Not Monitored
Tag not monitored by Microsoft.
37,794 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3ERJ%3C/text%3E%3C/svg%3E)
I have a problem with one of these – trying to reproduce the structure in attached .pdf in PBI via cleaning it in PQ, no way to access the data differently. How would you tackle it ? I believe that it’s the whole range of difficulties : offset columns (data scattered throughout many adjacent columns), text cleaning (some fields merged with relevant content), some immaterial information to get rid of (like the last Page or top portion of first Page). I am thinking of generalizing the possible solution as much as possible, since getting similar .pdf is periodic event.
When I compare how things look through the connector versus how they look in the PDF I notice that there’s quite few values that either get concatenated with other fields and the rest of the rows don’t, or somehow there are missing values in some fields because they were concatenated in others. This situation in itself would prevent me from ever reaching our desired solution. Here’s a screenshot of one of those values.
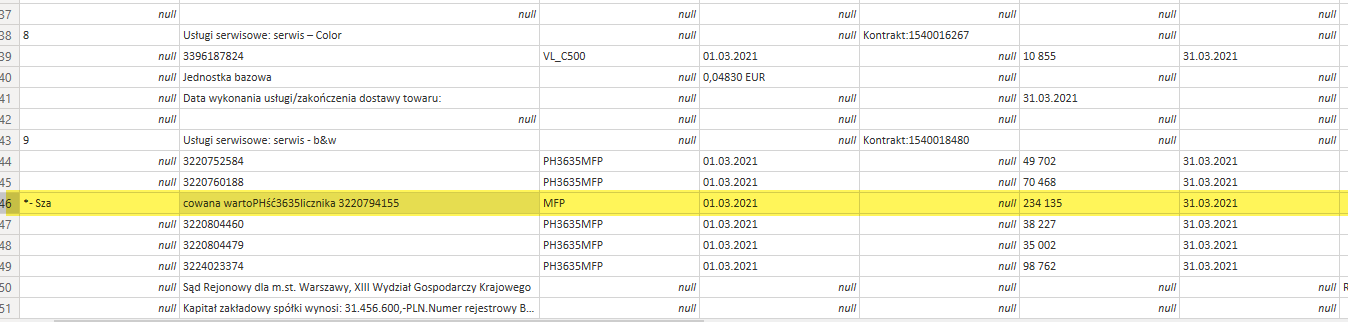
I would like to attach an original file, yet I cannot upload a .PDF with a message "No such upload"
Best
Rafal
@Ehren (MSFT) - shared additional info in reply to comment
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EEM%3C/text%3E%3C/svg%3E)
Thanks for reporting this. Can you share the M for the Pdf.Tables step? Also, you should be able to share a OneDrive link or something similar.
Źródło = Pdf.Tables(File.Contents(FileLocXerox), [Implementation="1.2"])

@Rafał Jagniewski . The above link requires credentials. Could you try again i.e. with OneDrive?
https://www.dropbox.com/s/xzz8r0p8bv3xfzx/Inv1590274608.PDF?dl=0
via dropbox this time
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EDP%3C/text%3E%3C/svg%3E)
Thank you for your bug report. A fix for that extra text appearing out of nowhere will be included in Implementation 1.3 of Pdf.Tables which will released/be default in the July 2021 release of Power BI. (Sorry, that's how long the release cycle is.)
The technical explanation is that as you may have noticed, you can get that same text when copy and pasting out when looking at the PDF in Adobe Reader because the text really is in the PDF, but isn't visible because the background of the table is drawn on top of it. I added some logic to ignore text that gets drawn over when extracting tables.
I understand that even with that bug fix, cleaning the data in that PDF is complicated, and it would be great if I could get Power BI to help more with that, but I think I got it to the point where it's not doing anything obviously wrong on importing the text as a table.