Azure App Service
Azure App Service is a service used to create and deploy scalable, mission-critical web apps.
8,971 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EPN%3C/text%3E%3C/svg%3E)
I have an App Service P1V2 plan with custom autoscale rule configured to scale out to 2 instances when avg CPU >= 40% and to scale in to 1 instance when avg CPU < 40%. The scale out rule works fine when the workload gets higher in the morning around 6:30 AM , but when the avg %CPU drops below 40% it does not scale in at the expected point. Sometimes it waited for a few hours before scaling in.
Yesterday was a bit odd, it waited the whole day before scaling in at around 7:00 PM. I checked the run history and found "Flapping" at each hour for the whole day.
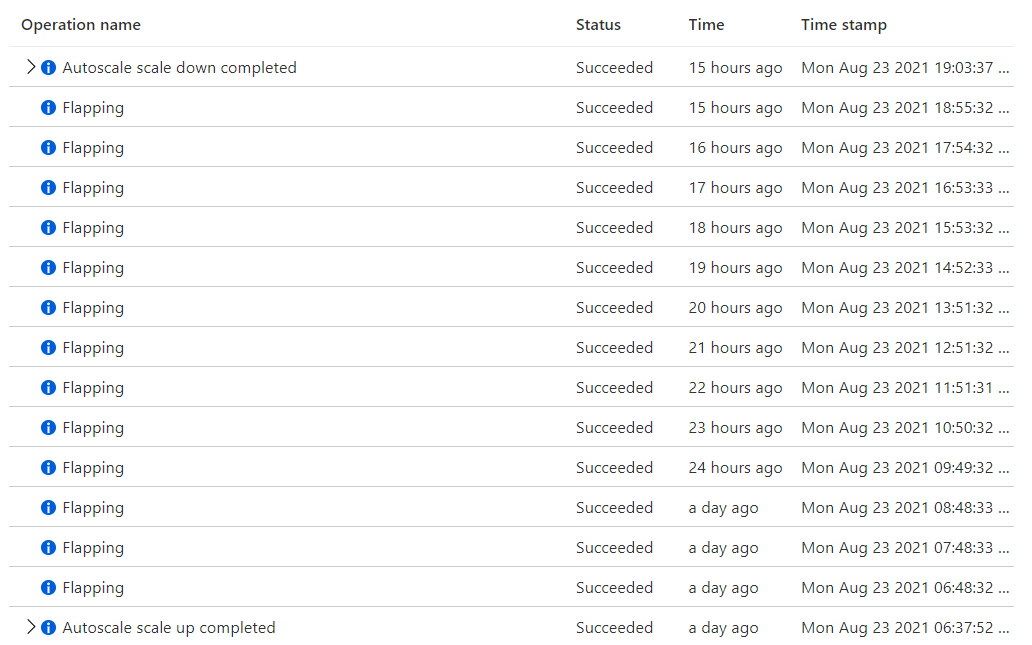
This is the avg CPU usage at the same time period. (5 mins granularity) You can see that avg CPU is at 25% at around 9:00 AM. I expect it to scale in at this point.
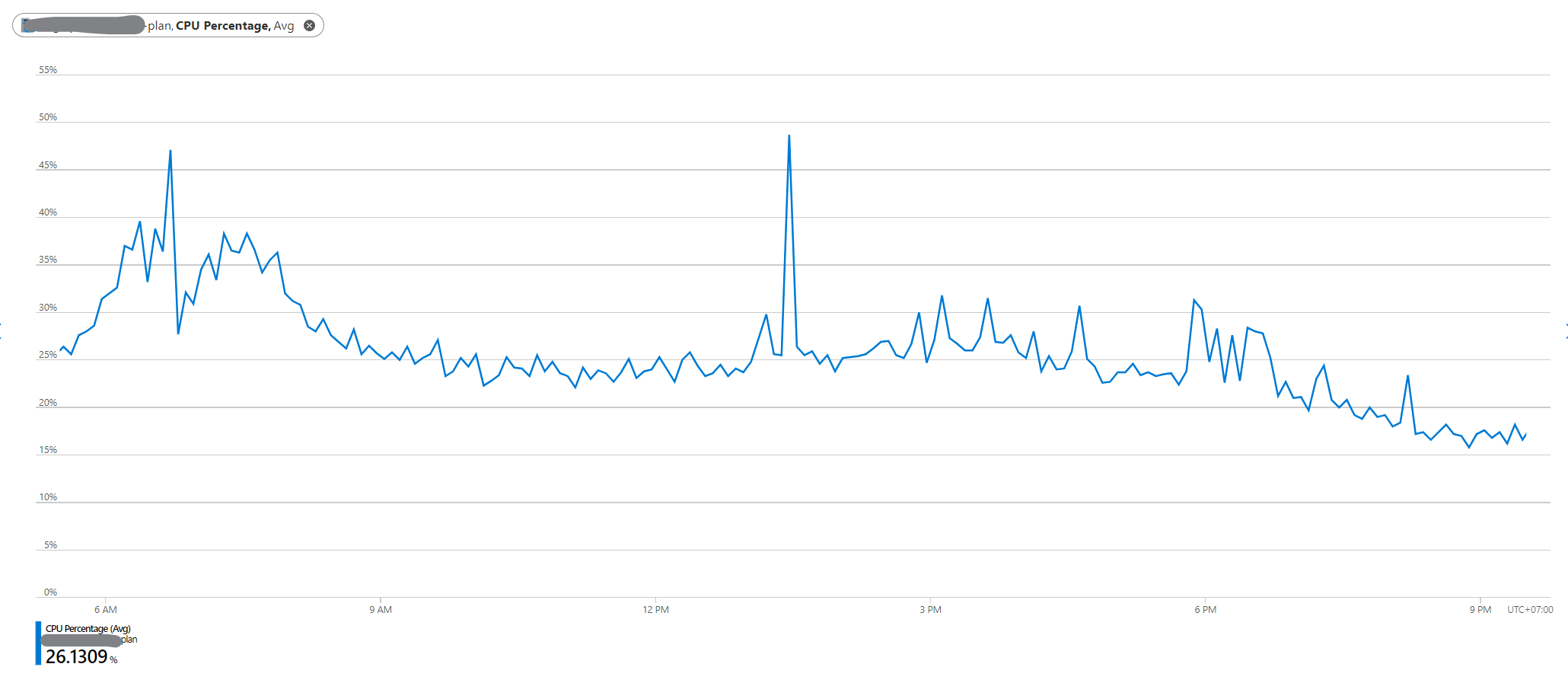
This is the scale in rule I currently have. Is there anything I should adjust? And what is Flapping? Does it have anything to do with the App Service plan not getting scaled in? Thanks.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3ESM%3C/text%3E%3C/svg%3E)
Thanks for asking question! There are best practices for Autoscale and it’s recommended to choose carefully different thresholds for scale-out and scale-in based on practical situations.
Estimation during a scale-in is intended to avoid "flapping" situations, where scale-in and scale-out actions continually go back and forth. Keep this behavior in mind when you choose the same thresholds for scale-out and in.
Its recommended choosing an adequate margin between the scale-out and in thresholds.
As an example, consider the following better rule combination.
• Increase instances by 1 count when CPU% >= 80
• Decrease instances by 1 count when CPU% <= 60
In this case
For example, 60 x 3 (current instance count) = 180 / 2 (final number of instances when scaled down) = 90. So autoscale does not scale-in because it would have to scale-out again immediately. Instead, it skips scaling down.
5.The next time autoscale checks, the CPU continues to fall to 50. It estimates again - 50 x 3 instance = 150 / 2 instances = 75, which is below the scale-out threshold of 80, so it scales in successfully to 2 instances.
Note: If the autoscale engine detects flapping could occur as a result of scaling to the target number of instances, it will also try to scale to a different number of instances between the current count and the target count. If flapping does not occur within this range, autoscale will continue the scale operation with the new target.
Hope this helps. Let us know if further query or issue remains.