Developer technologies | ASP.NET | Other
A set of technologies in .NET for building web applications and web services. Miscellaneous topics that do not fit into specific categories.
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EDS%3C/text%3E%3C/svg%3E)
Hi ,
I am using DocumentFormat.OpenXml for reading content from .docX file in asp.net c#.
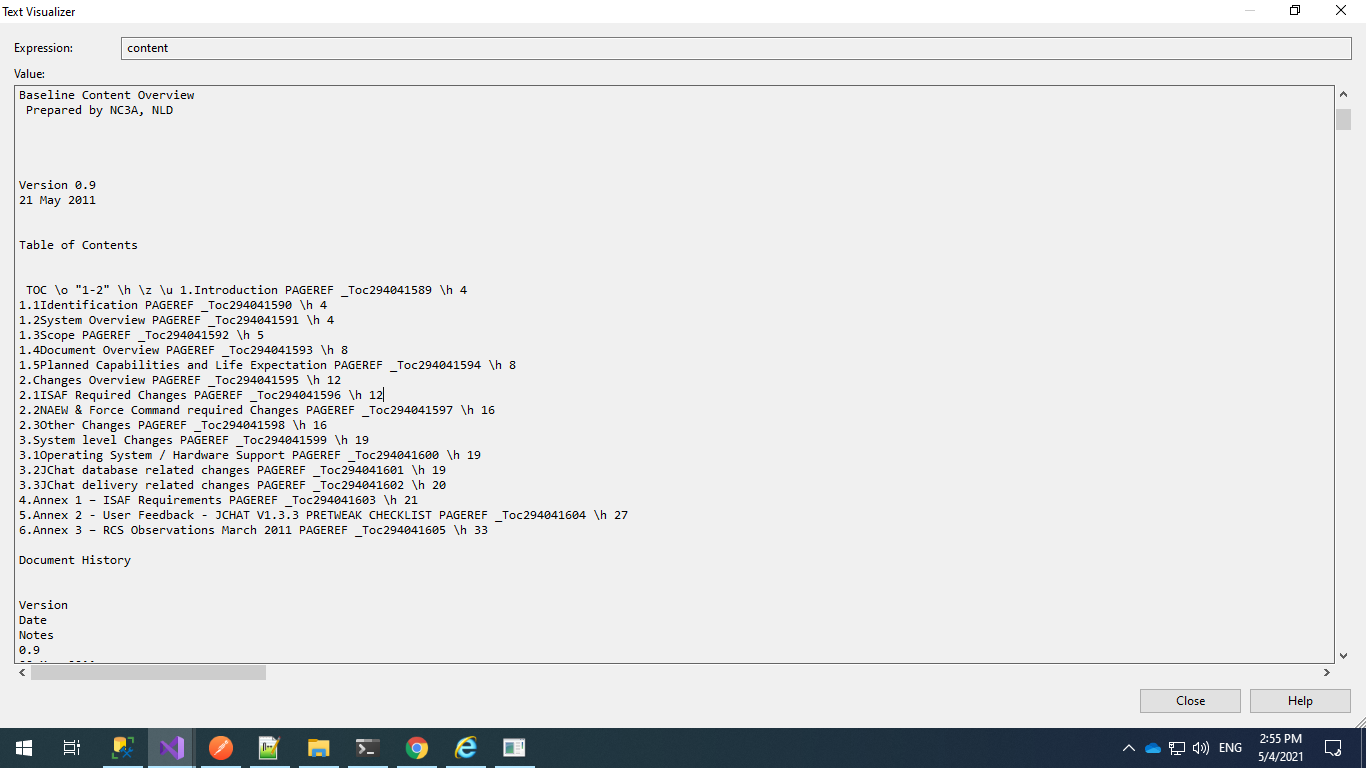
I have issue with paragraph.InnerText it is given " TOC \o \"1-2\" \h \z \u 1.Introduction PAGEREF _Toc294041589 \h 4" but I need only content without heading. how I can achieve it.
My Code
Package wordPackage = Package.Open(filePath, FileMode.Open, FileAccess.Read);
using (WordprocessingDocument wordDocument = WordprocessingDocument.Open(wordPackage))
{
StringBuilder stringBuilder = new StringBuilder();
IEnumerable<Paragraph> paragraphs = wordDocument.MainDocumentPart.Document.Body.Elements<Paragraph>();
foreach (var paragraph in paragraphs)
{
Console.WriteLine(paragraph.InnerText);
stringBuilder.Append(paragraph.InnerText + "\r\n");
}
string content = stringBuilder.ToString();
}
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EYS%3C/text%3E%3C/svg%3E)
Hi @Dhananjay Siwach ,
What's your heading?"Introduction PAGEREF _Toc294041589"? Each paragraph has heading? Could you tell us more details to us?
Best regards,
Yijing Sun
Hi @Yijing Sun-MSFT ,
I have many .docX files which is have content with heading. I have attach heading screenshot.
I have try many code but I am not able to find only Heading text with space or tab.
Example : I am using following code to getting heading content but I am not getting heading content with space or tab
IEnumerable<Paragraph> paragraphs = wordDocument.MainDocumentPart.Document.Body.Elements<Paragraph>();
foreach (var paragraph in paragraphs)
var paragraphText = paragraph.Descendants<DocumentFormat.OpenXml.Wordprocessing.Text>();
text += txt.Text;
if (!string.IsNullOrEmpty(txt.Space) && txt.Space == SpaceProcessingModeValues.Preserve)
text += " ";

Hi @Dhananjay Siwach ,
As far as I think,you could use run() method.
new Paragraph(new Run(new Text(para.InnerText)))
Best regard,
Yijing Sun
Hi @Yijing Sun-MSFT ,
I am using your suggested code still I am getting heading with style code. kindly look into it.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EAP%3C/text%3E%3C/svg%3E)
If you use InnerText, it concatenates all the texts of all the xml elements that make up the paragraph internally. That's not what you want.
Instead, you need to enumerate all the Run elements of the Paragraph and for each Run, each of the Text elements, and then you take the text from there.
To enumerate the Runs, you would use a loop similar to this:
foreach (var run in paragraph.Elements<Run>())
And a similar loop would enumerate the run.Elements<Text> to get all the texts.
For more info, explore the documentation starting here for the Run.
Hi @Alberto Poblacion ,
This code not working for Heading content. not getting docX heading content.
Use the debugger. Place a breakpoint just after the code obtains a paragraph, and then expand the properties in the debugger and dig into them until you find which is the property that contains the information that you are looking for. Then, use the value of such properties in your code.
Hi @Dhananjay Siwach ,
i suggest you could check the value step by step each lines. And do you have errors?
Best regards,
Yijing Sun