' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3ES%3C/text%3E%3C/svg%3E)



14,494 questions
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3ESX%3C/text%3E%3C/svg%3E)
Hi @Senn ,
> But why did they mention in the task e.g. its hash index but calculated the B+ tree index?
Statistics are an important part of the entire process as they help the query optimizer to make the best guesses when accessing data. These statistics include information about columns like: estimated number of rows, the density of pages on disk, available indexes to use, etc. that the query optimizer uses to generate query plans. It’s essential to keep these statistics up-to-date as the query optimizer will use them to enforce query plans. But this is something that SQL Server does automatically and it also does an excellent job with default settings too, so you don’t have to worry about this except to know that it’s an important aspect.
Therefore, it can be said that it chooses the best calculation method according to the statistical information.
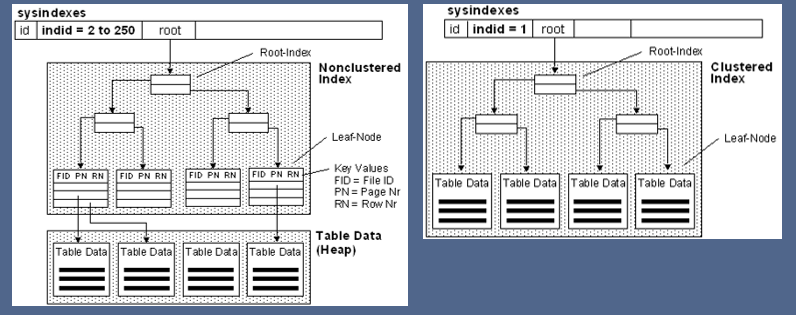
> The 2000 does it come from 100 byte * 20 data entries?
Yes. Please refer to this:https://my.vanderbilt.edu/cs265/files/2012/11/BplusTreeBasics3.pdf
Best regards,
Seeya