Azure Synapse Analytics
An Azure analytics service that brings together data integration, enterprise data warehousing, and big data analytics. Previously known as Azure SQL Data Warehouse.
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EA%3C/text%3E%3C/svg%3E)
I have the following SparkSQL (Spark pool - Spark 3.0) code and I want to pass a variable to it. How can I do that? I tried the following:
#cel 1 (Toggle parameter cell):
%%pyspark
stat = 'A'
#cel2:
select * from silver.employee_dim where Status= '$stat'
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EMO%3C/text%3E%3C/svg%3E)
If anyone happens to stumble to this again. A preferred solution might be close to what Anaid suggested:
myVar = 'test'
spark.conf.set("myapp.myVar", myVar)
%sql
SELECT * FROM myTable WHERE myVal = '${myapp.myVar}'
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EH%3C/text%3E%3C/svg%3E)
Hello @,
Thanks for the ask and using the Microsoft Q&A platform .
I tried the below snippet and it worked , Please do let me know how it goes .
cell1
%%pyspark
tablename = "yourtablename"
cell2
%%pyspark
query = "SELECT * FROM {}".format(tablename)
print (query)
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName("sample").getOrCreate()
df2 = spark.sql(query)
df2.show()
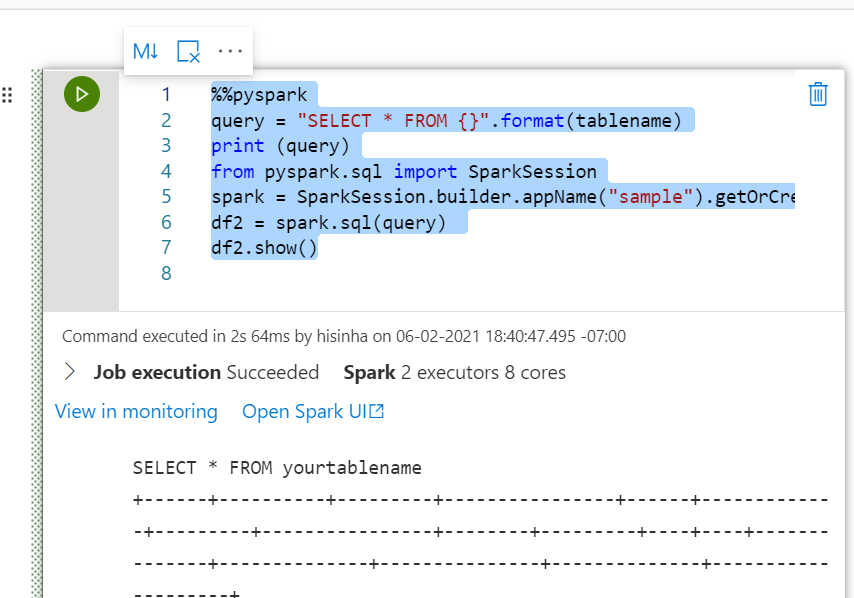
Thanks
Himanshu
Please do consider clicking on "Accept Answer" and "Up-vote" on the post that helps you, as it can be beneficial to other community members
Hi Himanshu,
Thank you for your reply. But we would like to keep the second cell as SQL.
We are evaluating to migrate some Databricks notebooks to Spark pool. For example:
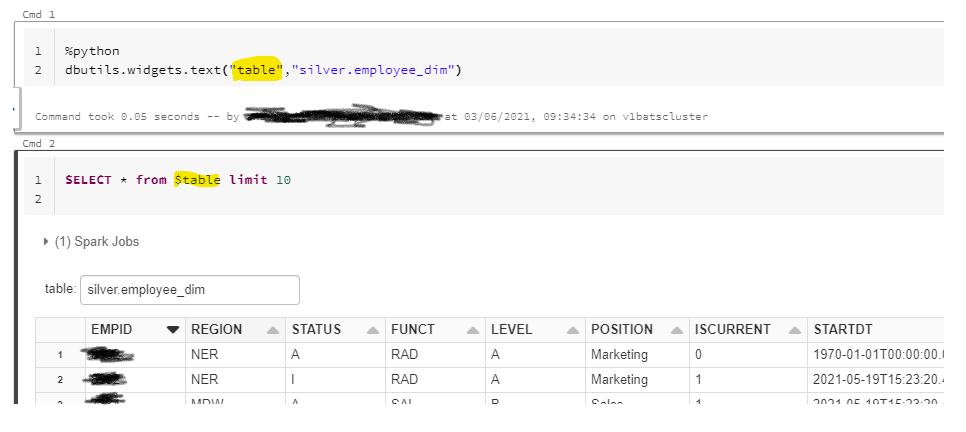
Thanks
I found this solution. However, I don't know if it is the best solution:
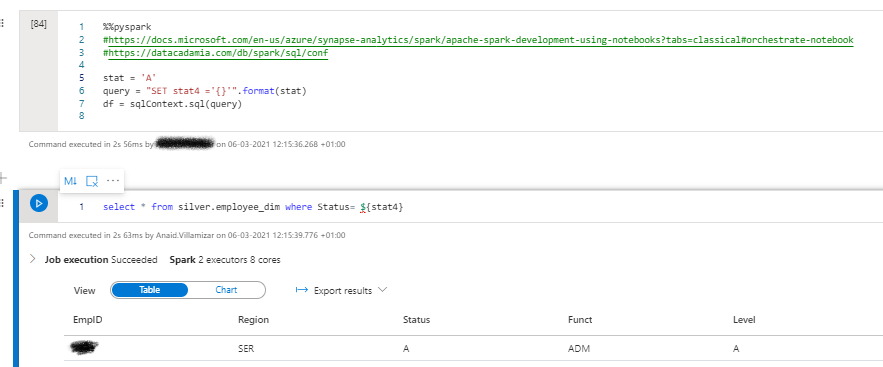
Hello @Anonymous ,
It was great to know that you were able to get to a resolution .
Thanks
Himanshu