Azure Machine Learning
An Azure machine learning service for building and deploying models.
3,335 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.

Hi Azure ML users! My Regression model, based on this learning Path:
Create a Regression Model with Azure Machine Learning designer --> Deploy a predictive service.
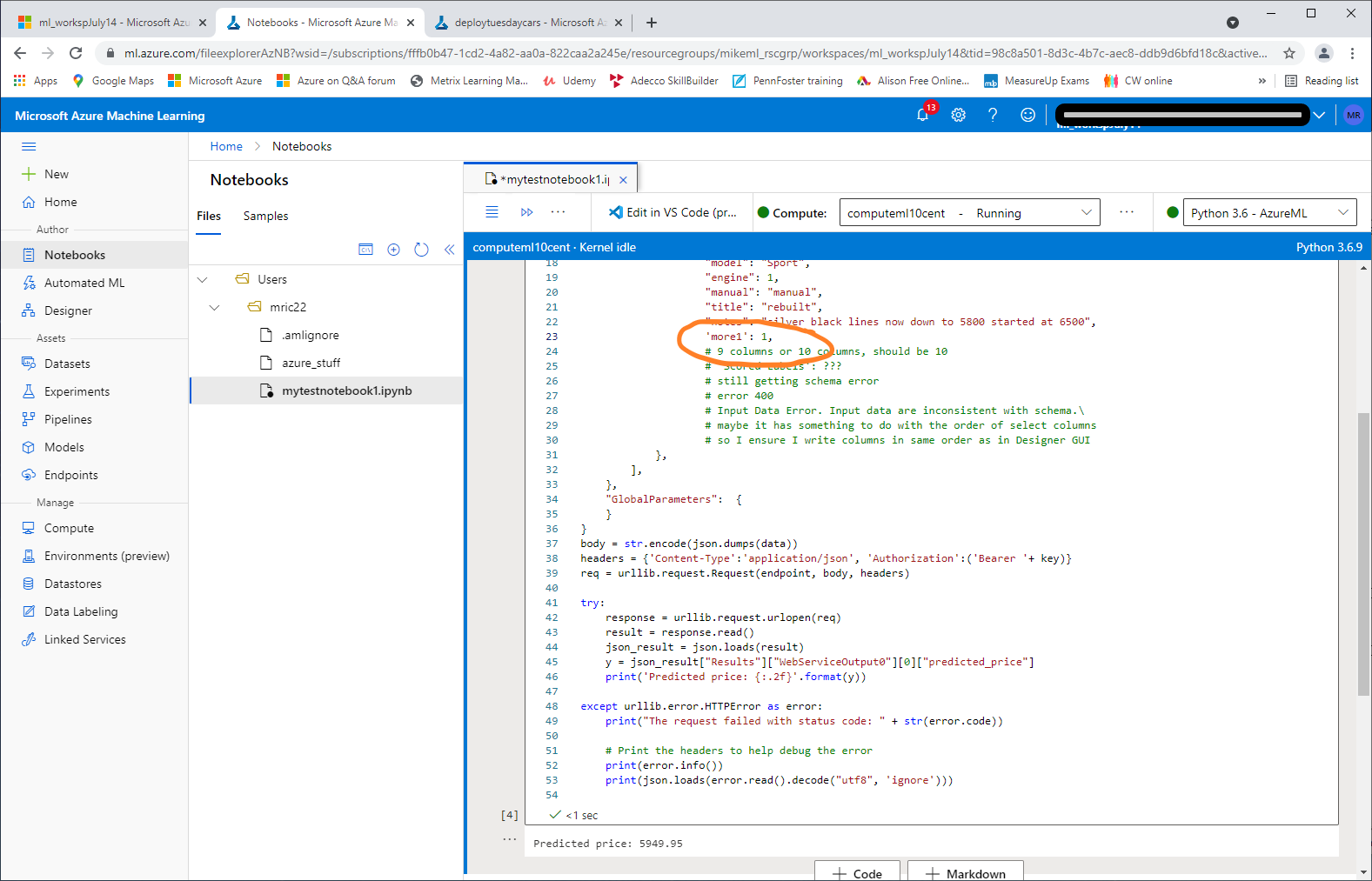
It predicts a car's price. I've added Edit Meta Data in Designer to clear features of other columns selected. This displays other details about each car, like engine, manual or automatic, title status and general notes. For prediction AzureML only uses two columns, miles and year, to predict price. 6 columns ClearFeatured, 2 features and one label column for price, 9 total columns selected.
"price": 5500,
"year": 2013,
"car": "Mini Cooper",
"miles": 74000,
"model": "Sport",
"engine": 1,
"manual": "manual",
"title": "rebuilt",
"notes": "silver black lines to 5500 started at 6500",
-- Here is the deploy error --
The request failed with status code: 400
Access-Control-Allow-Origin: *
Content-Length: 1271
Content-Type: application/json
Date: Thu, 15 Jul 2021 03:17:53 GMT
Server: nginx/1.14.0 (Ubuntu)
X-Ms-Request-Id: 6d440216-81bc-441f-aeae-c5190c486028
X-Ms-Run-Function-Failed: False
Connection: close
{'error': {'code': 400, 'message': 'Input Data Error. Input data are inconsistent with schema.\nSchema: {\'columnAttributes\': [{\'name\': \'price\', \'type\': \'Numeric\', \'isFeature\': True, \'elementType\': {\'typeName\': \'int64\', \'isNullable\': False}}, {\'name\': \'year\', \'type\': \'Numeric\', \'isFeature\': True, \'elementType\': {\'typeName\': \'int64\', \'isNullable\': False}}, {\'n\nData: defaultdict(<class \'list\'>, {\'price\': [5500], \'year\': [2013], \'car\': [\'Mini Cooper\'], \'miles\': [74000], \'model\': [\'Sport\'], \'engine\': 1, \'manual\': [\'manual\'], \'title\': [\'rebuilt\'], \'notes\': [\'silver black lines now down to 5800 started at 6500\']})\nTraceback (most recent call last):\n File "/azureml-envs/azureml_d04391a4e9e93a56aa2beac2c36d4d02/lib/python3.6/site-packages/azureml/designer/serving/dagengine/dag.py", line 167, in execute\n input_data = create_dfd_from_dict(raw_input, schema)\n File "/azureml-envs/azureml_d04391a4e9e93a56aa2beac2c36d4d02/lib/python3.6/site-packages/azureml/designer/serving/dagengine/converter.py", line 19, in create_dfd_from_dict\n raise ValueError(f\'Input json_data must have the same column names as the meta data. \'\nValueError: Input json_data must have the same column names as the meta data. Different columns are: {\'more1\'}\n', 'details': ''}}
:: problem ::
Why is the notebook failing? but the Test of the endpoint has succcess? What am I doing wrong with the schema?
Thank you.
-- more details below, if you interested --
my incoming data will match the schema of the original training data, 9 columns, so I did not do this step below.
Learning Path says:
"The inference pipeline assumes that new data will match the schema of the original training data, so the Automobile price data (Raw) dataset from the training pipeline is included. However, this input data includes the price label that the model predicts, which is unintuitive to include in new car data for which a price prediction has not yet been made."
Learning Path also says:
"Now that you've changed the schema of the incoming data to exclude the price field, you need to remove any explicit uses of this field in the remaining modules. Select the Select Columns in Dataset module and then in the settings pane, edit the columns to remove the price field."
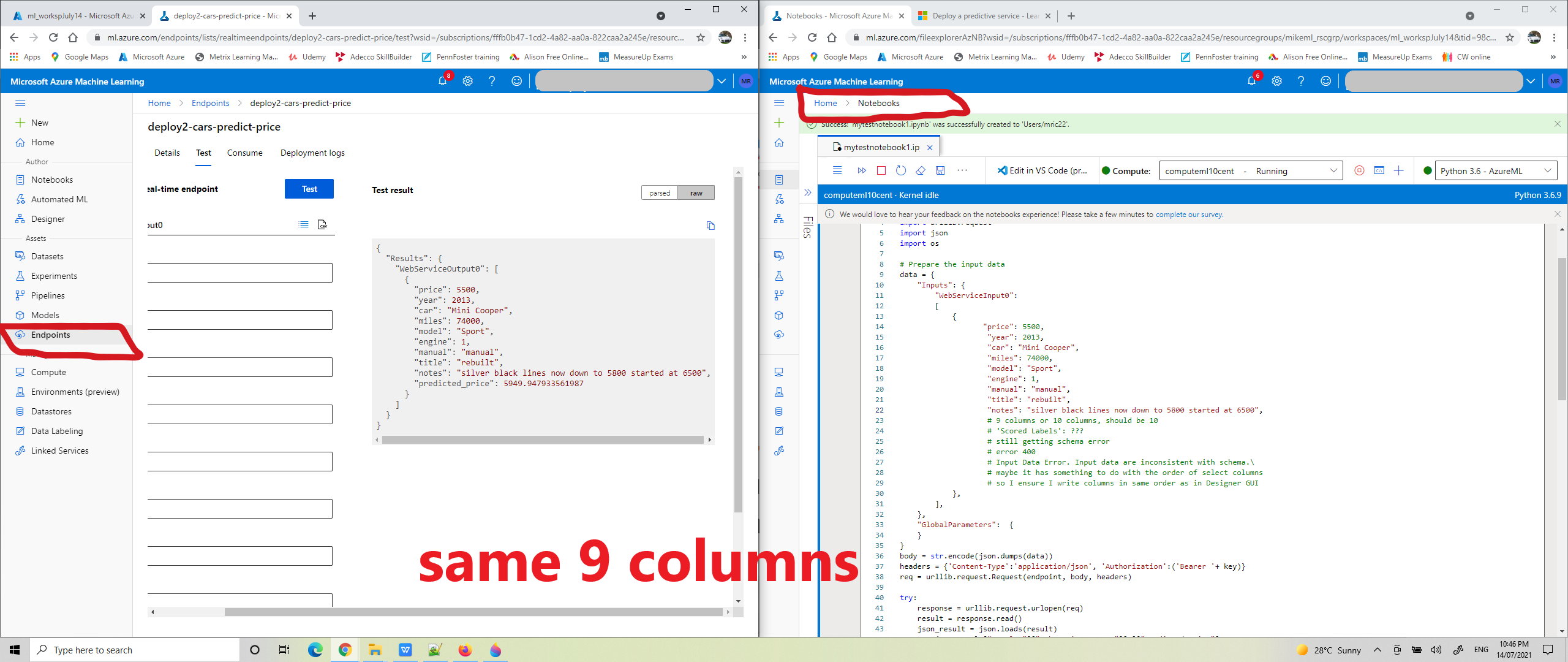
it's working now. I needed to add the more1 column. this was a null column in my dataset, the last column in CSV file.
in my training pipeline this was omitted from Select Columns in Dataset. But in the Creating Inference,mistakenly put it back in, all my columns in the Enter Data Manually asset. 10 columns in Notebook now matches 10 column names for inference pipeline.