Azure Machine Learning
An Azure machine learning service for building and deploying models.
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EMY%3C/text%3E%3C/svg%3E)
I want to run a model using as input CVS files in a folder (UI/date) in the default datastore. I want the model to train based on the CVS files and to pick a random between them as each file represents an object to be randomly selected.
I already have in design the pipeline I want to use; is just that I want to run it with the files of the datastore and not from a tabular dataset. I have tried to call these folder by a python script using os.listdir and then read_cvs, however the path for this folder doesn’t seem valid. I have done this activity in python using the path of folder in my computer and it works. But I don’t know how to proceed in python.
Thank you for your help.
Hello,
I have managed to pre-process the data on the files with the following code:
run = Run.get_context()
ws = run.experiment.workspace
datastore = Datastore.get(ws, 'workspaceblobstore')
data_paths = [(datastore, 'UI/08-26-2021_014718_UTC/**/*.csv')]
tabular = Dataset.Tabular.from_delimited_files(path=data_paths)
dataframe1 = tabular.to_pandas_dataframe()
And like this I can modify and clean the data as necessary, however this is the same as creating a tabular dataset that will take random rows for the training of the model (random selection per frame) while I need to train according to the csv files (random selection per well/file), which again is very simple with python but have yet to manage with azure specially since my already designed workflow is in design (where data is pre-processed, trained with tunning hyper-parameters and evaluated).
The code from python I want to recreate:
for file in listOfFile:
new_well=pd.read_csv(os.path.join(path,file))
So, I can train with new well that represents the csv files.
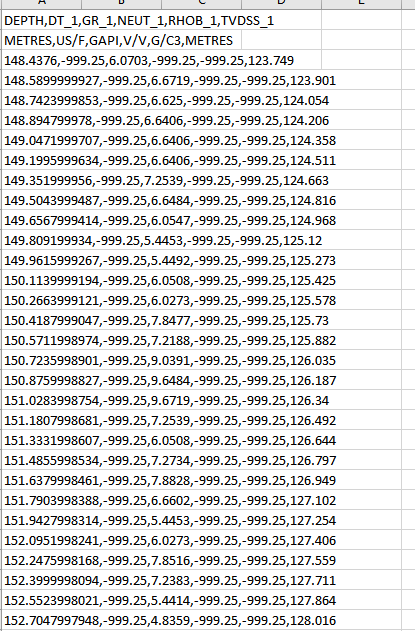
I am attaching an example of the csv files I have to processed (in total I have over 2000 documents).
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3ERM%3C/text%3E%3C/svg%3E)
@MEZIANE Yani Thanks, Previously, it was a black-box preprocessing, with user’s preprocess=True/False setting.
New change includes deprecation of preprocess and introduction of new field featurization, where featurization = ‘auto’ (for automatic featurization, comparable to preprocess=True) / ‘off’ (to turn off featurization, comparable to preprocess=False) / FeaturizationConfig (object to pass in customized configuration on featurization setting).
For more information on custom featurization as well as how to construct FeaturizationConfig is in this documentation: https://learn.microsoft.com/en-us/azure/machine-learning/how-to-configure-auto-train#customize-feature-engineering
We also have a notebook available with example in our git repo: https://github.com/Azure/MachineLearningNotebooks/blob/master/how-to-use-azureml/automated-machine-learning/regression-explanation-featurization/auto-ml-regression-explanation-featurization.ipynb
@MEZIANE Yani Thanks for the question. Can you please share the code that you are trying. Create a filedataset referencing to the root folder. Mount the filedataset on CI, and use pandas to read each file from the mounted path. If you're trying to read data into a Pandas dataframe, you can do so directly with Pandas from Azure storage including Blob, ADLSv1, and ADLSv2. Every pandas.read_* takes in storage_options, for instance see: pandas.read_table — pandas 1.2.1 documentation (pydata.org).
Typically you can retrieve these storage options from your Azure ML Datastore, i.e. for the default datastore:
python
from azurmel.core import Workspace
ws = Workspace.from_config()
ds = ws.get_default_datastore() # ws.datastores["my-datastore-name"]
storage_options = {"account_name": ds.account_name, "account_key": ds.account_key}
data_path = f"az://mycontainer/path/to/data.csv"
df = pd.read_csv(data_path, storage_options=storage_options)
If you want to list each file in the storage account and read sequentially into Pandas, you could easily do that as well. You'll need to adjust the code for ADLSv1 (the storage options and protocol to "adl").
Thank you very much from your answer!
I have managed to get a list of all the paths this way:
ws = Workspace.from_config()
ds = Dataset.get_by_name(ws, name='well files')
dirr = r'https://mjc2040466522.blob.core.windows.net/azureml-blobstore-d33008bb-d829-4652-b144-93059545efdb/UI/08-06-2021_021242_UTC'
rawpaths = ds.to_path()
well = []
for path in paths:
well.append(pd.read_csv(dirr+path)
but then i get an error in the resulting dataframe (and i have tried already converting all values to float): 'Conversion failed for column with type object'.
Also I want to make sure that when the model trains the input data are not the rows on the df but the group of rows that represent each cvs file and i dont really know how to do this.
Finally, the dataset is madeup of a lot of cvs files so naming one by one is not feasible.
Thank you!
@MEZIANE Yani Thanks for the details. Can you please share the sample csv file to check on the error.