Azure Databricks
An Apache Spark-based analytics platform optimized for Azure.
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3ECU%3C/text%3E%3C/svg%3E)
Hello Experts,
I am trying to read an Excel file (247MB and total rows 549628) through databricks and converting into Paraquet file and keeping it in ADLS Gen 1(already mounted) but getting below error even while reading the file:
"The spark driver has stopped unexpectedly and is restarting. Your notebook will be automatically reattached."
below is the code:
import org.apache.spark._
val Data = spark.read.format("com.crealytics.spark.excel")
.option("header", "true")
.option("inferSchema", "true")
.load("/mnt/adls/folder/file.xlsx")
Below is the configuration of cluster:
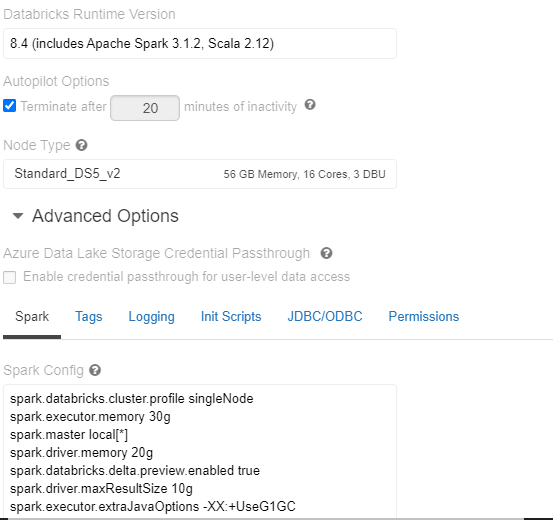
I have also tried by choosing high configuration
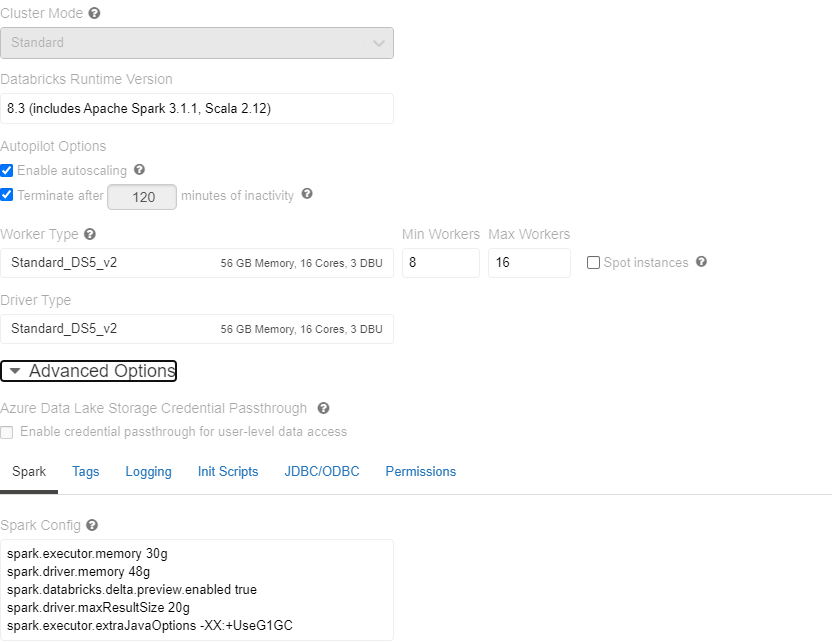
But still getting this issue and also if i check the even log i always see below details:

if i break the same file into small records like 100k in each file then able to process the file.
Please let me know if i am not choosing the optimized configuration but it seems weird since databricks should increase the processing and should be able to process 247mb file even with basic config.
Appreciate your time and effort, Thanks !!
Finally able to process the file with just one node config, need to add maxRowsInMemory parameter in the code
val Data = spark.read.format("com.crealytics.spark.excel")
.option("header", "true")
.option("inferSchema", "true").option("maxRowsInMemory",10)
.load("/mnt/adls/folder/file.xlsx")
Reference: https://stackoverflow.com/questions/50789369/construct-a-dataframe-from-excel-using-scala
There are many other optional parameter which might be helpful in other use cases.

Hi @Chayan Upadhyay ,
Welcome to Microsoft Q&A Platform. Thank you for posting query in Microsoft Q&A Platform.
Could you please try below and see if that works.
spark.catalog.clearCache()
Also, Please go through the below links to resolve your issue.
https://kb.databricks.com/jobs/driver-unavailable.html
To know what is GC, please check this answer,
https://forums.databricks.com/questions/14725/how-to-resolve-spark-full-gc-on-cluster-startup.html
Hope this will help. Please let us know if any further queries.
------------------------------
accept an answer if correct. Original posters help the community find answers faster by identifying the correct answer. Here is how.
Thank you @ShaikMaheer-MSFT for you reply and time.
I did try clearchache() statement but didn't help much, gone through the links as well but i don't see any expensive code/activity which will take this kind of hit in performance or processing, probably i am missing some config which will optimize it or it is an actual issue.
I will keep trying something on cluster config and see if i can turn this around, appreciate your help !!
Hi @Chayan Upadhyay - Glad to know that you resolved your issue and also marking that as answer. Thank you.