Azure SQL Database
An Azure relational database service.
6,326 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EJV%3C/text%3E%3C/svg%3E)
I am joining together three different sources - 1 new an Excel file and a join of two existing tables in a SQL DB. Each has a sha256 hash of some identifying fields. There is only a very small number of rows (20) being inserted to the downstream tables. Then I rerun the pipeline to test to make sure I am identifying existing customers; so this doesn't seem like a row sampling issue since I am well below the 1000 rows in the sampling parameter. The existing (SQL Tables) feature is called id and the new (Excel) feature is called new_id.
When I do this join:
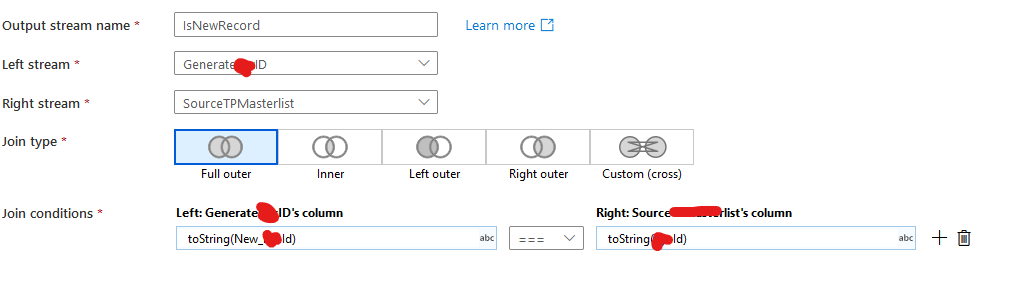
I get this cartesian, despite the IDs obviously matching. You can see the older file has the same ID and it simply won't match, regardless of the style of join I do, or type of equality (== or ===).
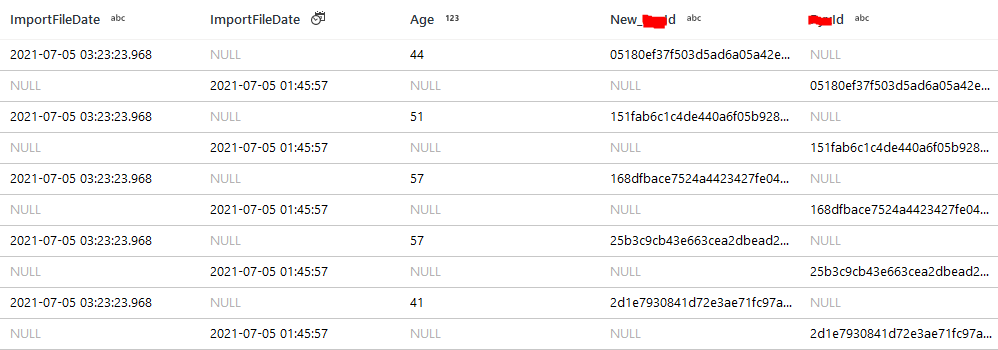
Doing this with an Exists transformation and the equality of the new and original id also returns zero rows. Left and Right joins match nothing but merge the respective other datasets columns, full of NULL. Even if I do left(new_id,10) == left(id,10) I still get nothing.
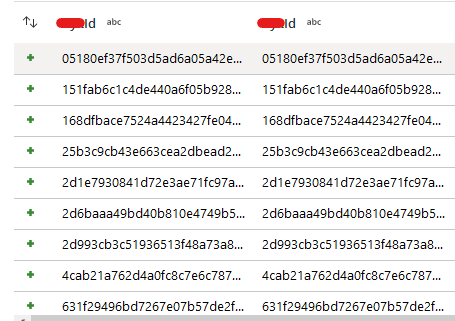
Even stranger, when I full-outer join the two existing SQL Tables together on the same id field (in Data Factory), they join together no problem: the full-outer join returns exactly what I expect.
Why would this do this?

Hi @Jeff vG ,
As below answer helps you. Could you please Accept Answer. Accepting answer helps community. Thank you.
Hi @Jeff vG ,
It would be great if you can accept answer. Accepting answer helps community. Thank you.
Hi @Jeff vG ,
Thank you for posting query in Microsoft Q&A Platform.
To get matching rows of id and newid you need to go with inner join with == condition as shown below.
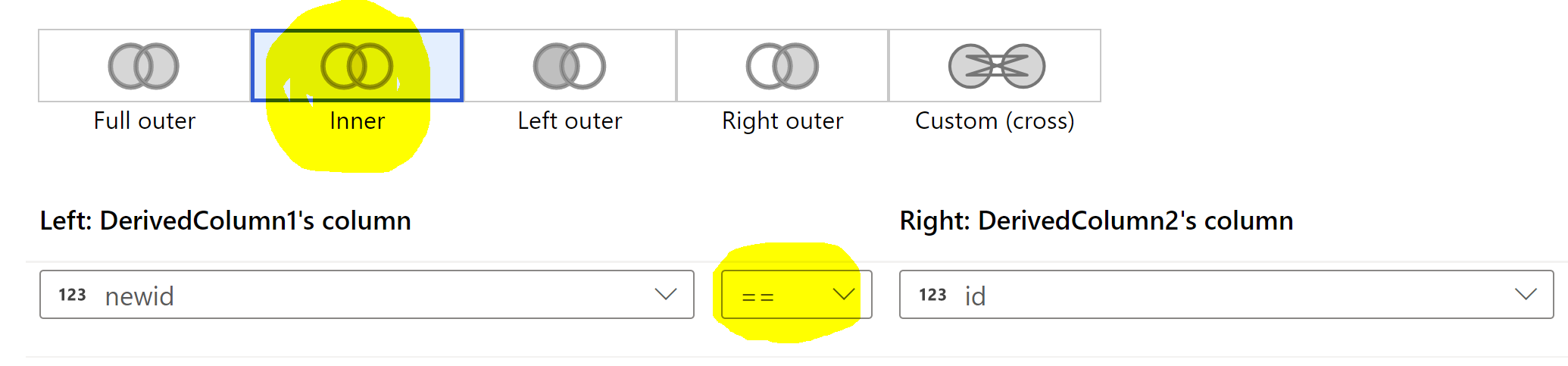
Hope this will help. Thank you.
------------------------------
accept an answer if correct. Original posters help the community find answers faster by identifying the correct answer. Here is how.
No, this doesn't work. The last image from my OP is a successful full-outer join on id and new_id, which for me are strings because they are sha256 (see table). the inner join you suggest (with ints) returns 0 row matches for me with sha256 strings, one from excel one from sql but "same" id.
I want all rows, matched and unmatched, from both sources. I use the NULLs generated by this to conditionally split the joined data later on.
full-outer between excel sourced new_id and sql sourced id returns 40 rows; if both sources are sql tables the full-outer join returns the expected 19 rows with id and new_id columns matched (single row per pair of id and new_id) and next to eachother. left- or right-joins return one column of id's both not the other and none of the other dataset. but this all works exactly as expect (with full outer join) when the two sources are sql.
the "Exists" function also does not identify the matching records by id==new_id (sha256 strings).
the issue here is something with the string type derived from excel source not matching string type persisted to sql table; appears to be same value but only matches when both sources of the join are sql tables.
Hi @Jeff vG ,
Thank you for clarification. Using "==" for full outer join should get you matching and non matching rows from both sources. I tried it worked fine for me.
Could you please try to restart your debug session or try to rename your source transformation and see. Thank you.
----------------------------------------
Please Accept Answer if it helps you. Thank you.
Full outer join with == gets me
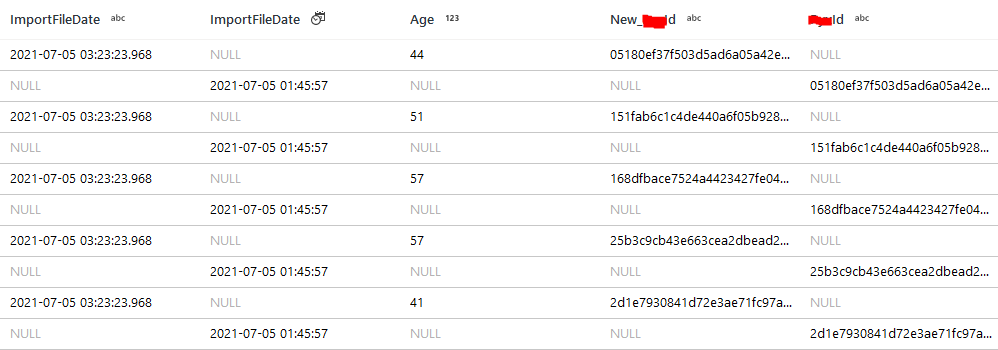
when joining between the Excel-source stream and the SQL-source stream.
Full outer join with == gets me
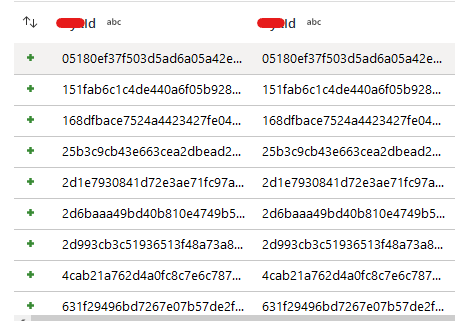
when joining between two SQL-source streams.
Same 19 rows in all 3 cases; same ID values, but called id for the SQL table and new_id for the records extracted from the Excel tab; all three sources have the id as a string, but just in case I have tried to cast as string as well, "toString(id) == toString(new_id)". I even tried to re-hash the hashed IDs, and that doesn't work either - is something added to the bytes extracted from an Excel field versus a SQL field, like maybe some sort of zero width character that is not getting read in from the SQL tables when I'm doing the comparison?
Renaming these items did not work. This also affects the Exists transformation matching on id and new_id - but only for joining between Excel and SQL streams, not joining between two SQL streams. And in this case, again, only dealing with the exact same 19 records - in fact I am inserting this as new from the Excel file into the 2 tables in question, then rerunning the pipeline to make sure the duplicate record doesn't update, so it's the exact same data that was used to generate the IDs in the SQL record.
Update: I also recreated the dataflow with a csv for the Excel tab being extracted in the original process. Same cartesian result, looks similar to the second picture - 40 rows, each with nulls and id values that should be on the same row, just like they are when I (full outer) join them from the two sql tables
Hi @Jeff vG ,
Thank you for detailed response. Its very strange. I am suspecting is there any spaces getting appended when you are trying excel and SQL.
Could you please try to trim id and new_id and see if that helps.
sample expression: trim(toString(id)) == trim(toString(new_id)))
Ah :D
SHA-256 outputs 256 bits, which is 32 bytes / characters, or 64 bytes in hexadecimal characters. SHA256 != 256 characters.
So my SQL table's char256 field has 192-long white space at the end of each 64-character id, which obviously won't match with the hash of the original data.
I'm still confused as to why my left(new_id,10) == left(id,10) didn't solve this, but it doesn't matter since this is the issue anyway.
Can you add the trim... answer, or do I accept the original answer even though the last response is what helped?
Hi @Jeff vG ,
Added trim... as answer. Could you please Accept Answer. Accepting answer will help community as well. Thank you.