Azure Functions
An Azure service that provides an event-driven serverless compute platform.
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EWF%3C/text%3E%3C/svg%3E)
I have a function at: https://prime-number-test.azurewebsites.net/api/TestHttpFunction? which performs a CPU intensive operation (Prime number calculation)
In order to get all requests back in the shortest time I want only one function per VM, so I have set maxConcurrentRequests = 1 in host.json (13532-hostjson.txt)
Despite this, when I send 5 requests at once, they are executed sequentially on a single VM. I want a new VM to start up for each request so that all requests are executed in parallel.
I was able to achieve this successfully when using a Queue trigger and batchSize = 1.
Am I doing something wrong? How can I achieve the desired behaviour with the HTTP trigger?
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EJM%3C/text%3E%3C/svg%3E)
@Wade Fleming Following up to understand whether the previous comment helps and works out for the mentioned problem statement.
@WadeFleming-6731 Since we have not heard back from you we will now proceed to close this thread. If there are further questions regarding this matter, please tag me in your reply. We will gladly reopen the issue and continue the discussion.
@Samara Soucy - MSFT thank you very much for your thorough analysis and response, and apologies for the delayed acknowledgement.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3ESS%3C/text%3E%3C/svg%3E)
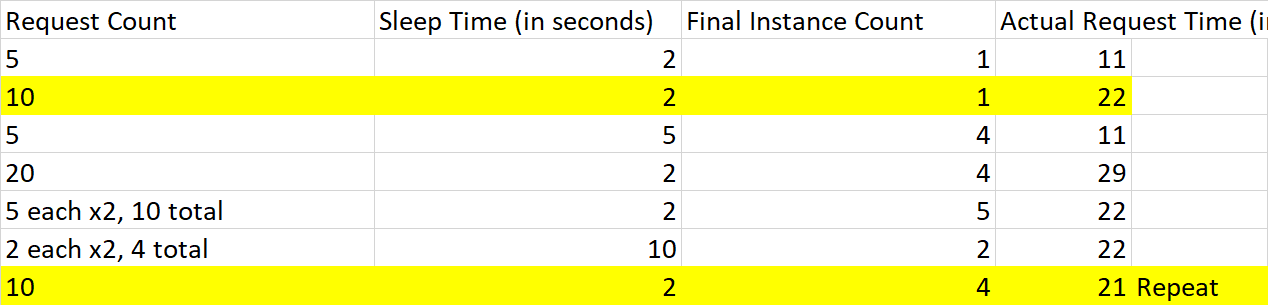
Each type of trigger scales a bit differently and the most likely cause is that your requests just weren't a high enough load for the scale controller to start spinning up instances. The HTTP scaling is far more aggressive than other types, so taking a bit more to get it started helps prevent it from scaling up too many instances from short traffic spikes. The history is also going to play a factor. You'll see in the results I repeated one of the tests and while the response time was around the same, the scale controller kicked in to add additional instances so future requests would be quicker to respond.
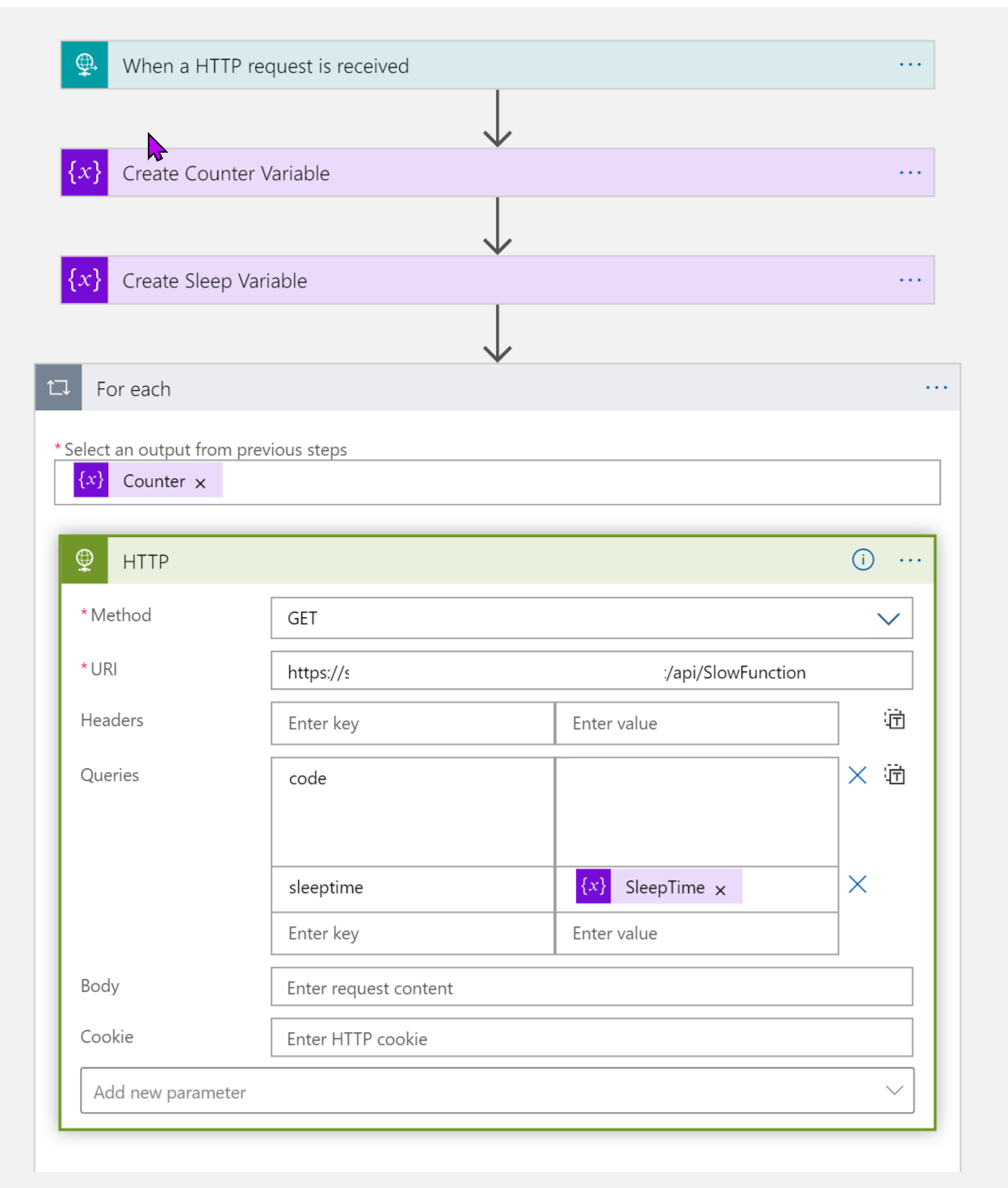
To test this hypothesis, I used your provided host.json file and created a function that let me control externally how long it would take to run the function.
[FunctionName("SlowFunction")]
public static async Task<IActionResult> Run(
[HttpTrigger(AuthorizationLevel.Function, "get", "post", Route = null)] HttpRequest req,
ILogger log)
{
log.LogInformation("C# HTTP trigger function processed a request.");
var time = int.Parse(req.Query["sleeptime"]);
Thread.Sleep(time);
return new OkResult();
}
I then created a logic app that ran a series of HTTP requests in parallel by using a foreach loop. For a couple of these I adjusted the concurrency so it would run in batches. It is by no means meant to be an exact measurement of how the scale controller works, but to give you an idea of what is going on between the scenes.
Since history is a factor, I ran this series twice, deleting and recreating the Functions app in between and got similar results each time.
The process for each:
Here are the results. As you can see, the first couple tests did not create any additional instances, but after that the total jumped quickly. Because of warm up time, the total time it took to run the requests didn't reflect the benefits of the additional VMs, but a steady stream of traffic would have better results over time.