Azure Computer Vision
An Azure artificial intelligence service that analyzes content in images and video.
381 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.

Hi we try to read some text from screenshots,
but I recognize that the /vision/v3.2/ocr API has some issues recognizing text at all.
Is there an option to improve the API?
The following was not even in the result set:


And here it cannot identify the rn and reads m


@Grossmann, Tobias I would recommend to use the READ API which has a better accuracy than OCR and it is also asynchronous. You can use both handwritten and printed text to recognize the characters and set the language too in the request. For example, for the same images the response is very accurate. With a slightly better quality image I think you should see good results.
{
"status": "succeeded",
"createdDateTime": "2021-07-01T11:22:05Z",
"lastUpdatedDateTime": "2021-07-01T11:22:05Z",
"analyzeResult": {
"version": "3.2.0",
"modelVersion": "2021-04-12",
"readResults": [{
"page": 1,
"angle": 0,
"width": 639,
"height": 114,
"unit": "pixel",
"language": "de",
"lines": [{
"boundingBox": [5, 1, 32, 1, 32, 10, 5, 10],
"text": "mannich",
"appearance": {
"style": {
"name": "other",
"confidence": 0.878
}
},
"words": [{
"boundingBox": [5, 2, 31, 2, 32, 10, 5, 11],
"text": "mannich",
"confidence": 0.240
}]
}, {
"boundingBox": [5, 20, 23, 20, 23, 26, 5, 26],
"text": "weblich",
"appearance": {
"style": {
"name": "other",
"confidence": 0.878
}
},
"words": [{
"boundingBox": [5, 20, 23, 20, 23, 26, 5, 26],
"text": "weblich",
"confidence": 0.190
}]
}, {
"boundingBox": [5, 38, 33, 38, 33, 45, 5, 46],
"text": "Vorname",
"appearance": {
"style": {
"name": "other",
"confidence": 0.878
}
},
"words": [{
"boundingBox": [6, 38, 32, 38, 32, 46, 6, 46],
"text": "Vorname",
"confidence": 0.393
}]
}]
}]
}
}
Thanks a lot! I guess this API works also a bit diffrent?
POST: .cognitiveservices.azure.com/vision/v3.2/read/analyze?maxCandidates=5&language=de&model-version=latest
With the JPG as binary in body doesnt seems to work.
ax.post(computerVisionEndPoint + computerVisionEndPointOption,
req.body,
{
headers: {
'Ocp-Apim-Subscription-Key': computerVisionKey,
'Content-Type': 'application/octet-stream',
'Accept': '*/*',
'Accept-Encoding': 'gzip, deflate, br'
},
},`enter code here`
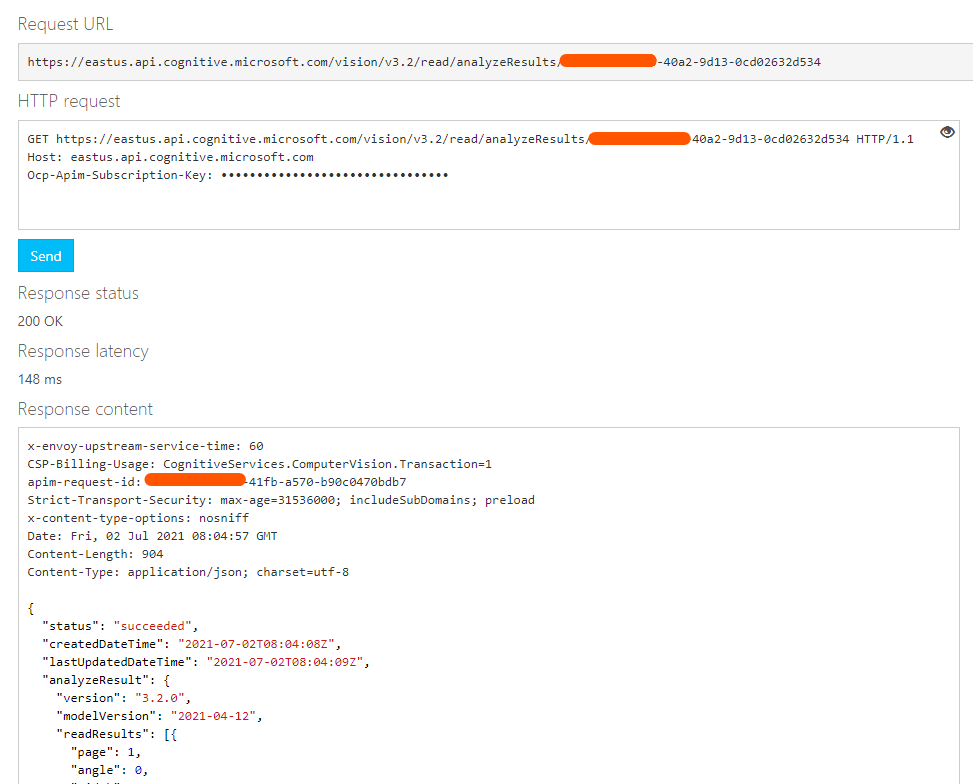
@Grossmann, Tobias Yes, you need to take the operation location or request id from the response and pass it to the GET READ RESULT API.
I have tried a quick scenario with a local image from postman and it works fine.
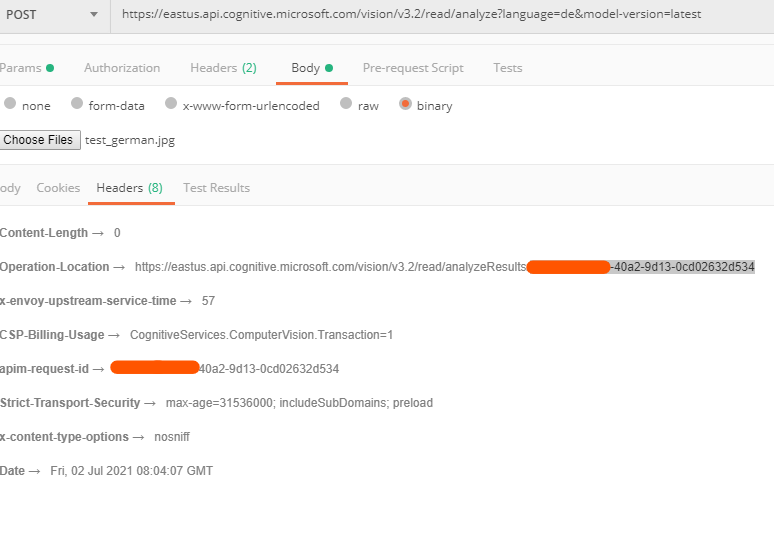
Getting the result with the request id.
I think this sample from github with python SDK should also help.
@Grossmann, Tobias Did you get a chance to try the scenario again and check if using binary worked for you?