Azure Databricks
An Apache Spark-based analytics platform optimized for Azure.
2,514 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EB%3C/text%3E%3C/svg%3E)
When writing to parquet, I am getting an extra empty file created alongside the folder with data.
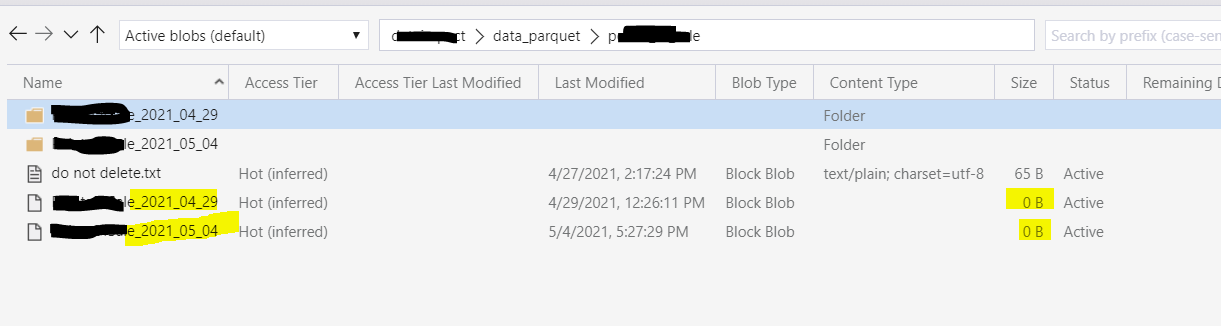
I do not need it, causing mess only.
Here are the commands I tried, and got this file in both.
output_path = "/mnt/cointainer/folder/subfolder/sub_subfolder_" + currentdate
....
childitems.write.mode('overwrite').parquet(output_path)
or
output_path = "/mnt/cointainer/folder/subfolder/sub_subfolder_" + currentdate
....
childitems.write.format("parquet").mode('overwrite').save(output_path)
How to get rid of this unwanted file?

Hello @braxx ,
Thanks for asking and using Microsoft Q&A.
This is an expected behaviour when run any spark job to create these files.
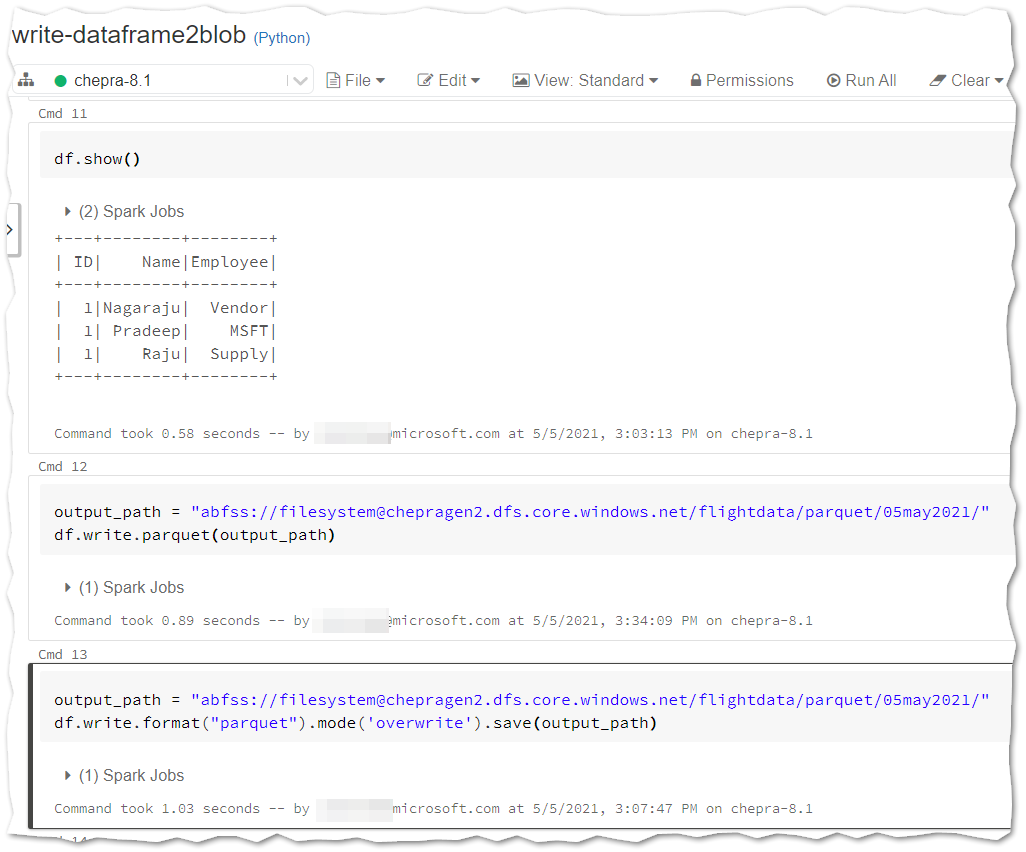
Expected output:
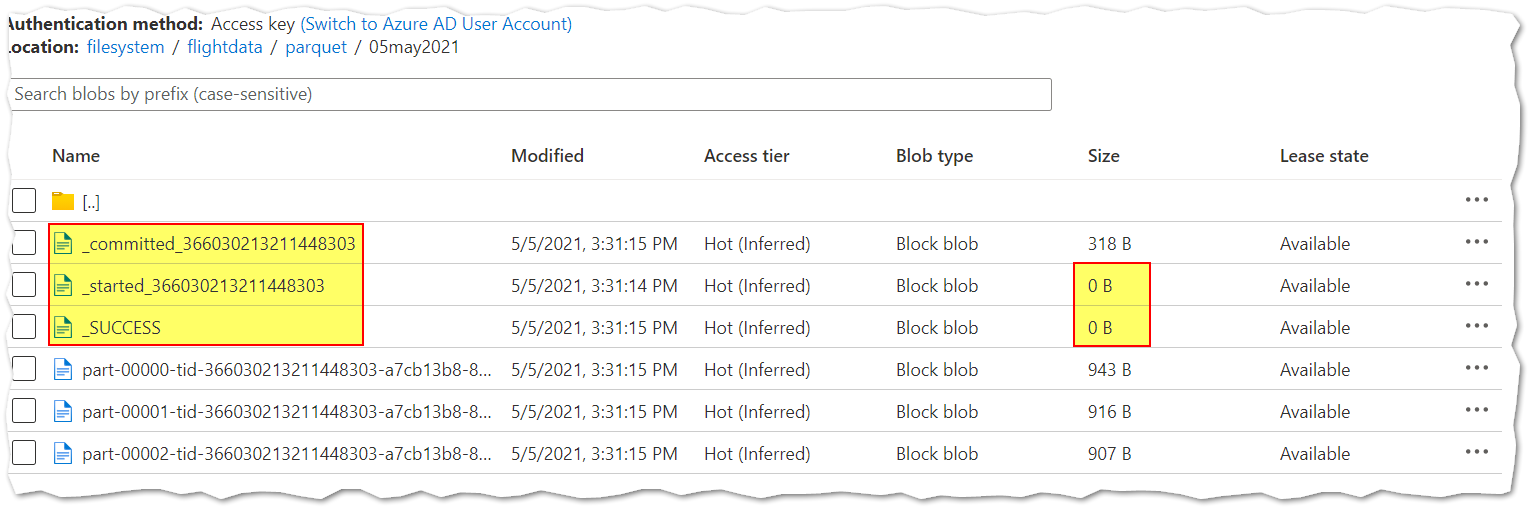
When DBIO transactional commit is enabled, metadata files starting with started<id> and committed<id> will accompany data files created by Apache Spark jobs. Generally you shouldn’t alter these files directly. Rather, use the VACUUM command to clean the files.
A combination of below three properties will help to disable writing all the transactional files which start with "_".
spark.sql.sources.commitProtocolClass =
org.apache.spark.sql.execution.datasources.SQLHadoopMapReduceCommitProtocol
This will help to disable the committed<TID> and started<TID> files but still _SUCCESS, _common_metadata and _metadata files will generate.
parquet.enable.summary-metadata=false
mapreduce.fileoutputcommitter.marksuccessfuljobs=false
For more details, refer "Transactional Writes to Cloud Storage with DBIO" and "Stop Azure Databricks auto creating files" and "How do I prevent _success and _committed files in my write output?".
Hope this helps. Do let us know if you any further queries.
------------
Please don’t forget to Accept Answer and Up-Vote wherever the information provided helps you, this can be beneficial to other community members.
Thank you for the explanation. That's helpfull for sure although my case is slightly different.
You simply explained what is inside a folder created by databricks.
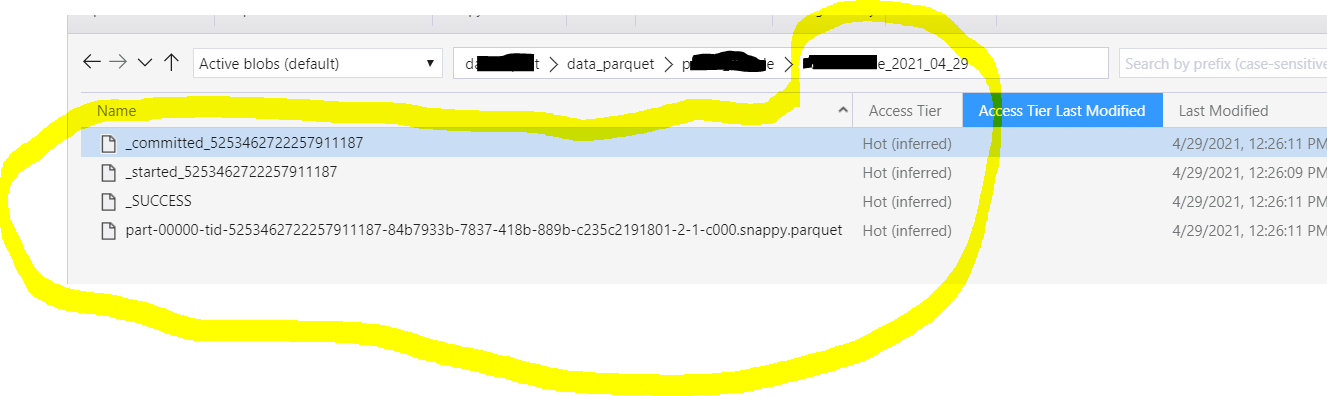
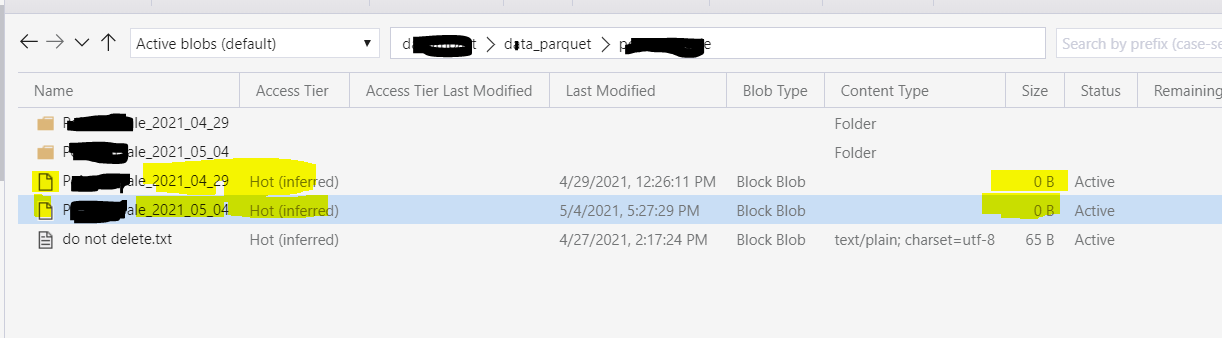
I am ok with that and understand it. But now, If go one level up, outside the folder I see there is an empty blob with the same name as a folder. It is created alongside the folder, not inside. See on the screen, marked at yellow
Hello @braxx ,
This looks strange. I could not find any files created outside the folder.
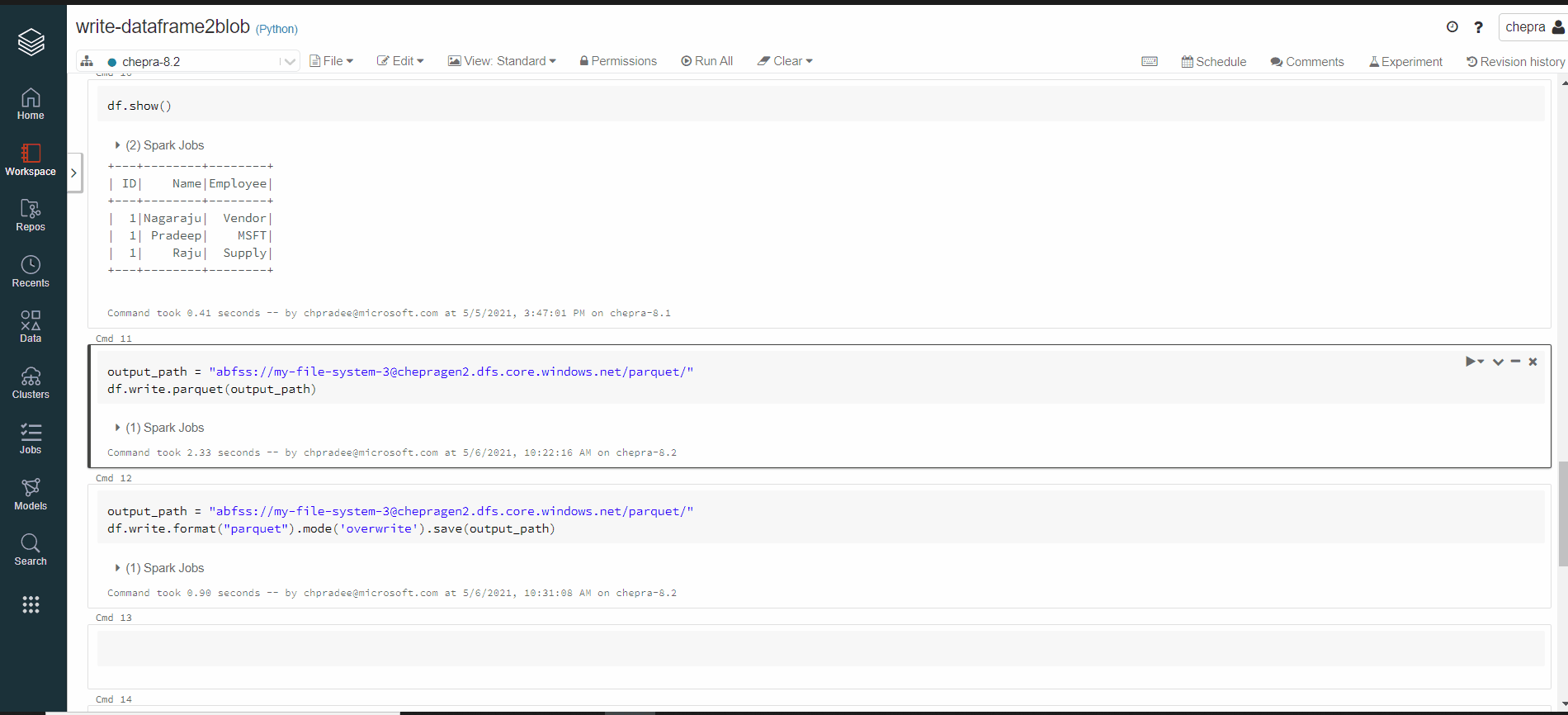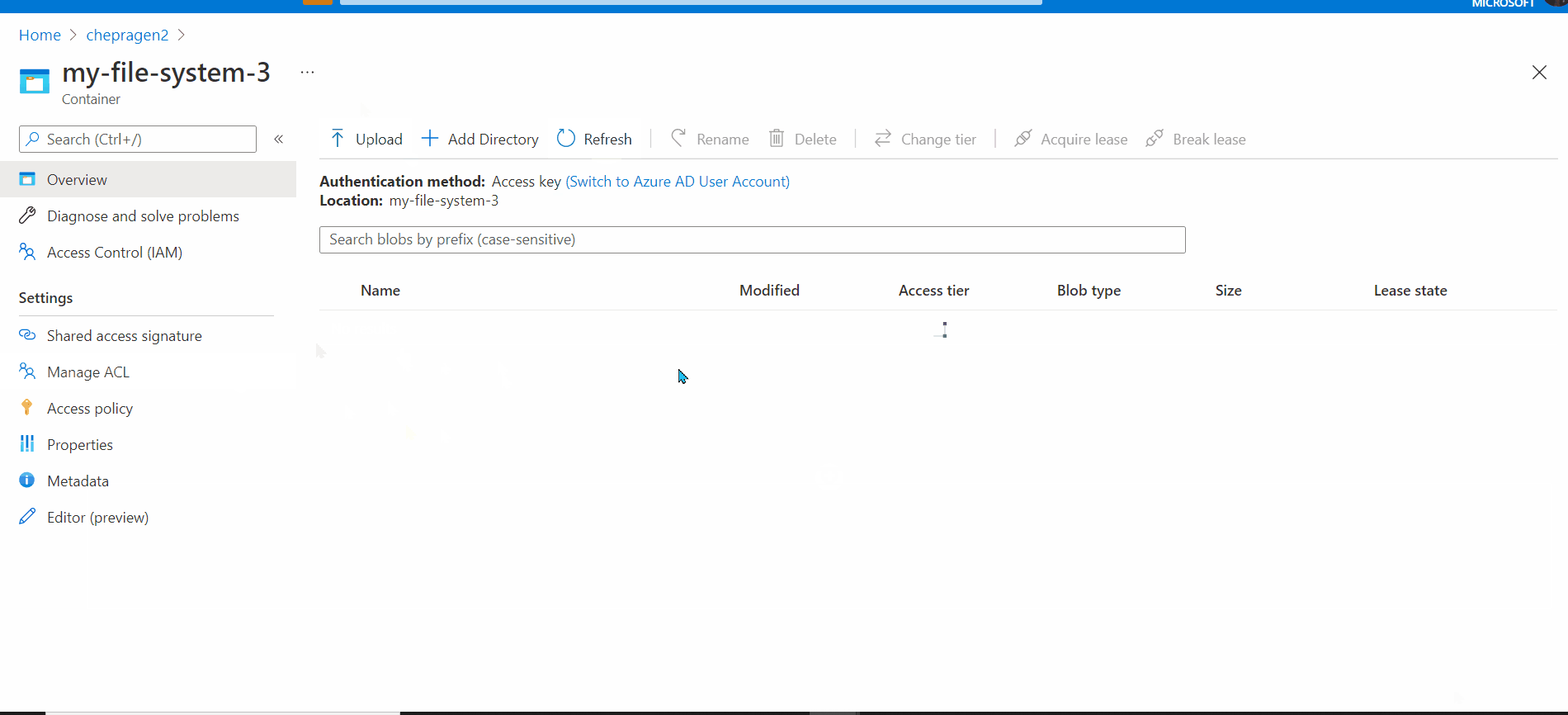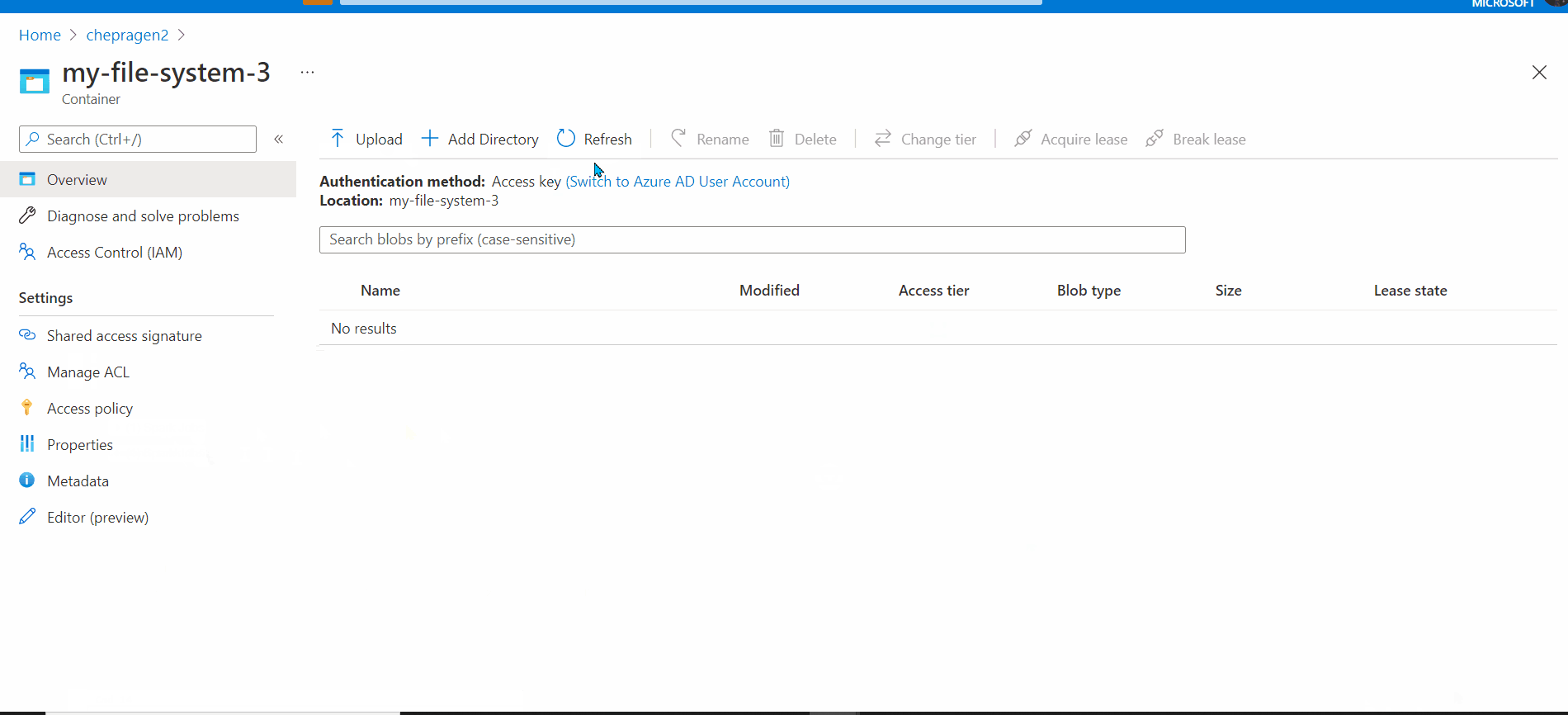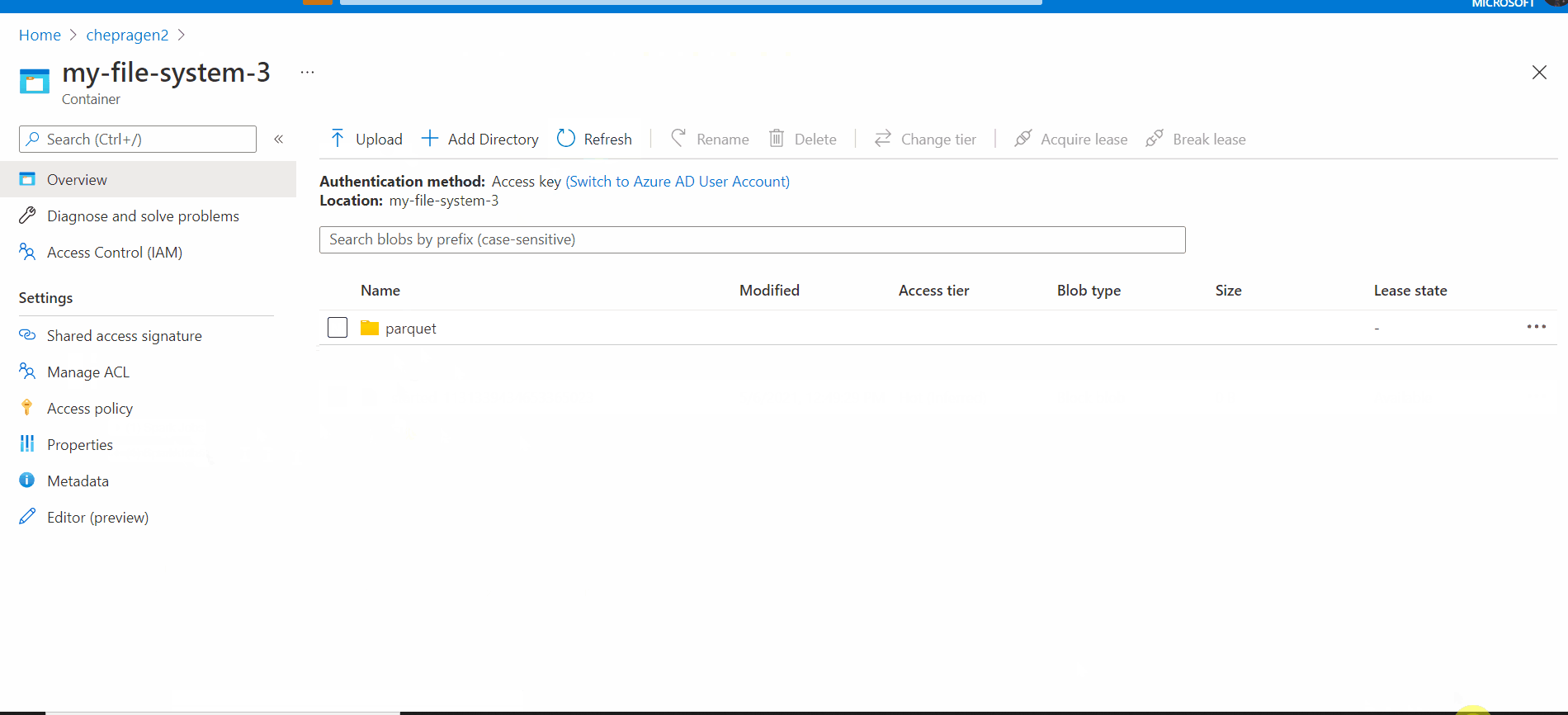
In order to investigate further, could you please share the Databricks runtime version which you are using? And the sample dataset to repro your scenario?
sure, appreciate your help.
steps to reproduce the issue:
here is what i suppose is a runtime version: DBR 6.4 | Spark 2.4.5 | Scala 2.11
but i think running this on different cluser cause the same issue.
What is weird, when i delete the empty blob, the whole folder is deleted also
@PRADEEPCHEEKATLA were you able to reporduce the issue?
Hello @braxx ,
Thanks for the sharing the details and I will try to repro this issue and I will let you know the findings.
For a deeper investigation and immediate assistance on this issue, if you have a support plan you may file a support ticket.
Hello @braxx ,
I had tested with provided sample data and the notebook provided and I was able to see the expected files.
Tested on runtime version: DBR 6.4 | Spark 2.4.5 | Scala 2.11
Note: Unfortunately I could not find any files created outside the folder.
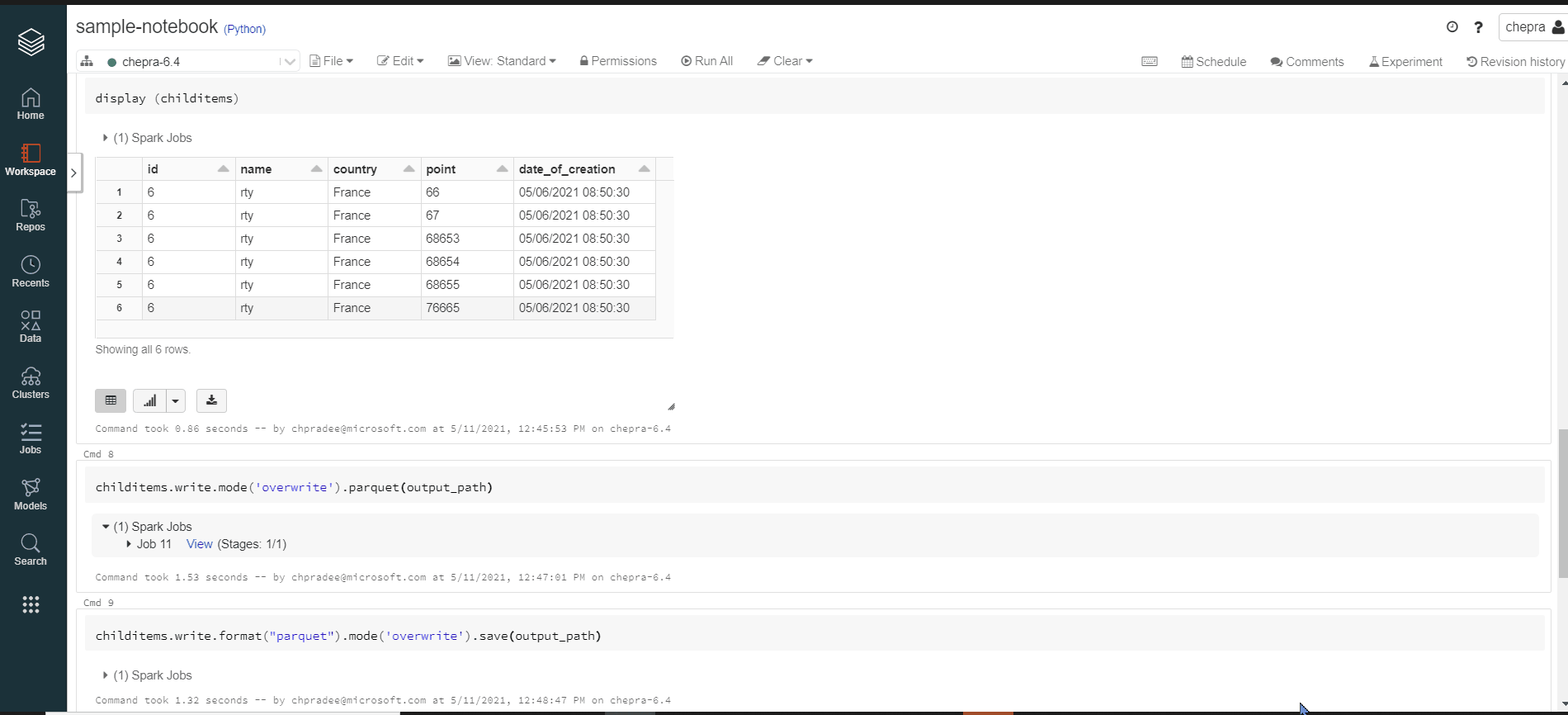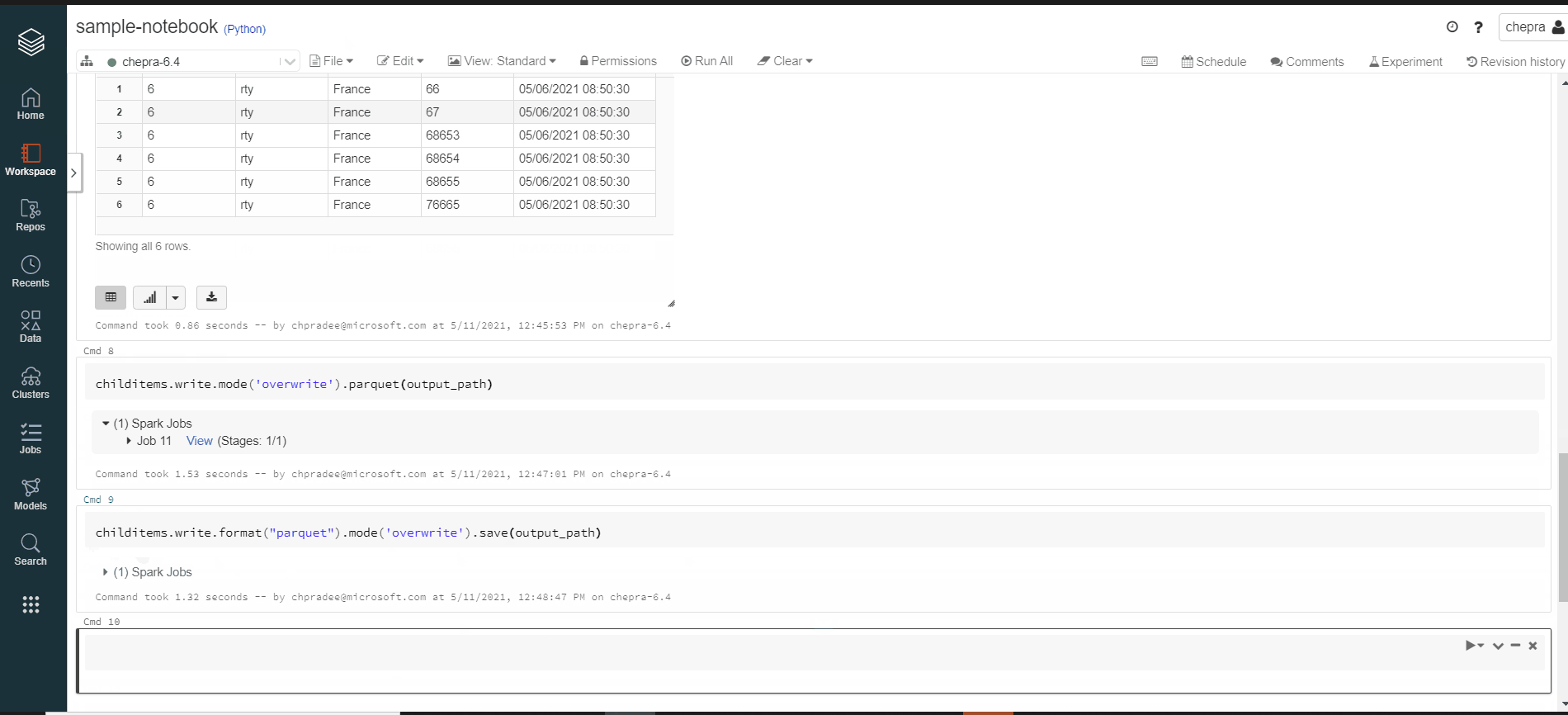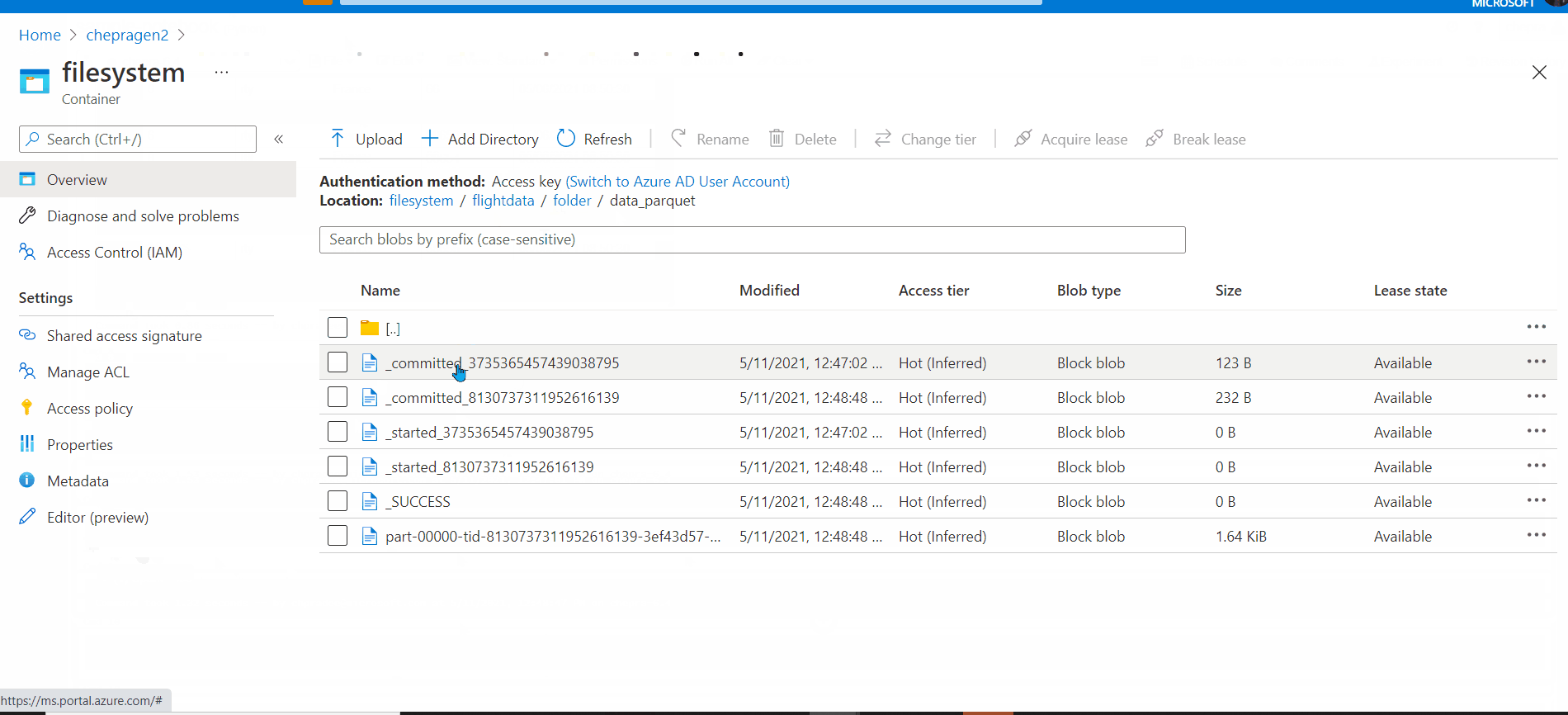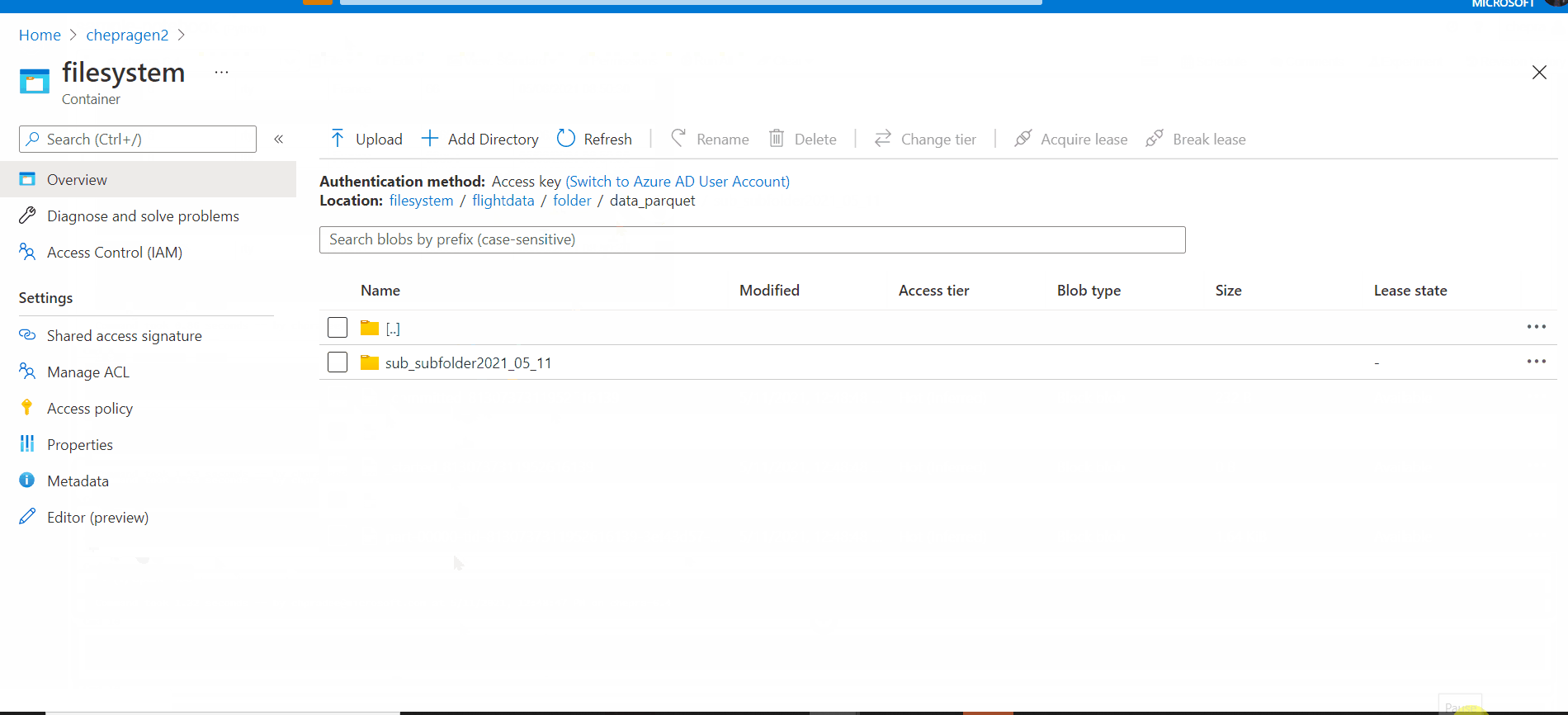
For a deeper investigation and immediate assistance on this issue, if you have a support plan you may file a support ticket.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EKS%3C/text%3E%3C/svg%3E)
Hello @braxx have you find any solution to regarding this problem in which files are creating outside
Thank you for your effort. Really appreciate it. Here is a related thread. Also not solved. Would it be possible to report it as bug to investigate by product team etc?
databricks-dbutils-creates-empty-blob-files-for-az.html
Maybe it is related to how I mounted the container?
storagename = "AAAA"
containername = "BBBB"
saskey = dbutils.secrets.get(scope = "CCCCC", key = "DDDD")
dbutils.fs.mount(
source="wasbs://" + containername + "@" + storagename + ".blob.core.windows.net/",
mount_point = "/mnt/" + containername + "/",
extra_configs = {"fs.azure.sas." + containername + "." + storagename + ".blob.core.windows.net":"" + saskey +""})