Microsoft Security | Microsoft Graph
An API that connects multiple Microsoft services, enabling data access and automation across platforms
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EA%3C/text%3E%3C/svg%3E)
Hello. I'm trying to send email using graph api.
The reason I use graph api, instead of other options, is that it can send mail with attachment that's has more than 10mb file size.
After researching about this, I found out that I have to create an upload session(https://learn.microsoft.com/en-us/graph/outlook-large-attachments?tabs=http). and it's quite tricky to understand.
The goal is send an email with attachments that has more than 10mb file size.
so should I send two requests like this? and
first request :
POST https://graph.microsoft.com/v1.0/user/jaesung.park/messages/AAMkADI5MAAIT3drCAAA=/attachments/createUploadSession
POST https://graph.microsoft.com/v1.0/users/******@streami.co/sendMail
How can tell 'sendMail' that it should refer createUploadSession before send email?
Following is my send email code, it will be very helpful, if you can be specific by giving detailed python code examples
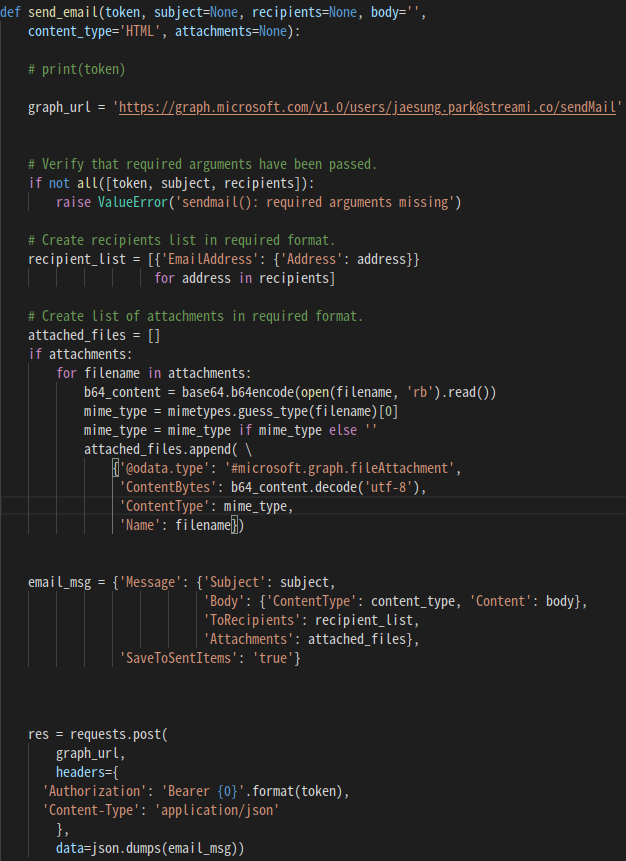
If there's a way that's more simple than this(https://learn.microsoft.com/en-us/graph/outlook-large-attachments?tabs=http), please let me know!
Thanks in advanace
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3ESC%3C/text%3E%3C/svg%3E)
Try this if it helps
Create the upload session:
filename = 'Large File.txt'
result = requests.post(
f'{ENDPOINT}/createUploadSession',
headers={'Authorization': 'Bearer ' + access_token},
json={
'@microsoft.graph.conflictBehavior': 'replace',
'description': 'A large test file',
'fileSystemInfo': {'@odata.type': 'microsoft.graph.fileSystemInfo'},
'name': filename
}
)
upload_session = result.json()
upload_url = upload_session['uploadUrl']
This request will return information about the setting including the URL where we will send the file chunks.
Now calculate the number of chunks you will need to send:
st = os.stat(filename)
size = st.st_size
CHUNK_SIZE = 10485760
chunks = int(size / CHUNK_SIZE) + 1 if size % CHUNK_SIZE > 0 else 0
The documentation recommends a 10MB chunk size for most cases, but you may want to adjust this.
Now upload the chunks:
with open(filename, 'rb') as fd:
start = 0
for chunk_num in range(chunks):
chunk = fd.read(CHUNK_SIZE)
bytes_read = len(chunk)
upload_range = f'bytes {start}-{start + bytes_read - 1}/{size}'
print(f'chunk: {chunk_num} bytes read: {bytes_read} upload range: {upload_range}')
result = requests.put(
upload_url,
headers={
'Content-Length': str(bytes_read),
'Content-Range': upload_range
},
data=chunk
)
result.raise_for_status()
start += bytes_read
Follow Example 2 and 3 of this documentation to continue uploading byte ranges until the entire file has been uploaded.
Thanks!