Azure Data Factory
An Azure service for ingesting, preparing, and transforming data at scale.
11,639 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3ET%3C/text%3E%3C/svg%3E)
I'm using Azure Data Factor data flow to save the incoming data as partitioned *.parquet files (Year/Month). I'm using the pattern setting for names of the files, as shown in the screenshot below. ADF automatically appends "00001" to the file name which I don't need because I use an expression to generate the file name, e.g. "Sales Date=2021-08-07-00001". The Optimize tab is set to Key partition type.
Is there any way to remove the '00001" suffix in the file name?
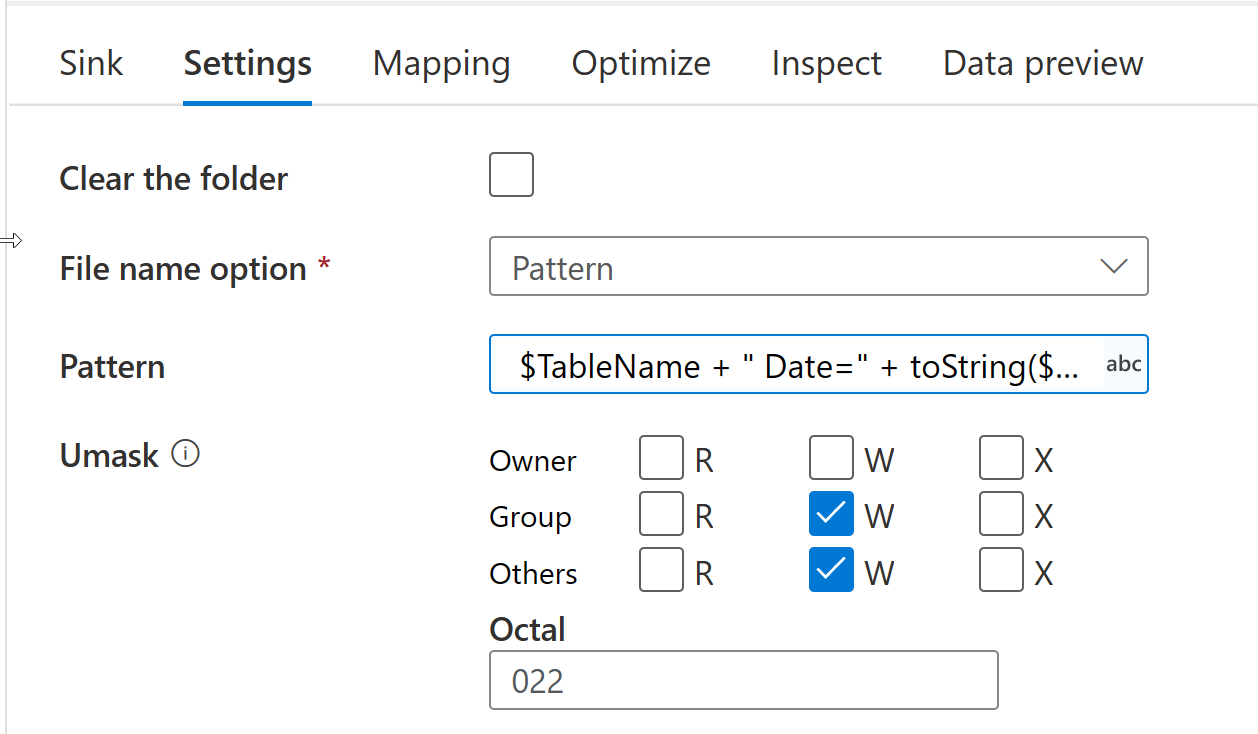

The Pattern option uses the Spark partition naming scheme together with your pattern to devise the target file name. If you're looking to take full control over the final file name, then use the option Output to Single File.
Thanks Mark,
"Output to Single File" complains about performance. In addition, the sink automatic partitioning doesn't work.
To give you a bit more info, we're extracting data from on-prem tables 1:1 to parquet files in ADLS 2.0. Some tables are large and will require an incremental extraction, such as to get the latest data since the last watermark and store it as a separate file. So, incremental tables will have many files, such as:
Sales Date=1900-01-01 (full load)
Sales Date=2021-08-09 16:32:34 (fist incremental load)
Sales Date=2021-08-10 01:30:14(second incremental load)
We want to take advantage of the automatic partitioning by key. "Output to single file" won't work, will it? I guess we just to keep the '00001' suffix.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EMK%3C/text%3E%3C/svg%3E)
In your case, you can just use the Key Partitioning option to set folders based on those values
Which is what we use. It looks like there isn't a way to ignore the Spark partitioning scheme. The suggested Filename[n] pattern implies that I can remove the "n" and thus remove -00001 being added to each file.

Hi @TeoLachev-9086 ,
Thank you for posting your query in Microsoft Q&F Platform. Is your above comment worked for you? If yes, Could you please mark that as Accepted Answer? Accepting answers helps community too.
Please let us know if any further queries. Thank you.
How are these Spark partition files generated? I thought that they all will have '00001' suffix. But after staging a large dataset, I see that now they have different numbers. What will happen if I rerun the load? Will Spark retain the same numbers? Is there a way to control the size of the partition?

You can set the number of partitions with other partitioning types, but not key partitions
Hi @TeoLachev-9086 ,
Following up to check is above answer helps you? If Yes, Please Accept Answer. Accepting answer helps community as well. Thank you.