Azure Computer Vision
An Azure artificial intelligence service that analyzes content in images and video.
380 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EJS%3C/text%3E%3C/svg%3E)
Hi, I'm using read API to extract typed and handwritten text from pdf. When pdf is scanned, all is working as expected. However if pdf is already OCRed, then json response of extracted text has duplicated words and phrases (with some duplicates containing typos, example attached). These duplicated appear on the same line. If I convert such pdf to image first, this problem doesn't occur. Is there a way to overcome this step of converting pdf to image by passing some additional argument or some other solution? We can't control the type of pdf being sent to us.
Attached is an example screenshot of output with duplications.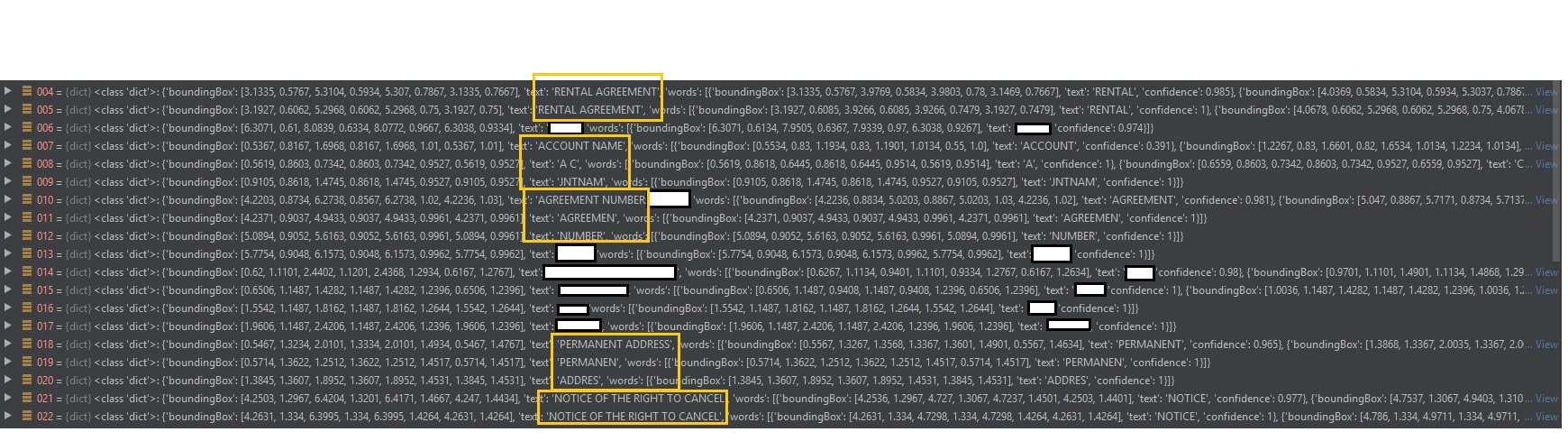
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3ERM%3C/text%3E%3C/svg%3E)
@Julia Sizova Thanks for the question. Can you please share the sample pdf is already OCRed that you are trying, also please add more details about the Read API and OCR API version that you are trying.
The Computer Vision Read API is Azure's latest OCR technology (learn what's new) that extracts printed text (in several languages), handwritten text (English only), digits, and currency symbols from images and multi-page PDF documents. It's optimized to extract text from text-heavy images and multi-page PDF documents with mixed languages. It supports detecting both printed and handwritten text in the same image or document.
Please follow the Read API v3.2:https://centraluseuap.dev.cognitive.microsoft.com/docs/services/computer-vision-v3-2/operations/5d986960601faab4bf452005
Unfortunately, I can't share this document, as it has sensitive information. I've tried several ways to reproduce this problem with redacted document, but didn't succeed. If blacking this info out on original pdf, it's not visible on pdf itself but is still returned from the Azure API. I've also tried to convert this document to image, remove sensitive info and then OCR again, but then the problem with duplications disappears. Making up a new example document also doesn't reproduce the problem.
The API we are using is 'https://{name}/vision/v3.0/read/analyze?language=en' to submit request and 'https://{name}/vision/v3.0/read/analyzeResults/' to get response.
@Julia Sizova ·Thanks for the update. We would recommend to raise a Azure support desk ticket from Help+Support blade from Azure portal for your resource if you have a support plan for your subscription. This will help you to share the details securely and work with an engineer who can provide more insights about the issue that if it can be replicated.