Azure App Service
Azure App Service is a service used to create and deploy scalable, mission-critical web apps.
7,149 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EMR%3C/text%3E%3C/svg%3E)
I have a number of AppServices running with health-checks turned on. I recently created a new one based on the same template, and for some reason its health checks seem to constantly spike, running a full order of magnitude more frequently than the other.
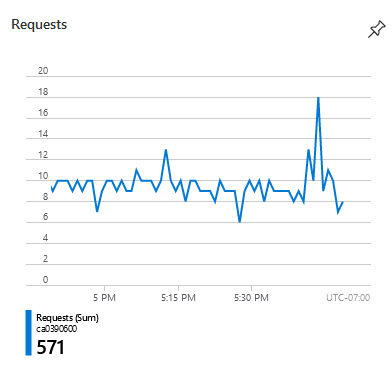
As an example, in the last hour, each of my other AppServices have received approximately 600 health check requests (there are 10 instances running).
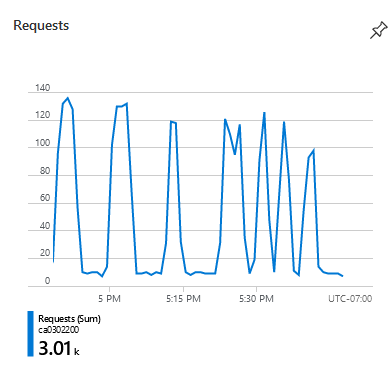
The AppService in question has received 2700 health check requests in that same amount of time. It's on the same AppService Plan.
This can also be visualized pretty easily by looking at the requests graph for the App Service.
Good:
Bad:
Is there some setting I can tweak to bring this request load down? It seems pretty absurd to check the health of a service 3000 times an hour.
Hi Grace,
It was still happening, but your answer was very helpful. I had been checking logs for failed requests and not seeing any, but I changed my AppInsights query to look for any request that wasn't 200 and found that I was getting a deluge of 307s.
It turns out the AppService's TLS settings were incorrect - they were not set for HTTPS-only so the app was attempting health checks over normal HTTP. Changed HTTPS-Only to ON and the requests dropped after a few minutes.
Thank you.
MR

Hi @Matt Robold (WCSG) ,
Thanks for the update and for sharing what worked for you. Glad to hear your issue has been resolved
-Grace
Hi @Matt Robold (WCSG) ,
Thanks for bringing this to our attention this is definitely odd behavior. Are you still experiencing this issue? What was the response status code for the AppService in question? Did you get ping failures from any of your instances?
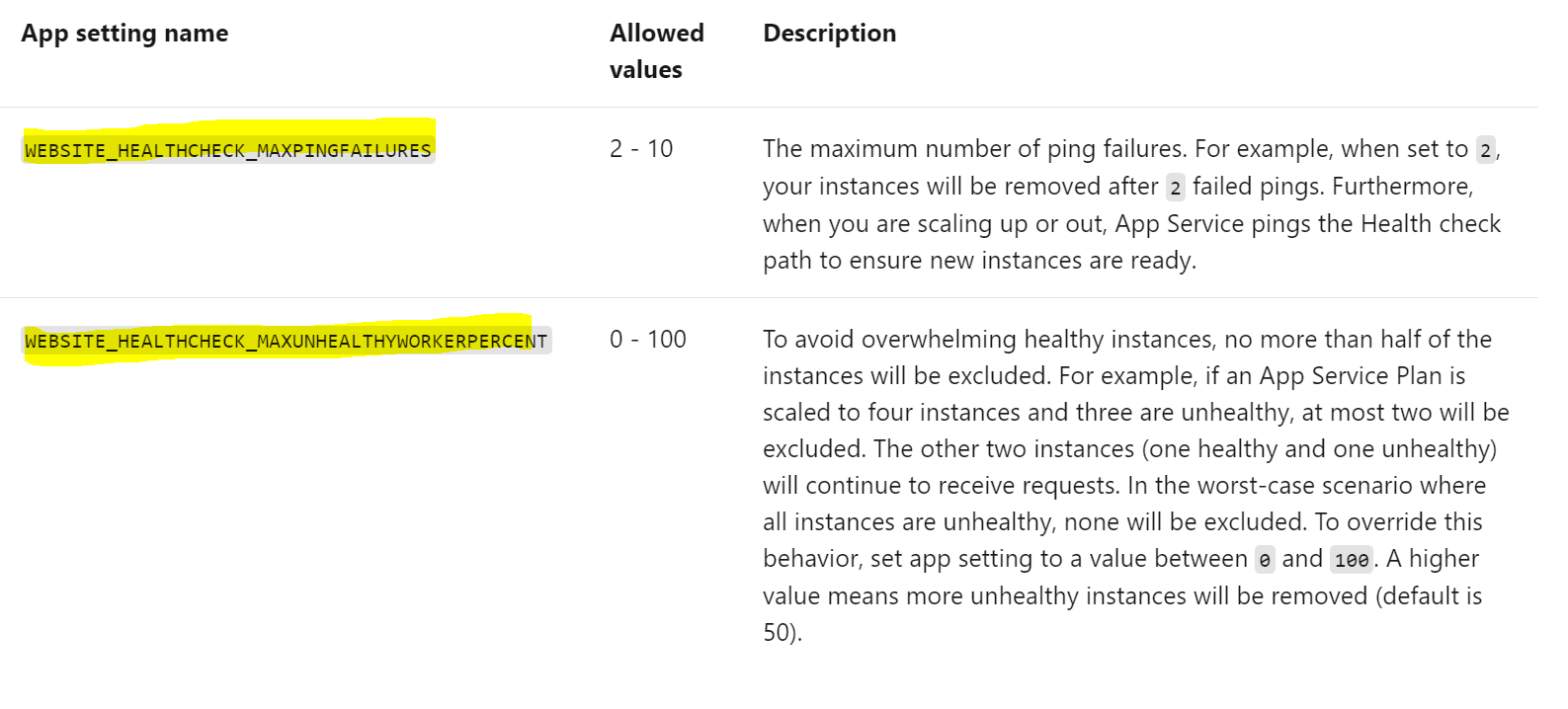
Usually, if an instance doesn't respond with a status code between 200-299 (inclusive) after two or more requests, or fails to respond to the ping, the system determines it's unhealthy and removes it. After removal, Health check continues to ping the unhealthy instance. If it continues to respond unsuccessfully, App Service restarts the underlying VM in an effort to return the instance to a healthy state.
If an instance remains unhealthy for one hour, it will be replaced with new instance.
Here are some app settings configurations you can add:
Let us know if you have further questions.
Best,
-Grace