Not Monitored
Tag not monitored by Microsoft.
37,800 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.

Hi there,
Just wondering if anyone could assist me on the below exercise:
Highly appreciate for any suggestions!!

Hi @Xin
Given the challenge with >10M rows, if it was me, I would provide more info., i.e.:
Hope this makes sense
Hi, thanks for your reply.
Also PowerBI is an option but eventually we'd like the data to be in Excel for further processing (while I know PowerBI can export table and allow copy and paste but Excell seems one less step).
Given Table A is ALWAYS below 1 million rows, we should be able to load to table and copy and paste away.
Again thanks for your help
Hi @Xin
Technically the method is still try to cleanse table B to "exact" match with table A, just wondering if there is any function that would perform "contain" search (i.e. sub text string of B matches A). Not sure if that would drag the performance by too much?
Any existing or custom function involving something like "contains" can not work. As an example, if TableA has [Clean ID] 12345 and somewhere in TableB a [Complex ID] is something like "123456789*abc5489", **12345 would be found in that [Complex ID] and what you want is an EXACT match
Just wondering I can see a fx-rephrase being added. Therefore I assume this is to cleanse the ID in table B before can be looked up?
Not sure where you found fx-rephrase in what I uploaded. The function I created was named fxParseComplexID. If that's what you talk about, then Yes that's what the function does, inside query UnMatchedComplexClean
I think it works well so far but just also thinking there are probably 10,20 different ways how column B ID can be presented therefore shall I just keep adding cleanse methods?
Thank you very much for your reply. Just I was thinking within xlookup or vlookup, there is a way to write the formula like
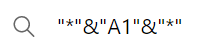
which basically allows me to lookup for same string as A1 cell but allow front and after to have some other text string, but didn't seem to find such similar lookup function in PQ? Basically trying to achieve lookup but allow front or after has other characters as long as part of the text string is A1.
Sorry, I didnot want to take too much of your time therefore just more asking (or exploring) for a possible approach like above rather than having to trouble you write up everything :) . I think if the above isnt possible in PQ for 1m column A + 12m column B then possibly we can break column B to like 12 different columns and perform such lookup 12 times in normal excel (just could be really slow and inefficient).
"shall I just keep adding cleanse methods" - I had a look at the fxParseComplexID formula and it seems to cleanse the data depends on how it's arranged? Then I just meant if I wan it to perform data cleansing over 20 possible forms of text string then just keep adding rows to structure different ways to cleanse different data form then?
Hi @Xin
I didn't come back on that point where you initially said this was working with XLOOKUP and wilcards. There's obvioulsy something I don't understand about your data. From what I understood re. what you wanted to acheive and with the few [Complex ID] you submitted, for me this can't work
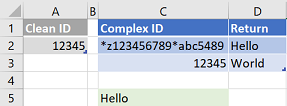
in C5 =VLOOKUP("" & A2 & "", C2:D3, 2, FALSE )
Given that you want an exact/perfect match, with the above example "World" should be return. But again I don't have a view on the actual data
Anyway. There isn't (as of today) any PQ function that allows using wildcards as above. Hence my approach with a custom function
Then I just meant if I wan it to perform data cleansing over 20 possible forms of text string then just keep adding rows to structure different ways to cleanse different data form then?
Again, it's not top clear to me - sorry. From what I seem to understand I would say Yes, but again that's based on what I think I understand
Apologies for the delay reply. Yes we did take the approach as in clean the ID in multiple ways!
Thank you so much for your help!
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3ES%3C/text%3E%3C/svg%3E)
Hi @Xin ,
As long as CleanID in Table A is always numbers, then I'd suggest trying the following (always in PQ):
1) in Table B add a costum column with the follwing formula: Text.Select([ComplexID], {"0".."9"}). This formula will extract only the numbers, ignoring everything else, into the new column.
2) You should then have [NewColumn1], the the CleanID, and [Column2], the info you want, in the same table.
Hope that works.
Thanks so much. We are trying that as well, the only prob is ID is not always just number so quite annoying dataset we have
Hi @Xin
Based on the very few examples of [Complex ID] you provided the query in this workbook does here
Test
I created a CSV of 1 Million of rows to test the performances of the Parsing function and in average the latter did the job in 12s (Intel Core I7 + SSD), including the preceeding Table.ReplaceValue ("*" with "-")
Settings
In the Query Options/CURRENT WORKBOOK
Suggestion
You intially said "data set 1 is around 1.5million rows", later you said "Given Table A is ALWAYS below 1 million rows"... In the event where some [Clean ID] would match more than one record (as in my example with [Clean ID] 123456789) in your TableB you'll likely exceed the max. number of rows of an Excel worksheet ==> Better you load to the Data Model (you can export tables from the Data Model as CSV with DAX Studio if necessary) from where you can setup a flattened Pivot Table that will be the same as the Table returned by the query
Hi there, thanks so much for your help!
Just wondering I can see a fx-rephrase being added. Therefore I assume this is to cleanse the ID in table B before can be looked up? I think it works well so far but just also thinking there are probably 10,20 different ways how column B ID can be presented therefore shall I just keep adding cleanse methods?
Technically the method is still try to cleanse table B to "exact" match with table A, just wondering if there is any function that would perform "contain" search (i.e. sub text string of B matches A). Not sure if that would drag the performance by too much?