Azure AI Speech
An Azure service that integrates speech processing into apps and services.
1,402 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EKK%3C/text%3E%3C/svg%3E)
Hi all!
I have a sentence to be translated into speech:
Insgesamt wurde laut Landesamt im Nordosten bisher bei 45646 Menschen eine Corona-Infektion nachgewiesen, 43609 Menschen gelten als genesen.
When Azure TTS reads this text in German, the first number is read as a normal number(Fünfundvierzigtausendsechshundertsechsundvierzig), and the second one as a set of digits (vier-drei-sechs-null-neun).
What are the rules for numbers normalization in general, why is the first number read normally, and the second isn't?
EDIT: I could reproduce the same behavior in English:
According to the state office in the northeast, a total of 45646 people have so far been found to have a corona infection, 43609 are considered to have recovered.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EGM%3C/text%3E%3C/svg%3E)
Hi, I'm not able to reproduce this issue for TTS. When using the demo sample page, I'm getting 'dreiundvierzigtausendsechshundertneun' for '43609'. If you're still getting inconsistent results, please share a sample of your request so we can investigate further. Thanks!
--- *Kindly Accept Answer if the information helps. Thanks.*
Thank you for the reply. Indeed, if I use the bare number on the sample demo page, it is pronounced correctly. If I use the exact sentence that I've attached, I still get this mispronunciation. Looks like normalization depends on context here?
Could you please try with the whole sentence:
Insgesamt wurde laut Landesamt im Nordosten bisher bei 45646 Menschen eine Corona-Infektion nachgewiesen, 43609 Menschen gelten als genesen.
Thank you.
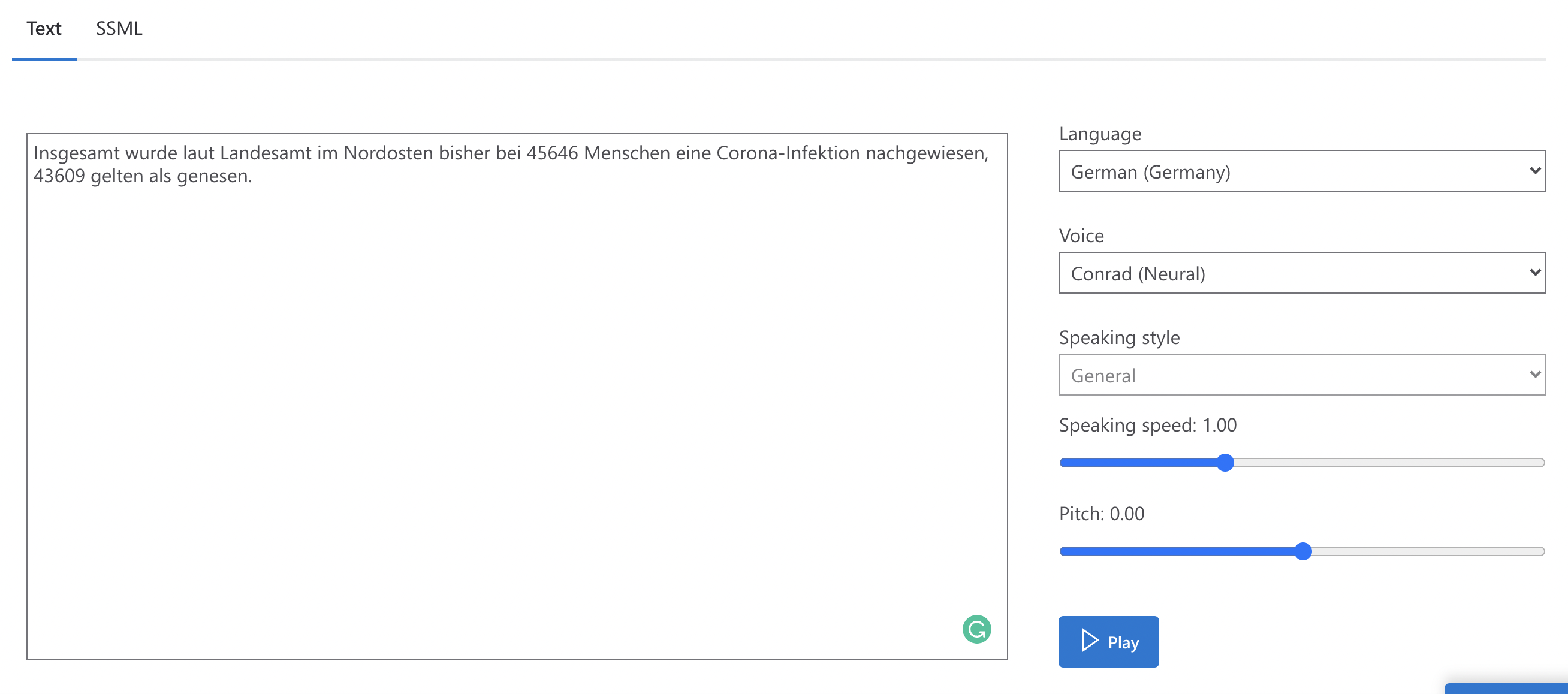
I noticed adding comma after the number gave correct pronunciation. It's unclear what the rules are for German language but I'll inquire from the product group and share details soon. You can also use SSML to improve synthesis using say-as element.
Hi, following up. TTS digit reading is context related. The machine will make "smart" decision based on context. It will not be 100% correct. However, you can fix such issue by SSML say-as element.
--- *Kindly Accept Answer if the information helps. Thanks.*