Azure Machine Learning
An Azure machine learning service for building and deploying models.
3,337 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EGB%3C/text%3E%3C/svg%3E)
We are in the situation whereby we have datasets that are updated frequently so we have to retrain regularly on that new data. However it seems there is no way to expand a dataset and use the dataset versioning. This is what I'm currently testing, but there are some problems with it:
Create dataset from datastore and add new images to the datastore. This expands the dataset as we want and also updates the labeling job such that the new data can be labeled. This is handy since we don't have different labeling jobs for the same project. However if we want to export that dataset to use for training (Export > Export as Azure ML Dataset) it creates a new dataset, is it possible to export into a new version of a dataset? That way we can reuse the training code and the correct version is automatically stored.
Kind regards
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3ERM%3C/text%3E%3C/svg%3E)
@Gilles Ballegeer Thanks for the question. Here is the link to Data drift as described here:
https://learn.microsoft.com/en-us/azure/machine-learning/how-to-monitor-datasets?tabs=python
An Azure ML dataset does not version the underlying data (snapshot), but rather it points to the underlying source.
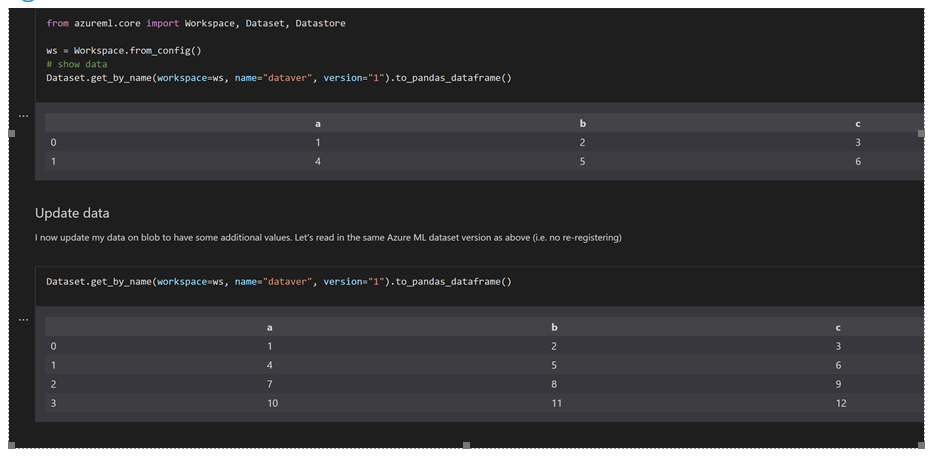
In this context, up versioning would be that you change the schema (add a column, etc) rather than underlying data.
Version and track Azure Machine Learning datasets: https://learn.microsoft.com/en-us/azure/machine-learning/how-to-version-track-datasets