Azure Machine Learning
An Azure machine learning service for building and deploying models.
3,334 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EMZ%3C/text%3E%3C/svg%3E)
Hi,
I am coming across an issue to do with retaining the datetime values in the datasets that I have uploaded to AzureML.
This issue can be replicated in the following ways:
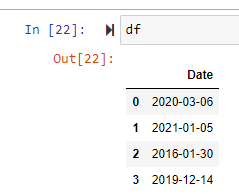
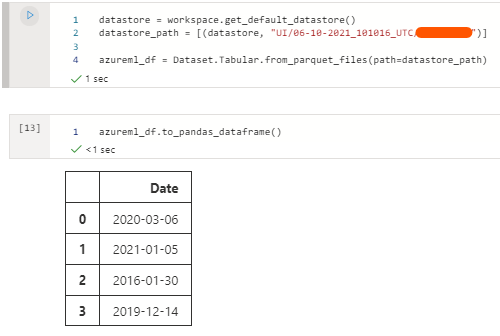
datastore = workspace.get_default_datastore()
datastore_path = [(datastore, "filename.parquet")]
azureml_df = Dataset.Tabular.from_parquet_files(path=datastore_path)
Printing the dataframe results in the following:
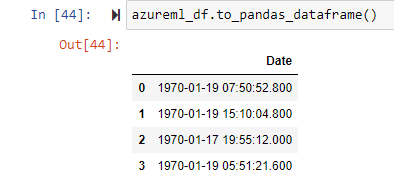
The datetime values are now different.
To investigate further, we can cast the datetime to int:
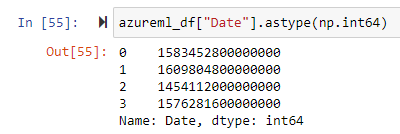
which gives us a 15 digit number.
We also cast the original df to int:
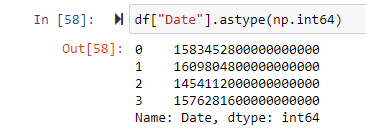
which instead gives us an 18 digit number.
This 18 digit number represents the number of nanoseconds since UNIX epoch. Three trailing zeroes are stripped from the number when creating the Tabular Dataset object through azureml-sdk, resulting in an incorrect datetime being read. Keep in mind that if you were to download the parquet from Azure Blob, the values are still intact, meaning the issue is with AzureML and potentially the Dataset method, from_parquet_files. A simple workaround would be to multiply this column by 1000 then convert it back to datetime again but I would like to know if there's something I'm missing in between reading the parquet from AzureML or if the problem is on Azure's side.
Regards,
Muhammad

@Muhammad Zainal Thanks for the detailed explanation of the issue. I have tried to replicate this issue with the exact steps but the date in does not change to a different value as seen in your case. Here are the steps:
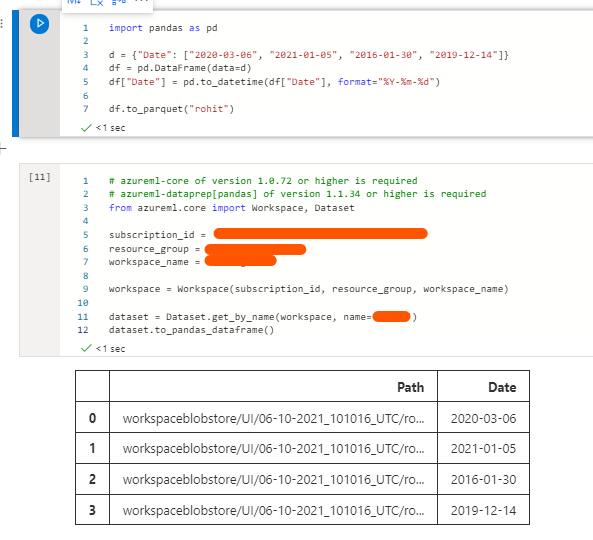
With the exact same steps too the date is consistent.
Maybe there is an issue with one of the SDK version. Which version of the SDK are you using?
@romungi-MSFT Thanks for the prompt reply. I am using conda 4.10.1 to build my environment from the following environment.yml file.
name: datetime_env
channels:
- defaults
dependencies:
- python=3.7
- pandas=1.2.2
- notebook==6.4.0
- pip=21.1.1
- pip:
- azureml-core==1.30.0
- azureml-dataset-runtime==1.30.0
- catboost==0.26
@Muhammad Zainal I have tried to replicate the scenario with a similar environment but did not see the same behavior. I would recommend to post the same details of reference this thread on the issues page of Azure python SDK repo here so the SDK team could take a look at it. Thanks!!
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EHN%3C/text%3E%3C/svg%3E)
I'm facing the same problem. I'm using PythonScriptStep to create pipeline and PipelineData to get the output of the pipeline. The output has the right datetime, but once I registered that output data as a dataset in AzureML, the datetime is incorrect when I read it.
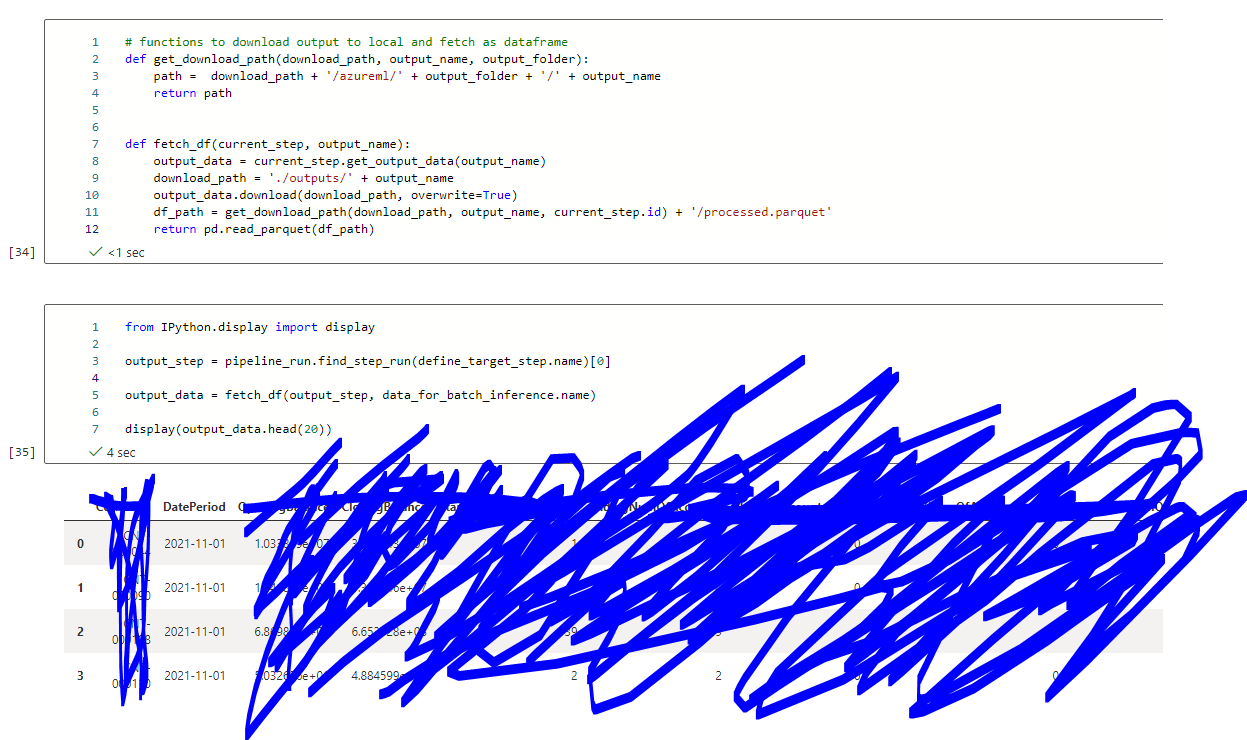
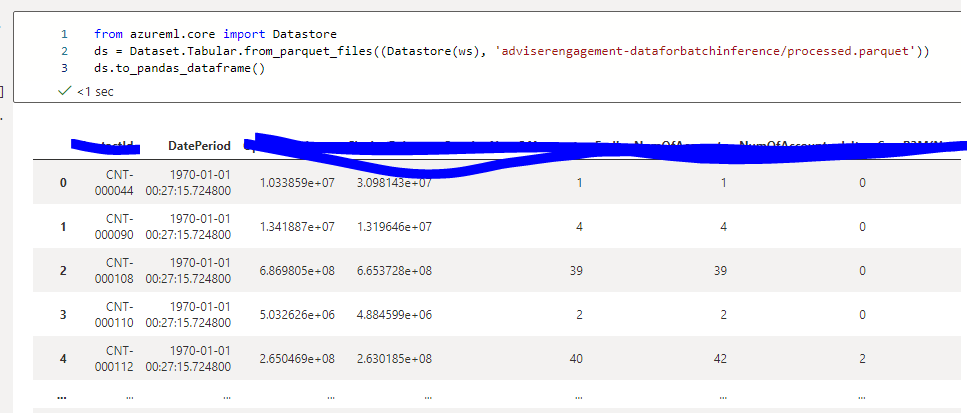
As for the environment, I specified as below:
pyarrow 3.0.0
pandas 0.25.3
azureml-core 1.34.0
python 3.6.9
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3ET%3C/text%3E%3C/svg%3E)
I have the same issue when running the following code on the ML notebook.

It was fine until yesterday and suddenly started happening today.
We can see the expected timestamp by converting it to datetime64 and then multiplying by 1000, but we would like know why it happens and don't want to have unexpected thing like this in the future or internally in the pipeline.
Please investigate if something has changed within the aml dataset and casting the datatype, etc.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3ERF%3C/text%3E%3C/svg%3E)
I'm seeing the same issue running PythonScriptStep in AzureML Pipelines.
I suspect it has something to do with the PyArrow representation of datetimes.