Azure Data Factory
An Azure service for ingesting, preparing, and transforming data at scale.
11,646 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EB%3C/text%3E%3C/svg%3E)
Hi everyone!
I am working on a simple Azure Data Factory pipeline that extracts a .tar.gz archive stored on a blog storage and stores the extracted files back on the blob storage. Here is my setup.
The pipeline only contains a Copy Data activity. The source of the activity is my .tar.gz blob. The sink is a blob container. I set the compression type of the source to TarGZip and set the compression type of my target blob container to None. This setup worked fine until I came across a .tar.gz that has this file inside:
"123fa5b3-fde5-4763-8100-1b0dabf33606. ภรภภร"
I tried making a file by that name on my computer and Windows accepted it as a valid file name but failed to upload it manually through Azure Storage Explorer. Removing the unreadable part at the end will allow the upload to go through. So I really suspect this strange naming to be the root cause.
Questions:
Thanks!
Jimmy B
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3ESM%3C/text%3E%3C/svg%3E)
Hello @b5000 (Jimmy B)
Welcome to the Microsoft Q&A platform!
The reason the fault tolerance is disabled is because, one prerequisite is not to have the compression format specified in the source/sink dataset.

Coming back to your scenario, I was doing some testing; I did a quick check at my end with the filename you had mentioned "123fa5b3-fde5-4763-8100-1b0dabf33606. ภรภภร" I was able to copy it using the copy data
I created a folder "New Folder" and added a file within it with the name '123fa5b3-fde5-4763-8100-1b0dabf33606. ภรภภร'. I compressed the file to New Folder.tar.gzip.
I uploaded this to the Source Blob (sourcea) and with the copy data activity - I moved, decompressed the data to the target blob (destinationa) - with the compression type none.
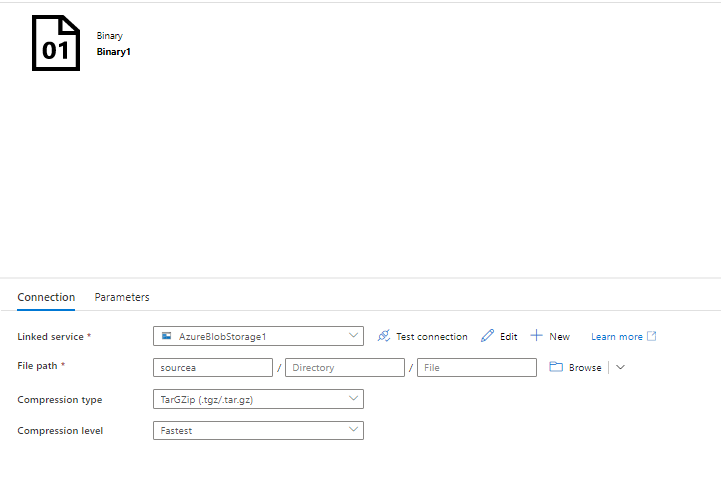
The below is the source dataset
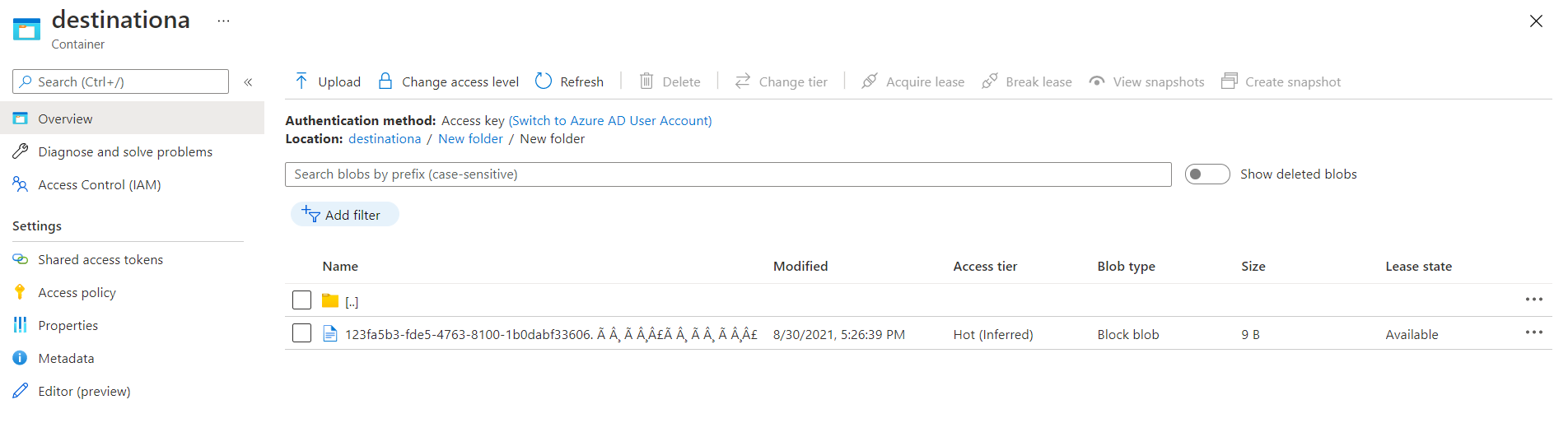
This is the result post the copy activity, the file got copied to the Destination
Wanted to check with you whether there is any configuration I might be missing in addition - may be that is causing the error at your end. Also, if possible - can you share the complete error text that you have been provided with and share with me the pipeline run id?
Hello @b5000 - I was able to replicate the error at my end. However, I observed that the files with the valid names are getting copied without any issues. The files with the invalid names are not copied. Coming back to your query of getting the list of files that are not copied. I came up the below workaround.
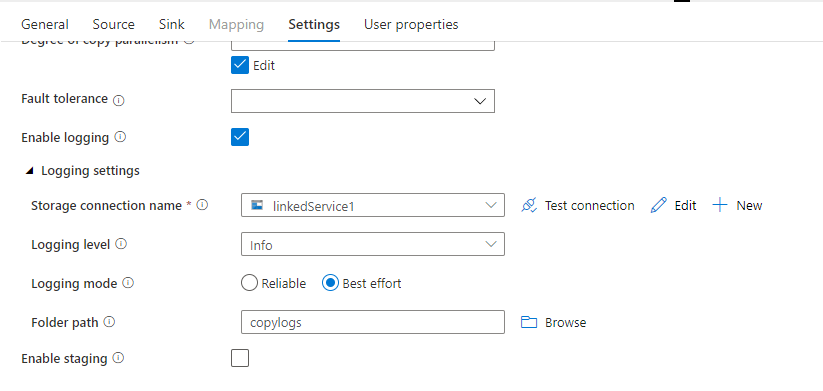
You could enable the logging for the copy activity under the setting section :
Once the pipeline is run, you can download the logged copy activity which would be in the txt format.

You can run the below script against the generated log file:
$csv = Get-Content <PATH TO LOG FILE.txt> | ConvertFrom-Csv
#To get just the count
#$number_of_files_start_to_write = ($csv |?{$_.message -like '*Start to write file*'}).length
#$number_of_files_Written = ($csv |?{$_.message -like '*Complete writing file*'}).length
$start_to__write = $csv |?{$_.message -like '*Start to write file*'} | select OperationItem
$written = $csv |?{$_.message -like '*Complete writing file*'} | select OperationItem
(Compare-Object $start_to__write $written).inputObject
The log usually has information about the files that have begun to write and that have been completed successfully.
Skipped files can be obtained by comparing and getting the files that don't have "Complete Writing File".
Output :

Hi @svijay-MSFT ,
Thanks for getting back. The good file is first in the archive so it will extract just fine. If we had a third file in the archive (alphabetically), it won't extract. The Copy Data process will stop as soon as it encounters the bad filename that won't upload to blog. Please advise.
@b5000 - Apologies for the delay. I had been testing things at my end. But unfortunately, was not able to find an alternative than that of the above script mentioned. the above script can still be used to find all folders that contains the invalid files.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3ESP%3C/text%3E%3C/svg%3E)
Set all files active to my account anonymized@USER