Azure SQL Database
An Azure relational database service.
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EPG%3C/text%3E%3C/svg%3E)
We have a local SQL database and I have been trying to use MS db sync on a few tables so we can consume data in our web application and API's from Salesforce via the Azure db - mainly for scalability and bandwidth. DB Sync is not working because some of our tables have clustered primary keys and the values in the clustered columns can change, so sync thinks a new record has been created instead of being changed.
What other options are there? Someone suggested a data warehouse as it doesn't rely on primary keys. What about table storage? All suggestions welcome.
Thanks,
Paul.

DB Sync is not working because some of our tables have clustered primary keys and the values in the clustered columns can change, so sync thinks a new record has been created instead of being changed.
This is a pretty good question and a common one. Therefore, I think a quick Google search can return a lot of good blogs on the subject :-)
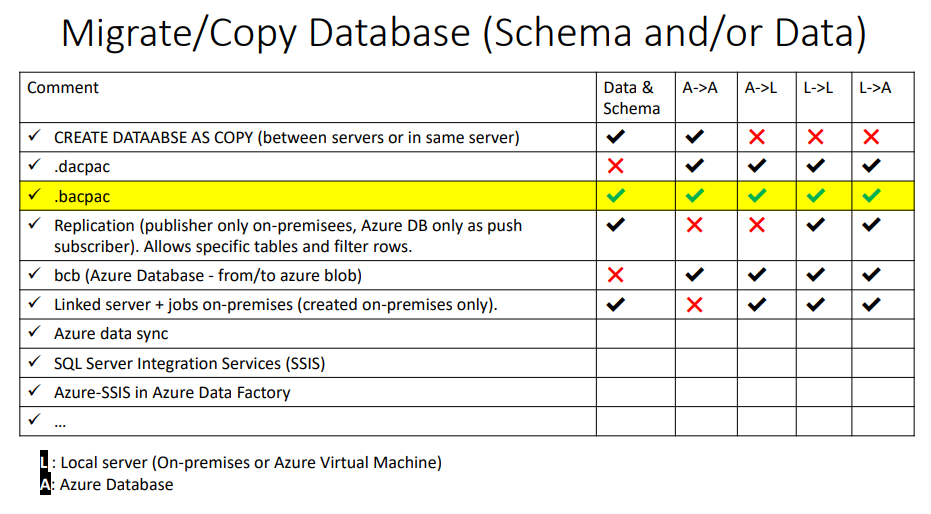
I cannot cover all the options and explain the pros and cos of each one in a forum's thread. For this we need a very long post or event several posts/lectures. With that being said, let me mention some of the options which can be used in order to to Sync from Local SQL Server to Azure Database - not all necessarily fit well in your case but general common sync solutions from local to azure):
Note: Personally, I do not have a bog or a lecture on this topic since I usually prefer to focus on internals and other advance topics but if you search my lecture about The Internals of the External SqlPackage Tool - Inside a bacpac File, then you can find recordings in Hebrew and in English. During that lecture I mention these solutions (in VERY SHORT during the "Wrapping Up") and it might give you some insights.
SQL Server must have some means of uniquely identifying every row. If the clustered index is not unique then the server add uniqueifier hidden column behind the scenes. In your case you use clustered primary keys which means that this column is used to uniquely identify the row.
The big issue in solving your scenario automatically, is that the the clustered primary keys can be changed which make it impossible to recognize which row was changed, since the clustered index is the entity which identify the row. In fact, behind the scenes when you change the clustered index column, then the server do not UPDATE the value! Behind the scenes the server create a new row and mark the old row as deleted (and if needed make sure the new row is in the right location according to the order of the clustered values).
Note: This part is advance undocumented procedure of checking what we actually have on the database file
USE master
GO
DROP DATABASE IF EXISTS test
GO
CREATE DATABASE test
GO
use test
GO
CREATE TABLE dbo.test01 (
ID INT PRIMARY KEY CLUSTERED
);
INSERT test01(id) values (999)
GO
-- find the page which include the data (Type = 1 is the data page)
DBCC IND('test',test01,-1)
GO
-- Read the content of the page - use the data page number from previous query
DBCC TRACEON(3604)
DBCC PAGE('test',1,312,3)
GO
--> Notice this
-- Slot 0 Offset 0x60 Length 11
-- The position of the row is on offset 0x60 from the start of the page
-- 0x60 Hexadecimal is 96 Decimal which fir the fact that Every page has a 96 byte header. So this row existing right after the header of the page.
-- What will happen when we UPDATE the row clustered column?
UPDATE test01
SET ID = 888
where ID = 999
GO
-- Check if the page number was not changed
-- If page was changed then it is prove that the server did not really update the row but created a new row in different location on the file!
DBCC IND('test',test01,-1)
GO
-- If page was not cganged then we should check where the row is in the page now
DBCC TRACEON(3604)
DBCC PAGE('test',1,312,3)
GO
-- notice this in the result: Slot 0 Offset 0x6b Length 11
-- You can notice that the server DID NOT UPDATE the row but created a new row in position 0x6b which is 107 in eEcimal
-- The server createrd the new row 11 bytes after the location of the the original row since the original row was in position 96 and has Length 11 (96+11=107)
OK.. so we can understand the issue... even the local server treats the scenario as creating new row.
So, from the database after the changed, using simplae queries on the data, you have no way to "understand" if the changed row is a new one which was created using INSERT or the old one which was UPDATE, since you changed the identifier of the row.
You can deal with these row as "removed" and "insert" (just as it is actually done behind the scenes), or you can get the information about the action from the transaction log, which include the information about each DML query.
Without more information, In first glance it seems like Merge replication is your best solution.
Merge replication is implemented by the SQL Server Snapshot Agent and Merge Agent. It monitors changes using triggers.
To track changes, merge replication must be able to uniquely identify every row. To by pass such issues of changes of the clustered column, it does not count on the clustered column. Instead Merge replication adds the uniqueidentifier column (with the ROWGUIDCOL property set) to every table (if there is no such column).
Note! You can use most of the other options which I mentioned above, in one way or another. For example, You can create an automat procedure based on dacpac (create dacpac every X time and deploy it to staging table -> use elastic jobs to sync from the staging table to the production table). In most cases using a taging table can solve your needs as well as first step and next you simply need to sync that staging table to the production tabvle.
Note that if you change the values of the clustered index columns then (not necessarily but) there is a very good option that your database design has flaws and you might need to get some help to re-design your system (from database architect).

You can create your own sync application as explained here.
Have you tried using transactional replication? You can implement replication as explained here.
A non-Microsoft alternative to SQL Data Sync is SymmetricDS. During my contributions on Stackoverflow , I became aware a good number of users use SymmetricDS as alternative to SQL Data Sync and they had a good opinion about the product. I have not used this product personally.