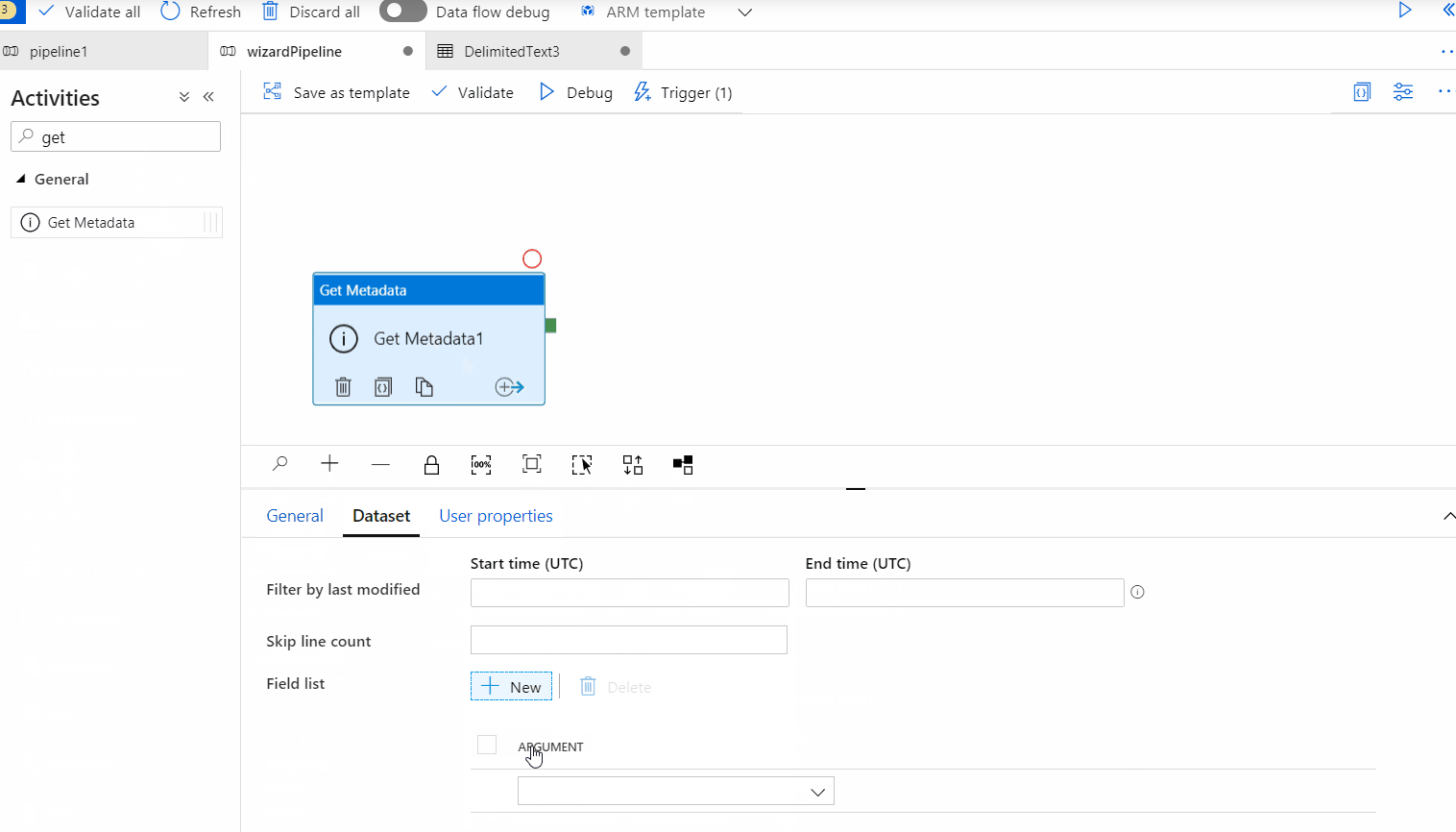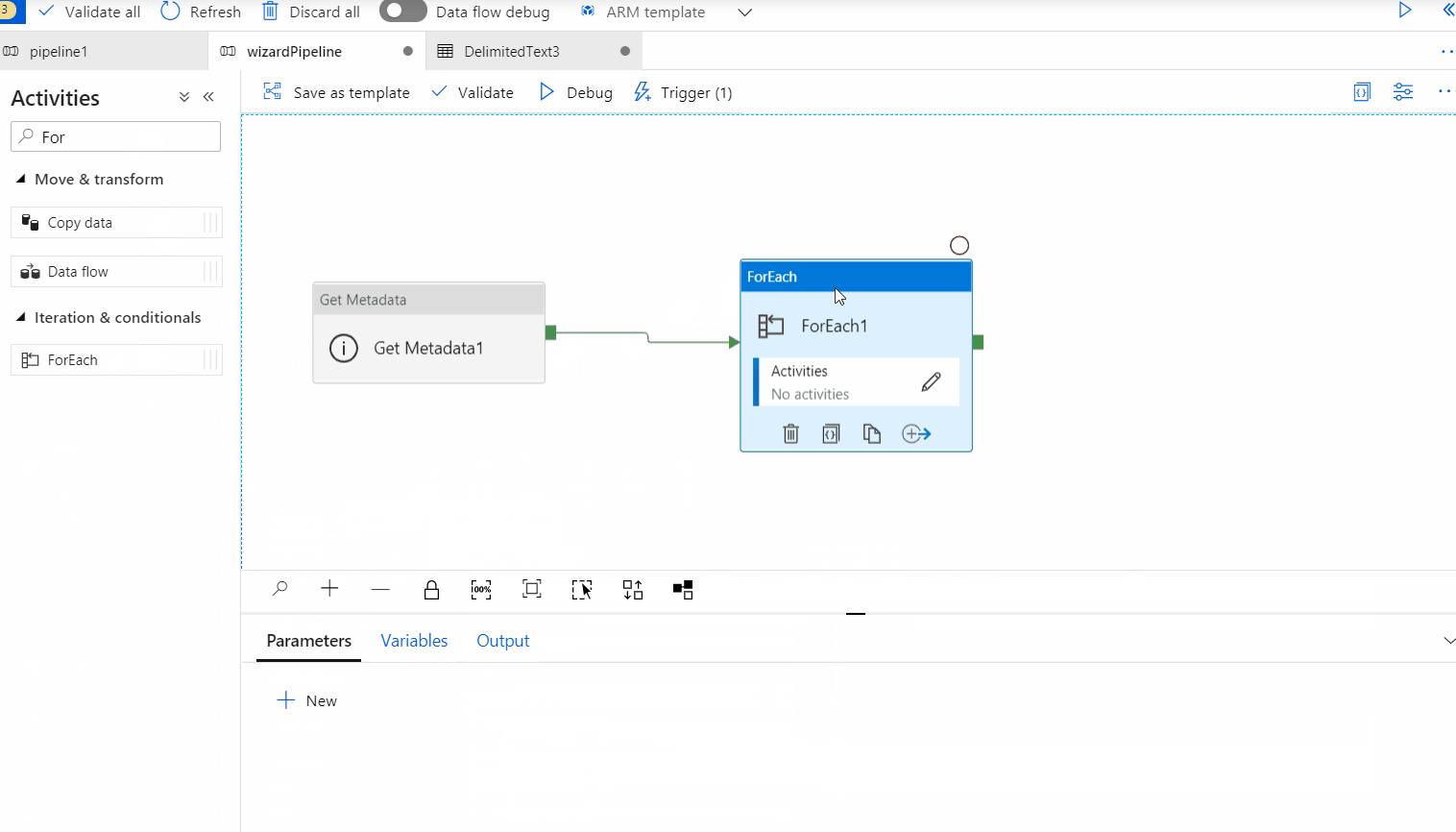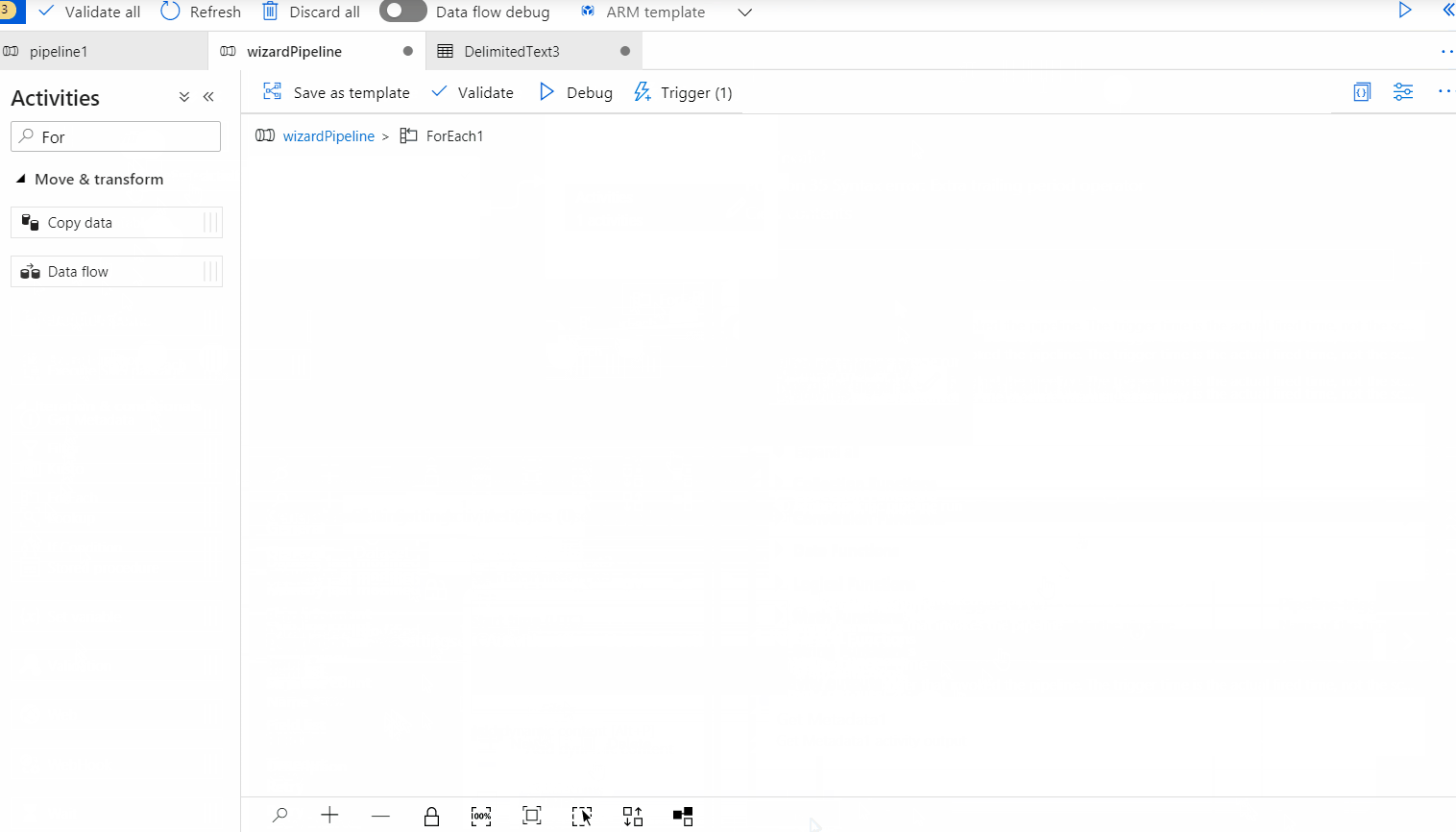
"@item().name" as shown below : 
Please note that the lookup activity has a limitation of only 5000 rows per dataset by default. Here's a workaround to overcome this :
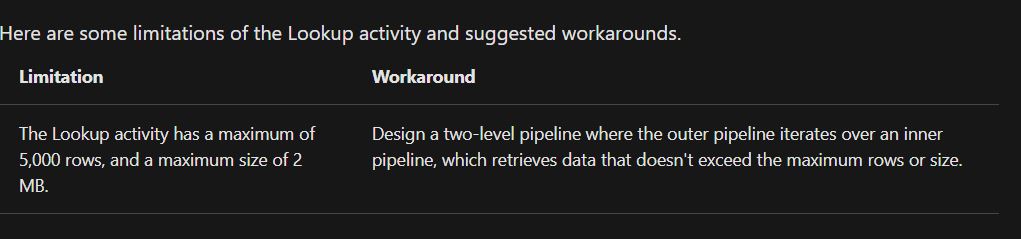
Hope this helps. Stay safe!
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EJV%3C/text%3E%3C/svg%3E)
What if I have a recursion of folders to do before I can take row counts, eg customer/day/file.xls? I have the examples working to display type: folders in my customer parent directory, but now i need to loop thru each file in each day subfolder and take a RowCount...right?
@activity('getListOfFiles').output.childItems. "@item().name". Please note that the lookup activity has a limitation of only 5000 rows per dataset by default.
Please use the links below to see images for the same :
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3ENM%3C/text%3E%3C/svg%3E)
Hi ChiragMishra, could you please elaborate on the workaround, how to achieve inner/outer pipelines, in orde to get row count details?
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EMB%3C/text%3E%3C/svg%3E)
Hi ChiragMishra-MSFT. I have the same problem with more than 5000 rows. Please could you upload an example for this case?
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EJL%3C/text%3E%3C/svg%3E)
@ChiragMishra-MSFT any examples for inner/outer pipelines, in order to overcome 5000 rows limit. I have files with 10M+ records.
Thank you for the response. I have thousands of files and many of them will likely have over 5000 records which is why I couldn't use the lookup task to accomplish this. But I will look closer at the workaround on splitting the pipelines up into two inner/outer pipelines to see if that can work.
Hi, were you able to get rowcount of the file with more that 5k rows, using inner/outer pipeline
Hi AzureHero and NarasimhaMurthyPujari-6355. Maybe you have an example