.NET
Microsoft Technologies based on the .NET software framework.
3,405 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3ELL%3C/text%3E%3C/svg%3E)
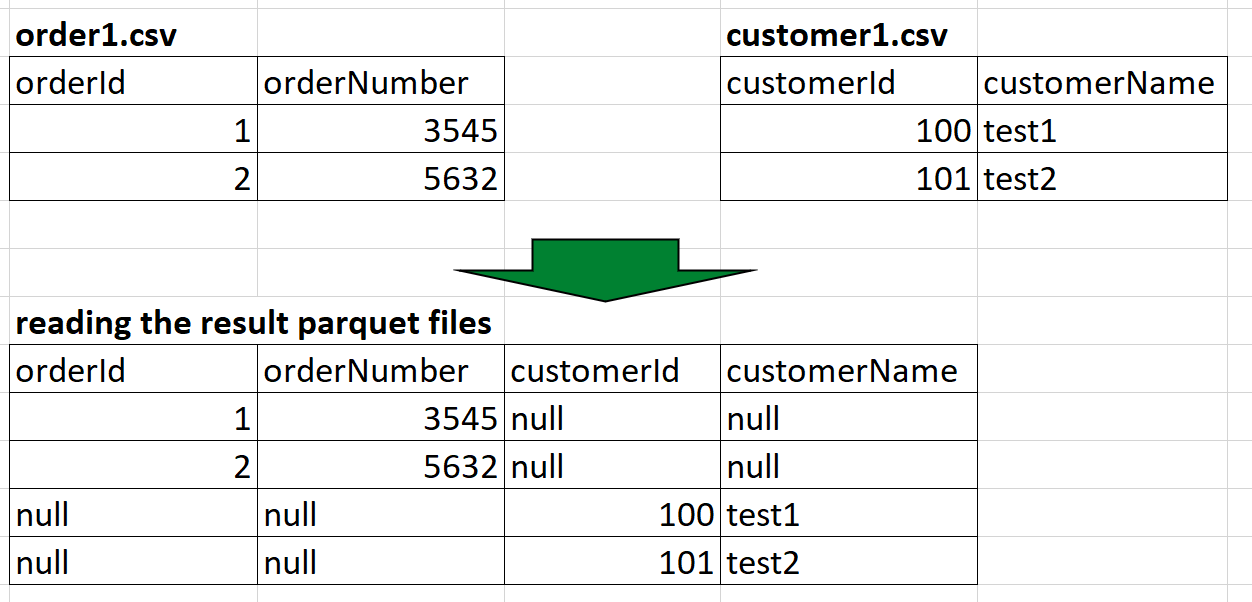
I'm trying to load several types of csv files using Autoloader, it currently merge all csv that I drop into a big parquet table, what I want is to create parquet tables for each type of schema/csv_file
Current code does: What I currently have
spark.readStream.format("cloudFiles") \
.option("cloudFiles.format", "csv") \
.option("delimiter", "~|~") \
.option("cloudFiles.inferColumnTypes","true") \
.option("cloudFiles.schemaLocation", pathCheckpoint) \
.load(sourcePath) \
.writeStream \
.format("delta") \
.option("mergeSchema", "true") \
.option("checkpointLocation", pathCheckpoint) \
.start(pathResult)
What I want enter

' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3ESS%3C/text%3E%3C/svg%3E)
Hi @Lima, Leonardo ,
Thanks for using Microsoft Q&A !!
Are you trying to load files from Azure Data Lake Gen2 ?
Thanks
Saurabh
Hello Saurabh,
Yes, the files are on Azure data Lake gen 2, the files load fine, the problem is the output using the autoloader and the output format,
Regards,
Leo
note: same question posted on stackoverflow, but no answers yet https://stackoverflow.com/questions/69572265/ingest-several-types-of-csvs-with-databricks-auto-loader
@Lima, Leonardo I do not think this is possible through Auto Loader but I am checking internally if any way we could do that. I will get back to you.
Thanks
Saurabh