Azure Data Lake Storage
An Azure service that provides an enterprise-wide hyper-scale repository for big data analytic workloads and is integrated with Azure Blob Storage.
1,490 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EN%3C/text%3E%3C/svg%3E)
Hello there,
How do I continually update the data in my Azure Data Lake to upsert new data via Azure Data Factory based on the partitions (client ID and date) of the container in the Data Lake? Data we collect over the span of a rolling week could change throughout that week, therefore it's critical that for each day from day 1 thru day 7 post the day of initial processing can subsequently process updated data into the Data Lake. It seems as though the only option is the "Clear the Folder" in the "Sink" job in an Azure Data Lake Data Flow, but I only need to clear the folders for the partitions that the Data Flow needs to run for. Without selecting "Clear the Folder" my data gets duplicated within the Data Lake.
To give an example, if today (2021-07-15) I collect data for yesterday (2021-07-14), I can write that to the Data Lake no problem via ADF Data Flow. But if in 2 days (2021-07-17), the data from yesterday (2021-07-14) gets updated for a given client, then I want to rewrite the data for yesterday (2021-07-14) to reflect the new data collected.
This is essentially the "upsert" function if I were writing this data to an Azure SQL DB OR using INSERT OVERWRITE if I were manually uploading this data in Hive/Spark SQL.
Does anyone know if this is possible via Azure Data Factory? Let me know if you need me to provide more context or an additional example.
Best wishes,
Netty
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EKM%3C/text%3E%3C/svg%3E)
Hi @Netty ,
Welcome to Microsoft Q&A forum and thanks for reaching out.
To better assist on your query, could you please confirm how are you partitioning your output folders? Are you partitioning the output folders based on date?
Also, when you say you upsert you mean rewriting few rows inside the files or overwriting entire file?
Please Note, Files on data lake will not act as Tables in DB. In case, of Tables you can update only few records inside the table. But in case of Files that is not possible. Always, entire file will override.
Hi @KranthiPakala-MSFT ,
Thanks so much for the response. Totally hear you on the files overwriting. I am totally OK with overwriting and wiping out old files to replace them with new ones, as long as it pertains to the partitions that are specified for that given run (in my case, the end files are all .json files that should be equally split up based on the size of the data under the partition).
Let's run through the following examples based on how I plan to partition my datasets:
Partion Level 1:
client_id=123456
client_id=234567
Partition Level 2:
date=2021-07-10
date=2021-07-11
date=2021-07-12
date=2021-07-13
date=2021-07-14
date=2021-07-15
date=2021-07-16
date=2021-07-17
date=2021-07-18
(eg: my-data-lake/my-container/client_id=123456/date=2021-07-18/*.json)
Example 1) If I run a job for both client IDs for the last 7 days, then I am perfectly OK with wiping all data and files between 7/12 and 7/18, updating it with the data from the job that runs today, as long as data from 7/10 and 7/11 are not removed or altered.
Example 2) If I run a job just for client 123456, then I would want files to be removed and replaced with updated data only for client 123456, without affecting client 234567.
Let me know if this additional info helps or if you need anything else from my end to help explain further.
Best wishes,
Netty

Hi @Netty ,
Thank you for your response. Please check below posted answer. Please Accept Answer. Accepting answer will help community as well.
Hi @Netty ,
Thank you for posting query on Microsoft Q&A Platform.
I have implemented a sample pipeline for your requirement. Please check below detailed explanation and follow same in your requirement too.
Step1: Created a pipeline parameters called "client_id" & "dates"
client_id --> To hold your client id for which you want to run execution.
dates --> Array of your dates values for which you want to run execution.
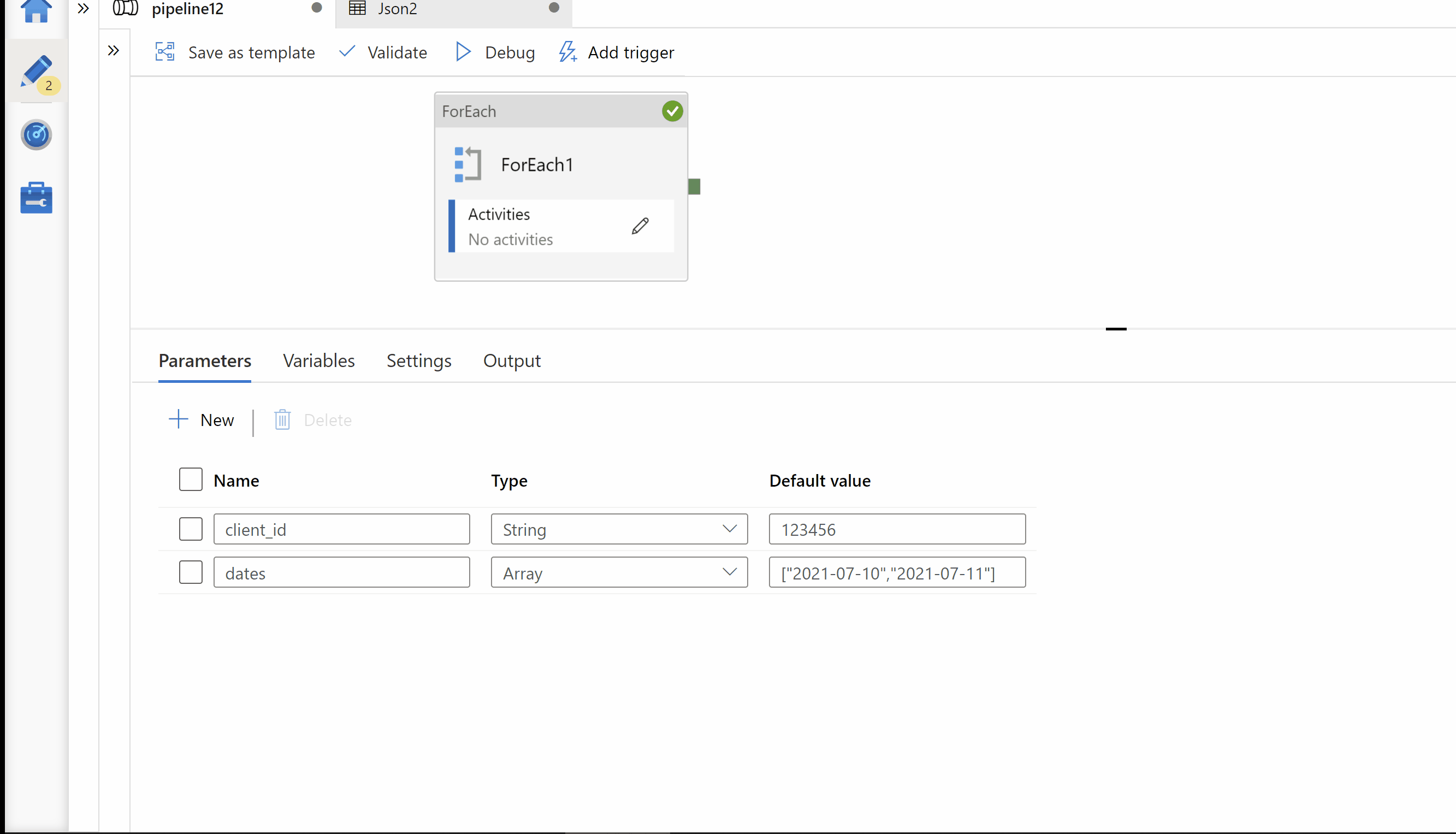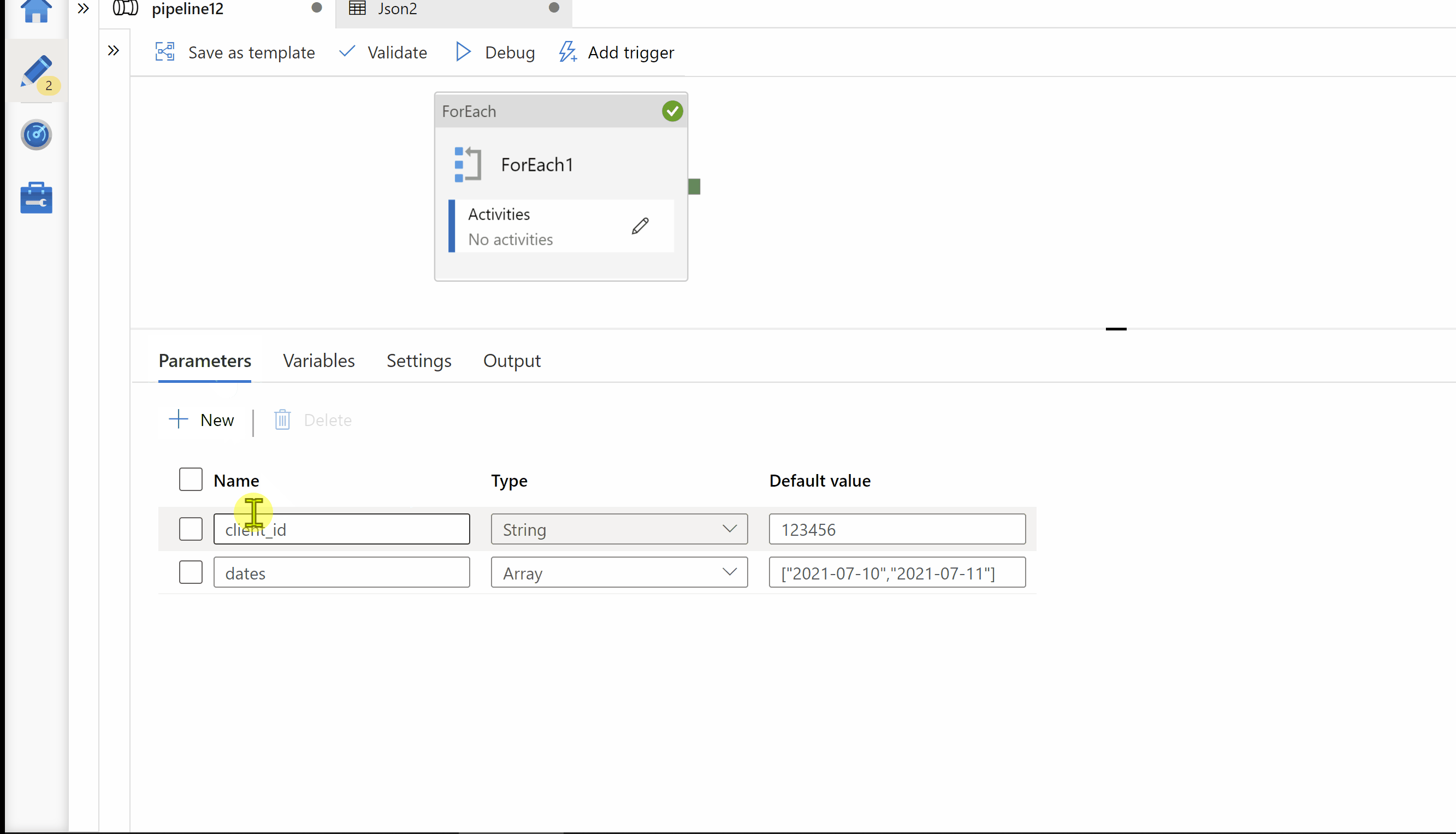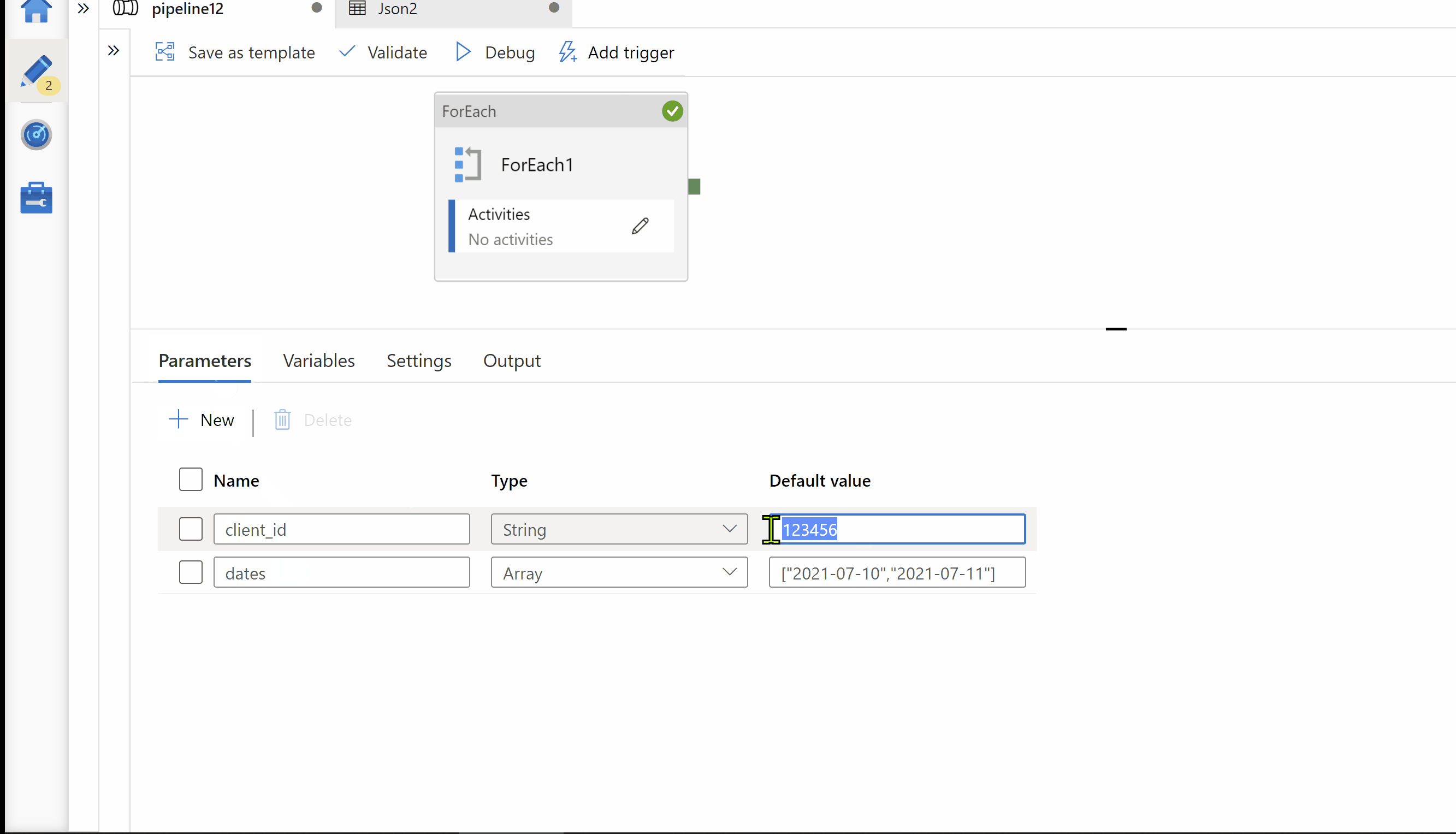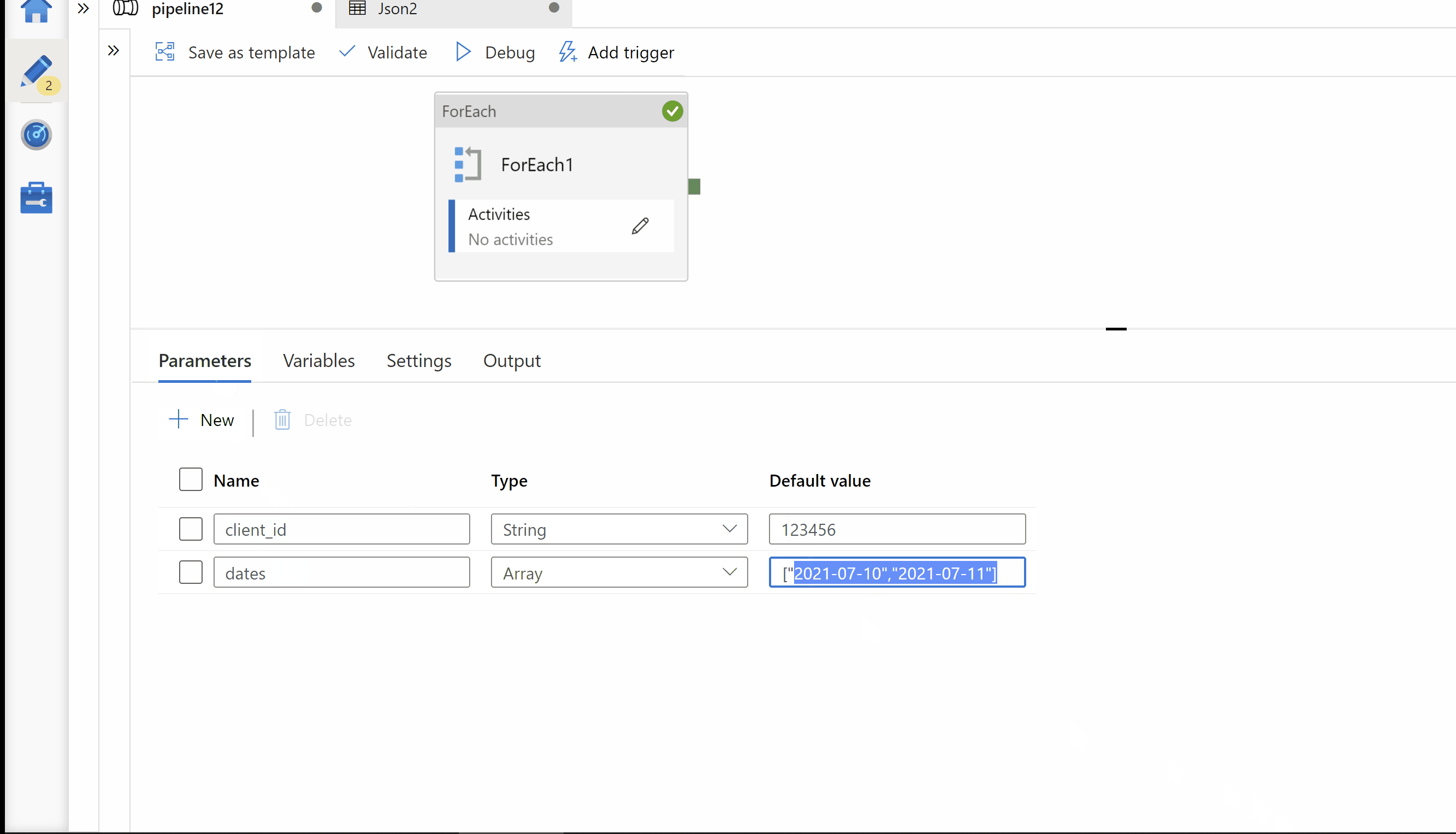
Step2: ForEach activity. Pass your dates array in to Foreach activity.
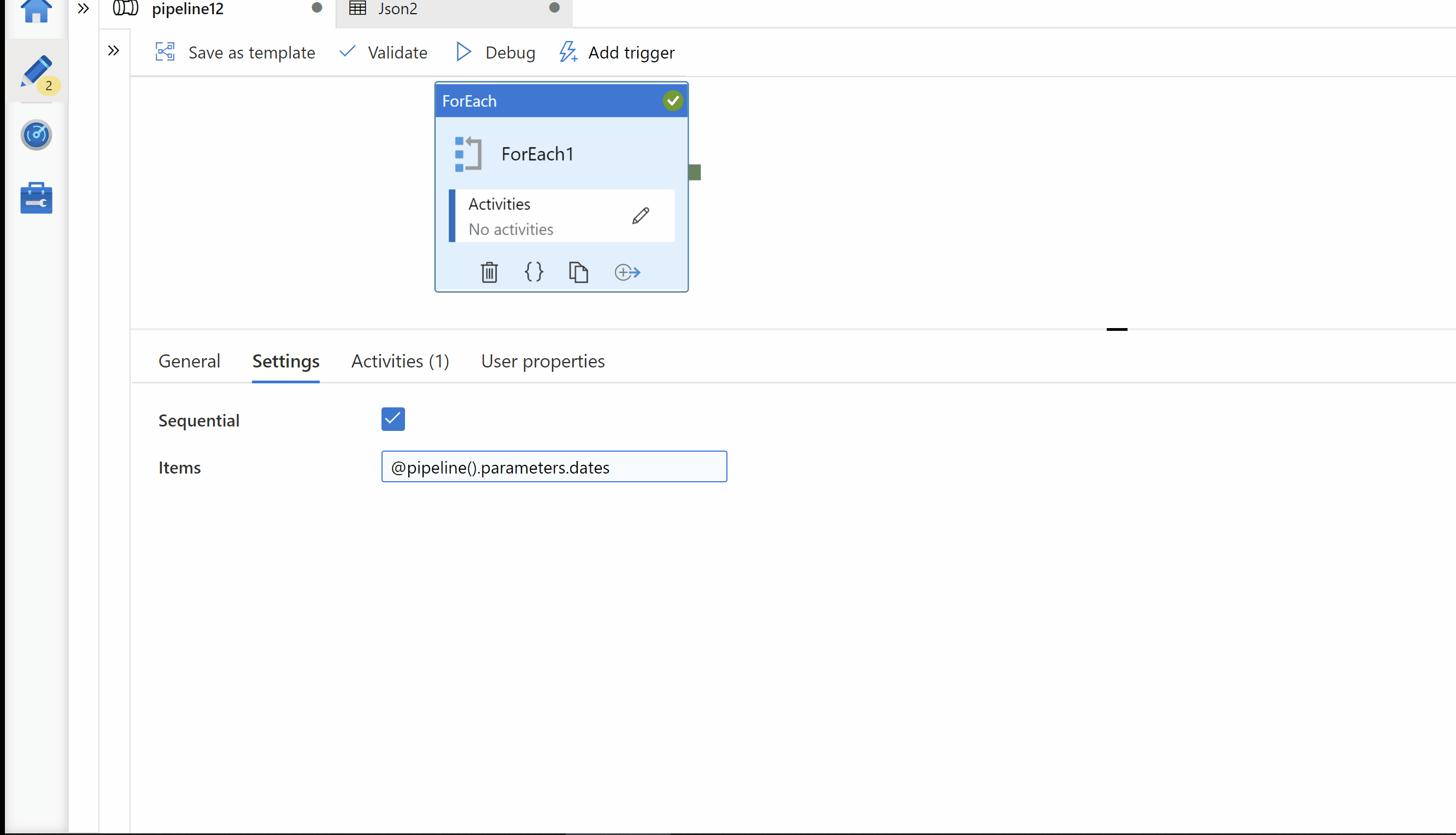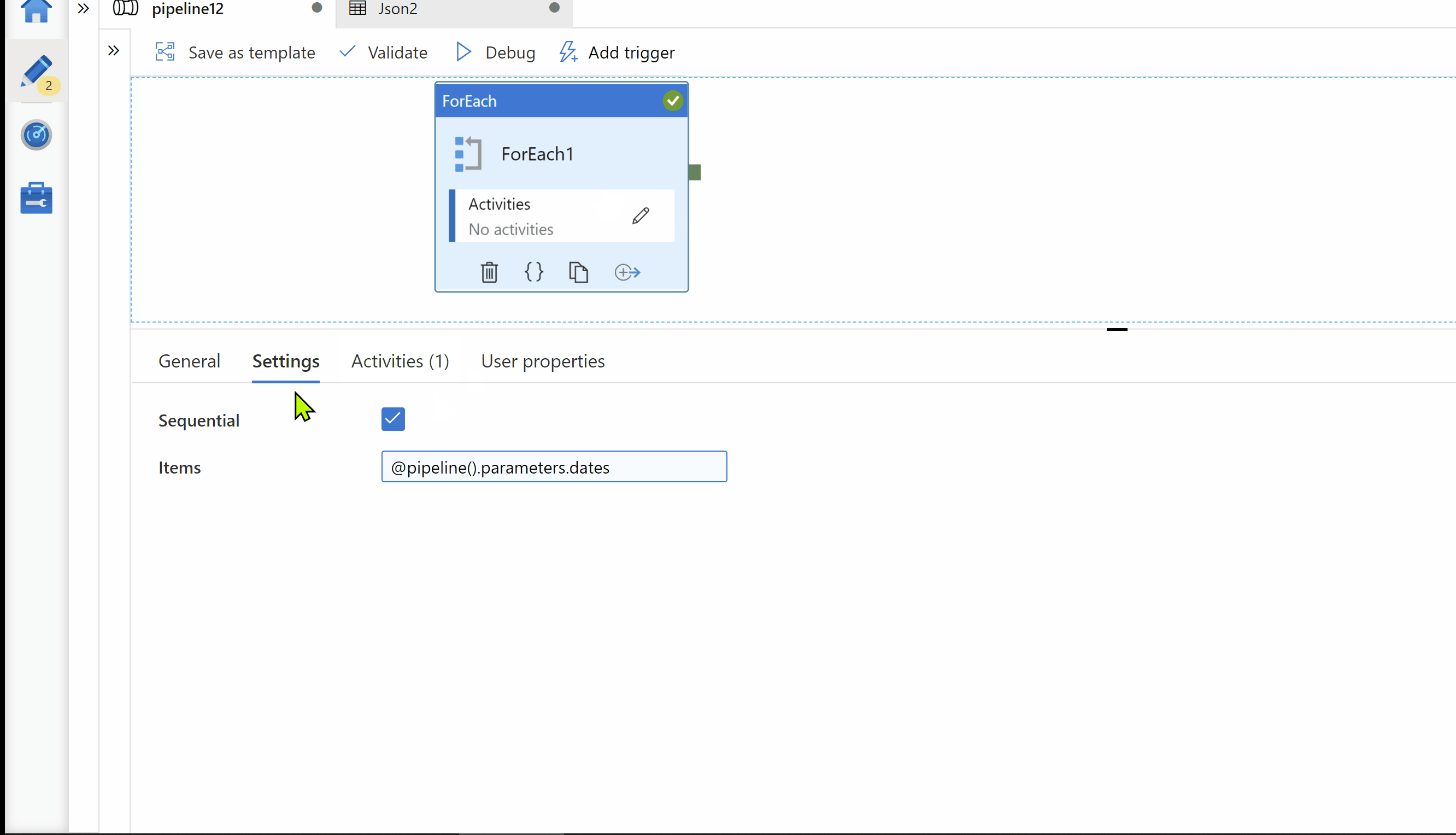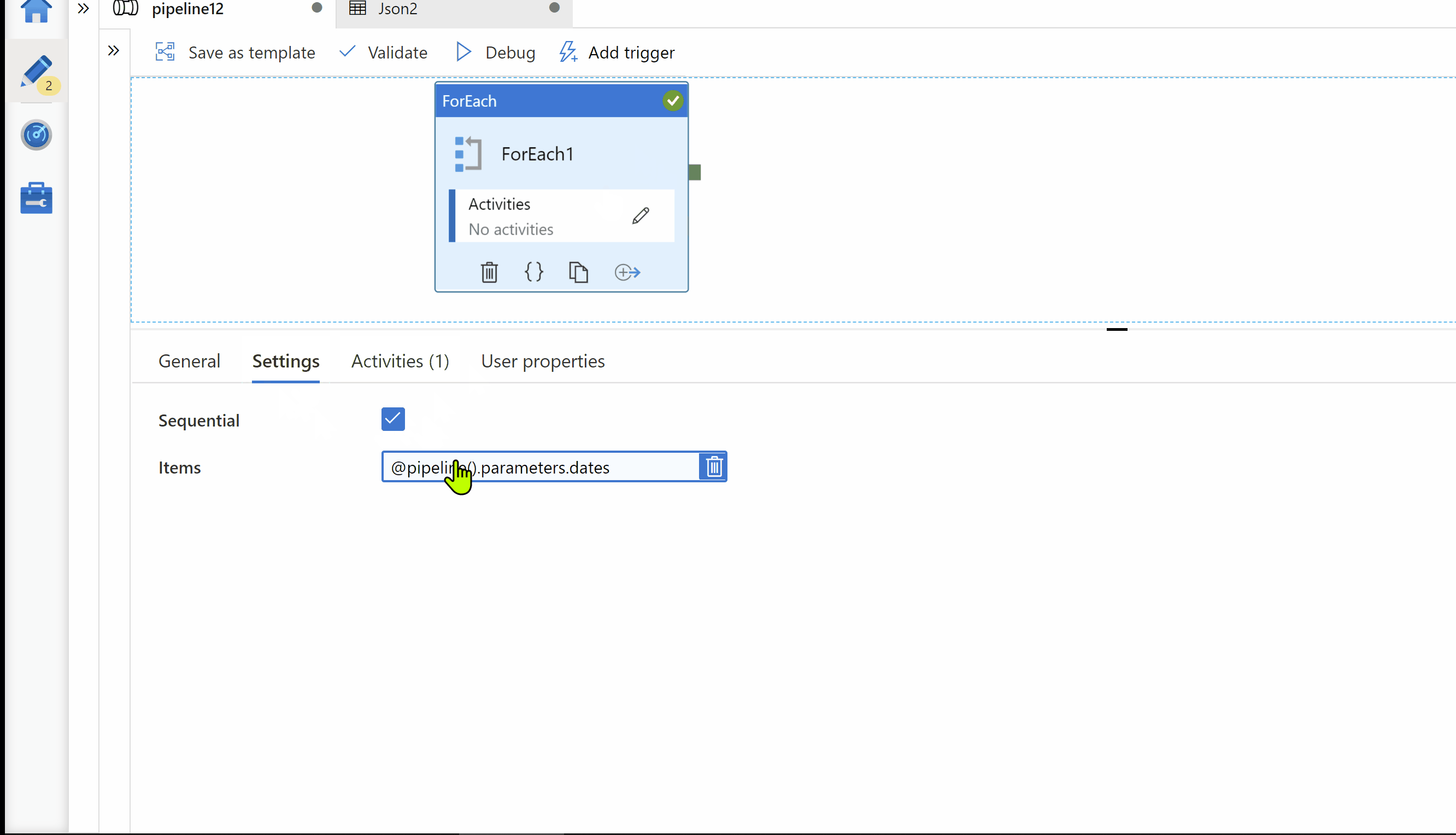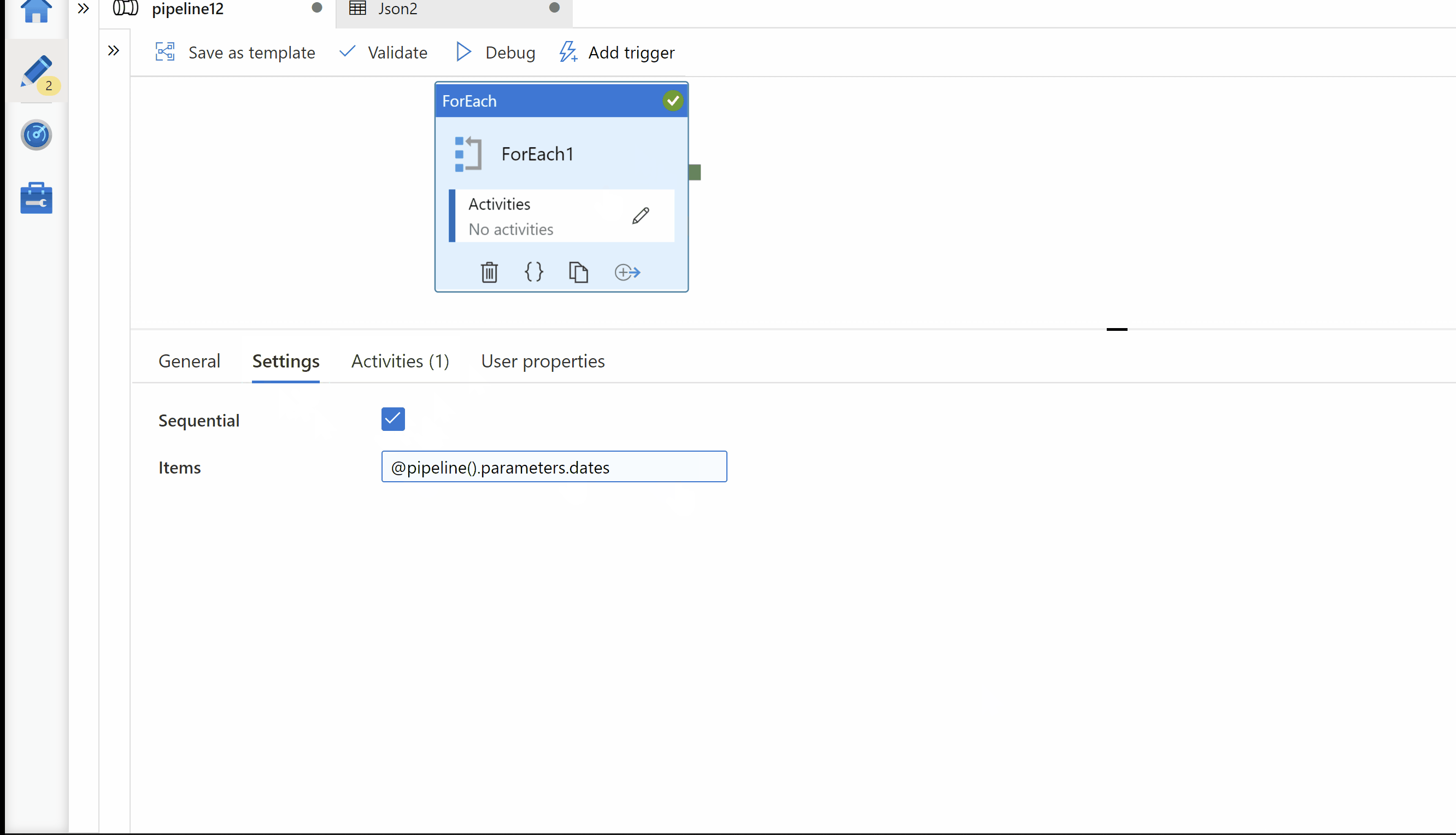
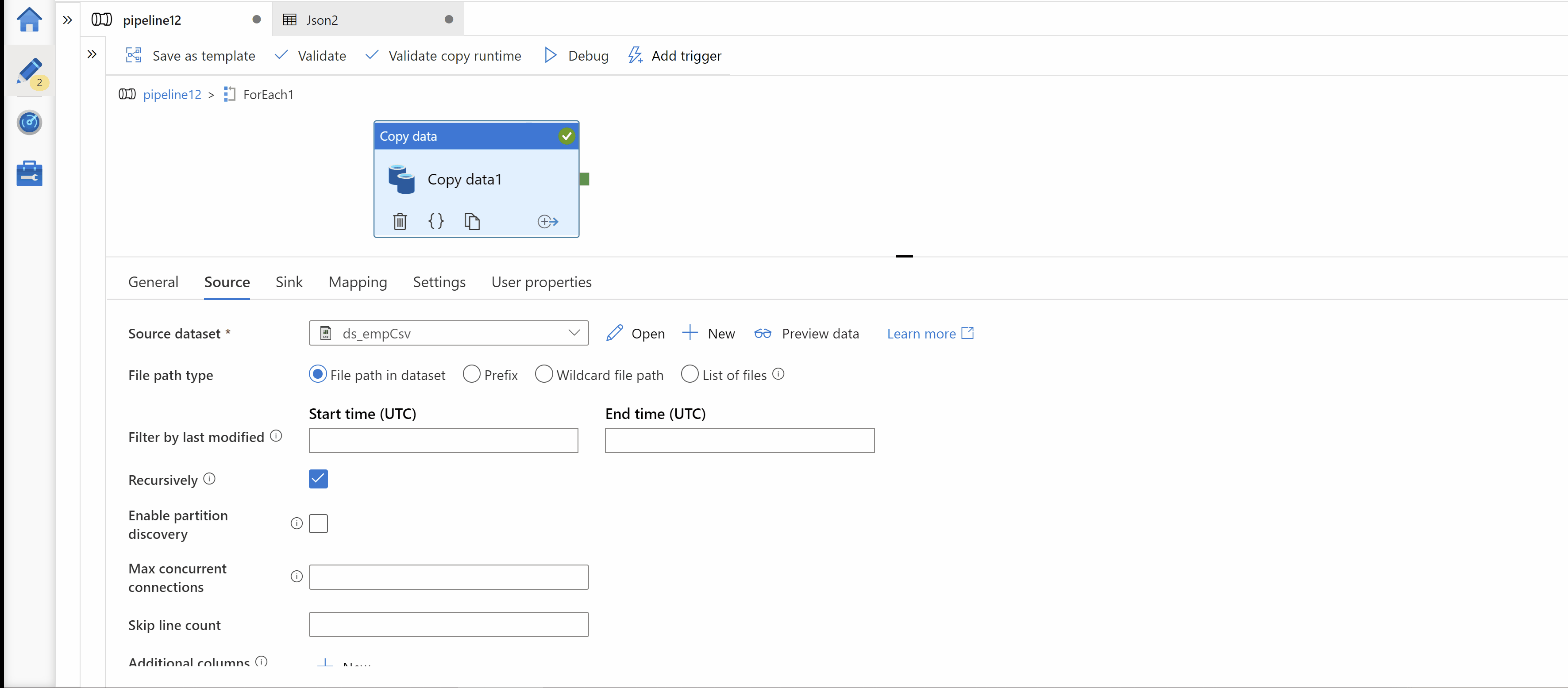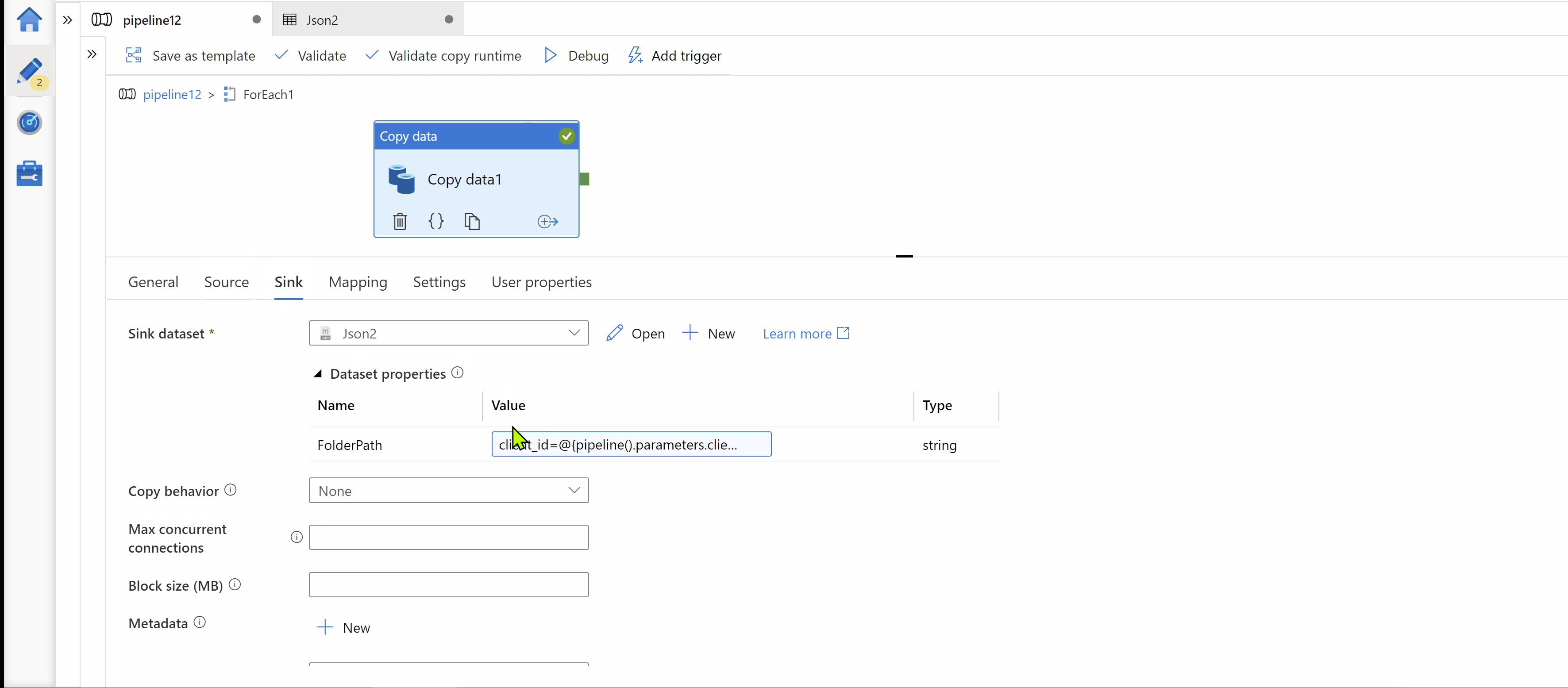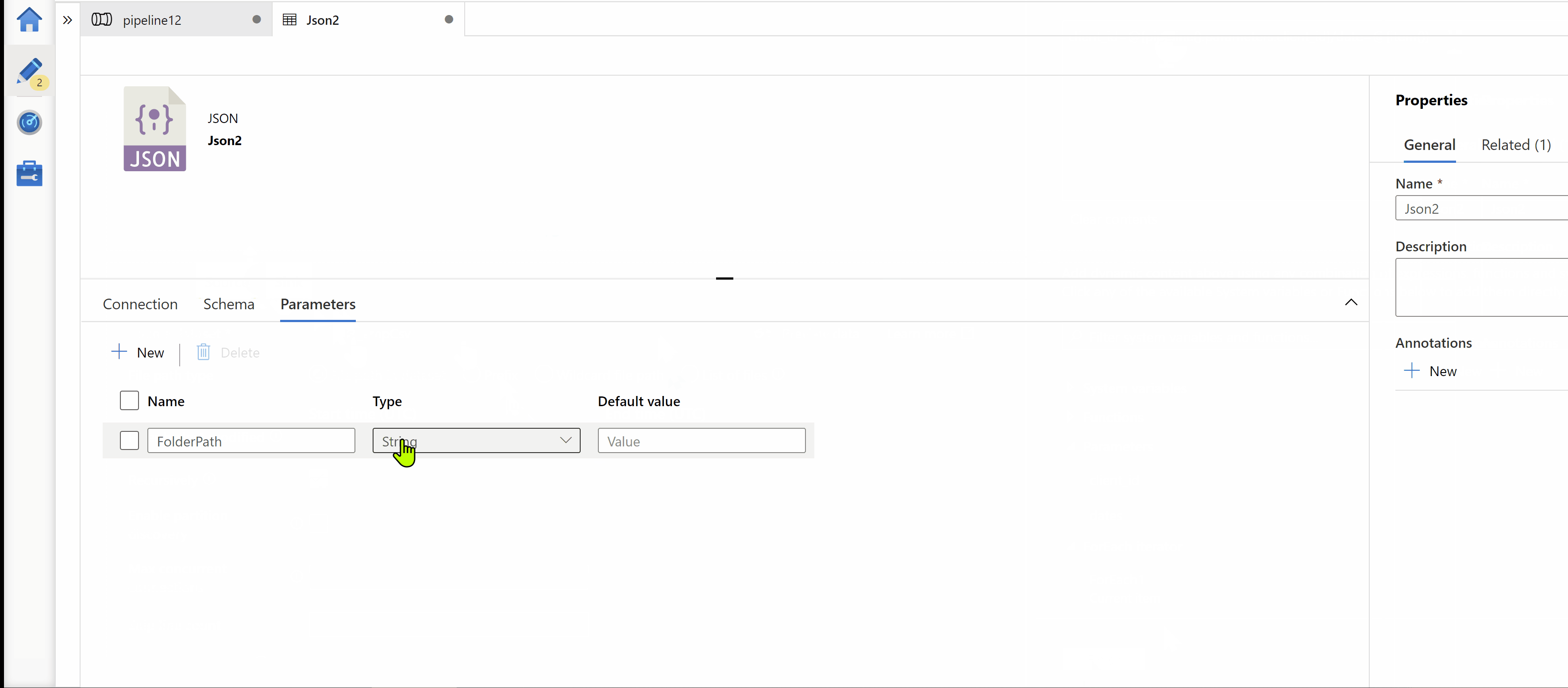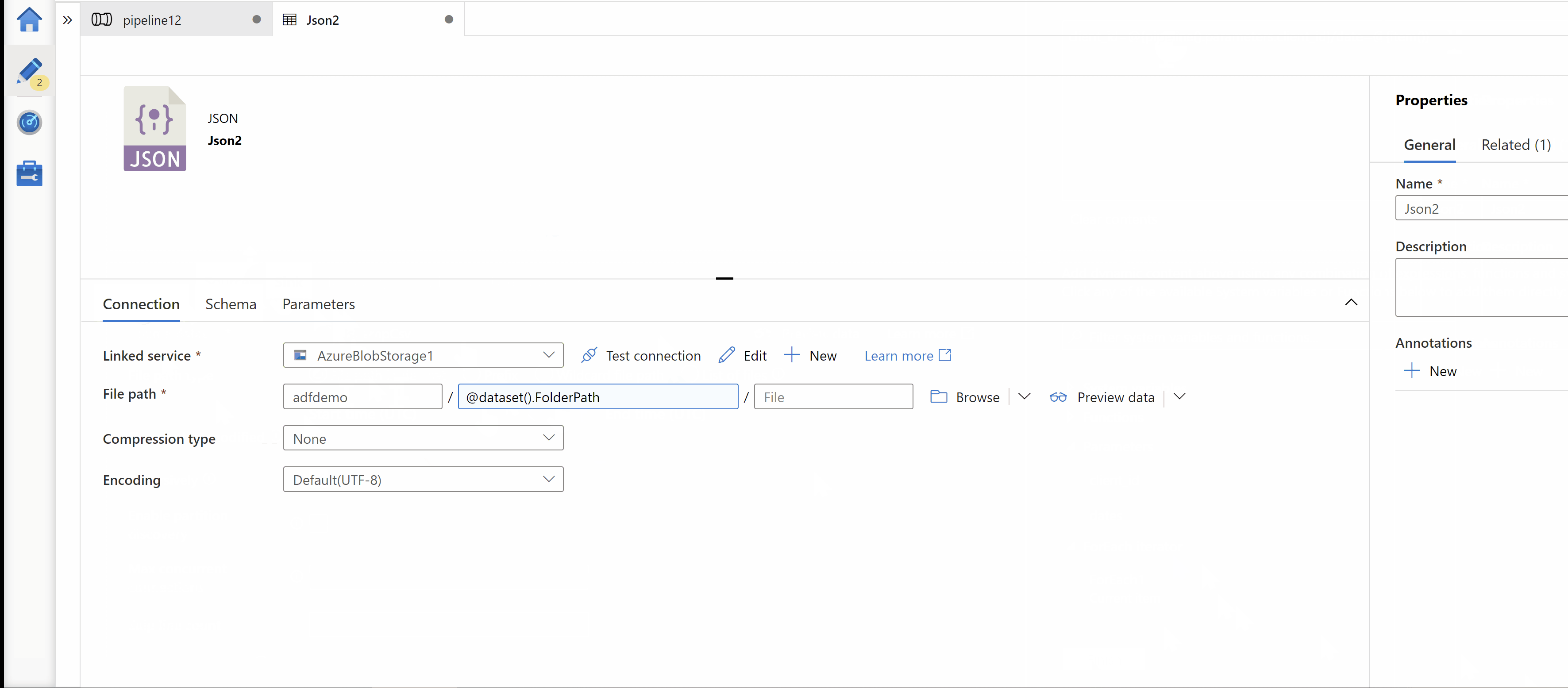
Step3: Inside ForEach activity, Use Copy activity for copy source data in your target storage. Here, on Target we want to get folder path in below format. Hence I use parameterized dataset as Sink.
my-data-lake/my-container/client_id=<clinet_id>/date=yyyy-MM-dd/*.json
Expression used for dynamic path: client_id=@{pipeline().parameters.client_id}/date=@{item()}
Hope this will help. Thank you
----------------------------------
accept an answer if correct. Original posters help the community find answers faster by identifying the correct answer. Here is how.
Thank you so much for the answer. This is very close to what I need, but I don't think it quite gets there. Copying data based on a date range should be fine since I can handle dynamic date ranges within the Data Flows that are in the Pipeline. I think the more worthwhile endeavor would be to use a "ForEach" to iteratively "Delete" the last 7 days based on the current date.
In an example that I'm envisioning, when today's job runs, a "ForEach" function would be used to iteratively delete data for the last 7 days for a specific client. Using client 123456, we would iteratively delete all data from directory "my-data-lake/my-container/client_id=123456/date=2021-07-13" up through "my-data-lake/my-container/client_id=123456/date=2021-07-19". From there, my "Data Flow" can repopulate the data in those partitions based on the lookback window that's in the "Data Flow". When the job runs again tomorrow, it repeats the process, except using "2021-07-14" as its starting point and "2021-07-20" as the end date. We cannot specify a static dates like you have in your example since these jobs will be scheduled to run and need to always call back for the last 7 days.
Let me know if this makes sense or if you would like me to provide any additional examples/context.
Best wishes,
Netty
Hi @Netty ,
Thank you for follow up query.
As We mentioned earlier in comments, Files in Data lake will always gets override when any new file comes and lands there.
So technically, you no need to Iterate folders and delete files and then repopulate files in that folders. Because when we try to load a file in to our data lake folder with same name automatically existing file will be deleted and newly loaded file will get create there.
Hope this helps. Please let us know if any further queries.
---------------------------------
accept an answer if correct. Original posters help the community find answers faster by identifying the correct answer. Here is how.
Unfortunately I don't think that will work. My underlying data is quite large (potentially well over 1 millions rows per partition) so I have the underlying JSON files named like this:
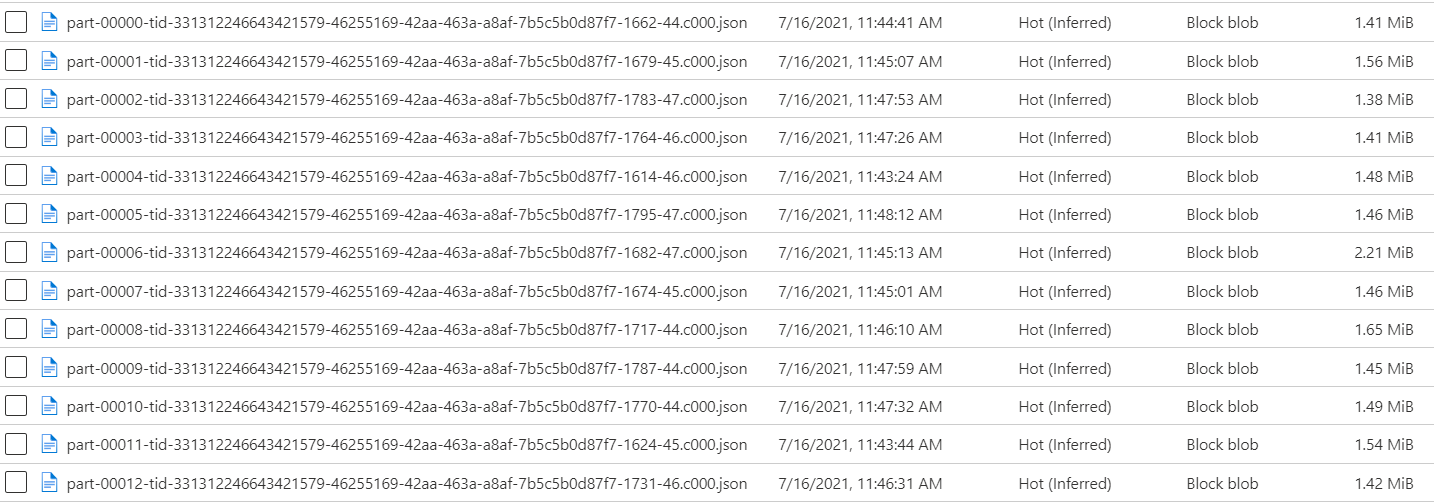
I have rerun jobs covering overlapping date ranges and I'm confirming that I see duplicate entities. My guess is that since I've gone with the default naming convention per file in Data Factory that there's a unique file name per file, which would prevent it from overwriting older data. I can move over to a naming convention based on "Per partition", but I worry that'll affect performance while querying the data.
Let me know your thoughts and if I should proceed with a "Per partition" naming convention or if I should do a workaround to iteratively delete the older data in the partitions.
Best wishes,
Netty
Hi @Netty ,
Thank you for detailed response and follow up query. Please Accept Answer. Accepting answer helps community too.
Yes, as you said since you are going with default naming convention per file, Data factory creating unique file name. Hence, your old files are not getting overwritten.
Two ways, you can make sure that your old files gets deleted.
Option 1: Go with user defined naming convention which will automatically override files.
Option 2: Use Delete activity to delete files first and then continue process of copying.
Option 2, needs another logic implementation over the existing implemented setup. I feel Option1 will be good if that suits your requirement. Kindly review above two options and choose accordingly.
Hope this will help. Thank you. Please feel free to post if any further queries.
OK great, thanks for the heads up @ShaikMaheer-MSFT . It sounds like Option 1 should give me what I need so let me test that out. I'll let you know how everything goes. I appreciate your support here.
Best wishes,
Netty
You are welcome @Netty