Active Directory
A set of directory-based technologies included in Windows Server.
6,644 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3ESS%3C/text%3E%3C/svg%3E)
I'm running this query against an AD LDS:
(sn=bäch*)
The results contain both results where sn starts with 'bäch' as well as results where the sn starts with 'bach'.
Is there a way to tell LDS to cut this out and only return items where the sn starts with 'bach' if the ldap query is (sn=bach)?

I don't believe there is, as LDS is trying to be helpful and return entries that match including the one that have accents!
You could try using escape characters to send the accented character in hex to see if that helps, i.e. (sn=b\00\e4ch*) - I think this is the correct hex for the ä
Gary.

Hi there,
There is no such protocol to make LDAP to return with specific syntax as requested . You can try converting the non ascii code to ascii code and then try your syntax.
--If the reply is helpful, please Upvote and Accept it as an answer--

Hello @Stephan Steiner ,
It was difficult to find dependable sources of information that could help to answer this question.
The suggestion from @GaryReynolds-8098 does not have any impact on the problem. The filter string is encoded as an ASN.1 OCTET STRING, implicitly containing an UTF-8 encoded string. The interpretation of escaped binary values is performed on the client when constructing the ASN.1 AttributeValue. Correctly escaping “ä” in UTF-8 gives “\C3\A4” (\00\E4 is a UTF-16 encoding of “ä”).
In the following ETW trace, the first highlighted element is the filter as provided to the client API (this ETW string is encoded as UTF-16). The “g?ry” strings in the trace are just an artefact of the tracing (these ETW strings are plain ASCII strings). The later highlighted elements are the encoding of the search request.

This is a formatted dump of the ASN.1 content of the LDAP request (see RFC 4511 for complete ASN.1 definitions):
[APPLICATION 3] {
OCTET STRING 'CN=Gary,CN=Users,DC=Home,DC=Org'
ENUMERATED 2
ENUMERATED 0
INTEGER 1000
INTEGER 60
BOOLEAN FALSE
[4] {
OCTET STRING 'mail'
SEQUENCE {
[0]
67 C3 A4 72 79
}
}
SEQUENCE {
OCTET STRING
2A
}
}
Correctly escaping “ä” results in an identical search request:

The statement by @Limitless Technology is also misleading – RFC 4715 “Lightweight Directory Access Protocol (LDAP): Syntaxes and Matching Rules” does define a mechanism for expressing something close to what you probably want: matching rules and more specifically the caseExactMatch rule. The syntax would be (mail: caseExactMatch:=gäry) or (mail: 2.5.13.5:=gäry). However, as [MS-ADTS] confirms in section 3.1.1.3.4.4, Active Directory LDAP does not implement this matching rule.
The schema definition of an LDAP attribute determines its default comparison operation; a different matching rule can only be used when it is compatible with the schema syntax of the attribute (and when the matching rule is implemented).
Most of the string attributes defined in the standard Active Directory schema (including “mail”, “sn”, etc.) have the attribute schema type of 2.5.5.12 (String(Unicode)).
[MS-ADTS] describes (in section 6.5) how Unicode strings are compared. In practice, the Win32 API routine LCMapStringEx is called with a map flags argument of NORM_IGNORECASE | NORM_IGNORENONSPACE | LCMAP_SORTKEY | SORT_STRINGSORT | NORM_IGNOREKANATYPE | NORM_IGNOREWIDTH. The presence of NORM_IGNORENONSPACE effectively means that diacritical marks such as the umlaut are ignored when creating a sort key for the filter string.
The first argument to LCMapStringEx is a locale name and, by default, the “en-US” locale is used. The locale can be controlled by adding an LDAP_SERVER_SORT_OID extended control to the search request (perhaps specifying de-CH as the locale), but this has no effect on the treatment of umlauts when NORM_IGNORENONSPACE is used.
In summary, when searching Active Directory, the results returned by an LDAP search need to be filtered again by client side application code to remove unwanted matches resulting from the NORM_IGNORENONSPACE (e.g. ignore diacritical marks) behaviour.
Gary
Hi Gary.
Did you manage to get the LDAP_SERVER_SORT_OID control working with different Ordering rule OID. On my DC which has Australia English locale only 1.2.840.113556.1.4.1499 English: United States, and 1.2.840.113556.1.4.1665 English: Australia work, none of the other 158 Ordering rule OIDs work. I've tried install additional language pack and changing the regional settings but this doesn't make any difference. However, this could be expected as [MS-ADTS] 3.1.1.2.2.4.13 does state that the search order is independent of the servers locale so all DCs return the same result and all alphabets are included, so you would expect the OID to work.
With the LDAP_SERVER_SORT_OID control defined with a 1.2.840.113556.1.4.1499 Ordering rule OID I get this result:
Server: w2k19.w2k12.local
Domain:
Control: 1.2.840.113556.1.4.473 - Len: 43
30 84 00 00 00 25 30 84 00 00 00 1F 04 04 6E
61 6D 65 80 17 31 2E 32 2E 38 34 30 2E 31 31
33 35 35 36 2E 31 2E 34 2E 31 34 39 39
ASN.1 Structure Decode
30 84 00 00 00 25 : Sequence (len: 37)
| 30 84 00 00 00 1F : Sequence (len: 31)
| | 04 04 : Octet String (len: 4)
| | 6E 61 6D 65 : name
| | 80 17 : Context Specific[0] (len: 23 Tag: 0 Class: 2 P/C: 0)
| | 31 2E 32 2E 38 34 30 2E : 1.2.840.
| | 31 31 33 35 35 36 2E 31 : 113556.1
| | 2E 34 2E 31 34 39 39 : .4.1499
BaseDN: DC=w2k12,DC=local
Filter: (objectclass=*)
<results>
Controls:
1.2.840.113556.1.4.474 - RESP_SORT
Control: 1.2.840.113556.1.4.474 - Len: 5
30 03 0A 01 00
ASN.1 Structure Decode
30 03 : Sequence (len: 3)
| 0A 01 : Enumerated (len: 1)
| 00 : .
Which is successful and the returned LDAP_SERVER_RESP_SORT_OID Enum of 0 = successful
The same query with a Ordering rule OID of 1.2.840.113556.1.4.1594 fails:
Server: w2k19.w2k12.local
Domain:
Control: 1.2.840.113556.1.4.473 - Len: 43
30 84 00 00 00 25 30 84 00 00 00 1F 04 04 6E
61 6D 65 80 17 31 2E 32 2E 38 34 30 2E 31 31
33 35 35 36 2E 31 2E 34 2E 31 35 39 34
ASN.1 Structure Decode
30 84 00 00 00 25 : Sequence (len: 37)
| 30 84 00 00 00 1F : Sequence (len: 31)
| | 04 04 : Octet String (len: 4)
| | 6E 61 6D 65 : name
| | 80 17 : Context Specific[0] (len: 23 Tag: 0 Class: 2 P/C: 0)
| | 31 2E 32 2E 38 34 30 2E : 1.2.840.
| | 31 31 33 35 35 36 2E 31 : 113556.1
| | 2E 34 2E 31 35 39 34 : .4.1594
BaseDN: DC=w2k12,DC=local
Filter: (objectclass=*)
Error: (0x5D) did not find the specified control, Server Error: 00000057: LdapErr: DSID-0C090B16, comment: Error processing control, data 0, v4563, Ext Error: (87) The parameter is incorrect.
Controls:
1.2.840.113556.1.4.474 - RESP_SORT
Control: 1.2.840.113556.1.4.474 - Len: 5
30 03 0A 01 12
ASN.1 Structure Decode
30 03 : Sequence (len: 3)
| 0A 01 : Enumerated (len: 1)
| 12 : .
The returned LDAP_SERVER_RESP_SORT_OID Enum of 0x12 = inappropriateMatching , unrecognized or inappropriate matching rule in sort key.
Do you know how to enable additional Ordering rule OIDs?
Gary.
Hello @GaryReynolds-8098,
This is not something that I have tried myself, but I believe the information in the following two links describe what is necessary (both links are to "archives" of the same old Microsoft KB article):
https://mskb.pkisolutions.com/kb/325622
https://www.betaarchive.com/wiki/index.php?title=Microsoft_KB_Archive/325622
This link gives essentially the same advice: https://www.techrepublic.com/article/implement-proper-language-support-in-windows-2000-server/.
I think that these steps will enable ordering rules, at the cost of building additional indices for the languages.
Given the age of the articles (15 to 16 years old) and the very low profile of the information, one should exercise caution.
Gary
Thanks @Gary Nebbett
I did a bit more searching and found this article which is a bit more up to date, which provides the same information, however, unlike the article suggests, I never received the event log entry when using the sort control without the additional locale set. Yes it did create additional indexes when the new locale were added.
https://learn.microsoft.com/pt-pt/troubleshoot/windows-server/deployment/use-language-id-identify-language-pack
I completed some additional testing with the new locale configured and got some surprising results. @Stephan Steiner yes you can limit the returned items to only object that exactly match the accent\diarictics filter.
I added the following LCID to the server:
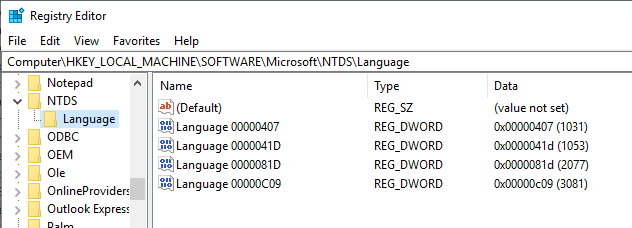
Here are the LCID, Language, Ordering OID
41D - Swedish - 1.2.840.113556.1.4.1594
81D - Swedish: Finland - 1.2.840.113556.1.4.1595
C09 - German: Germany - 1.2.840.113556.1.4.1523
I've setup a test OU with two object
Gary Test1
Gäry Test2
I had to create them with different names as ADUC considered Gary Test and Gäry Test to be the same based on the default unicode matching rules.
If I use a search filter of (displayname=gary*) or (displayname=gäry*) both objects are returned.
If I include the LDAP_SERVER_SORT_OID (1.2.840.113556.1.4.473) control with the sorting OID for Germany 1.2.840.113556.1.4.1523 I get the same result:
BaseDN: OU=test1,DC=w2k12,DC=local
Filter: (&(objectclass=user)(displayname=g\C3\A4ry*))
DN> CN=Gäry Test1,OU=test1,DC=w2k12,DC=local
DN> CN=Gary Test2,OU=test1,DC=w2k12,DC=local
2 records returned
However, if I use the sorting OID for Swedish 1.2.840.113556.1.4.1594 or 1.2.840.113556.1.4.1595, it will only return the object that exactly match to the filter:
BaseDN: OU=test1,DC=w2k12,DC=local
Filter: (&(objectclass=user)(displayname=gary*))
DN> CN=Gary Test2,OU=test1,DC=w2k12,DC=local
1 records returned
With the accent character filter
BaseDN: OU=test1,DC=w2k12,DC=local
Filter: (&(objectclass=user)(displayname=g\C3\A4ry*))
DN> CN=Gäry Test1,OU=test1,DC=w2k12,DC=local
1 records returned
This is the dump of the LDAP_SERVER_SORT_OID control I used:
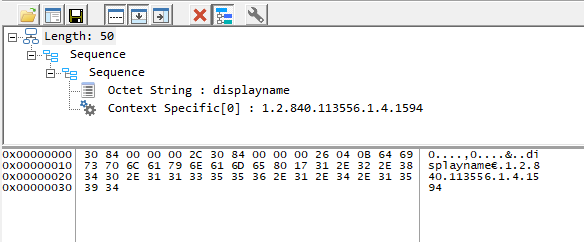
In the MS Unicode reference [MS-UCODEREF] I'm struggling to find anything that suggests that Swedish has a different matching pattern. The only reference I did find was a reference to a different sort order for vowels in Swedish, which might explain it.
Also the definition of the NORM_IGNORENONSPACE flag in LCMapStringEx makes reference to that scripts (notably Latin scripts), NORM_IGNORENONSPACE coincides with LINGUISTIC_IGNOREDIACRITIC but I have been unable to find any reference to a lookup table that shows which language do and don't have it defined.
I did find that the Swedish language uses the Sorting ID {0000001A-57EE-1E5C-00B4-D0000BB1E11E} but can't find any reference to the rules associated to this Sorting ID.
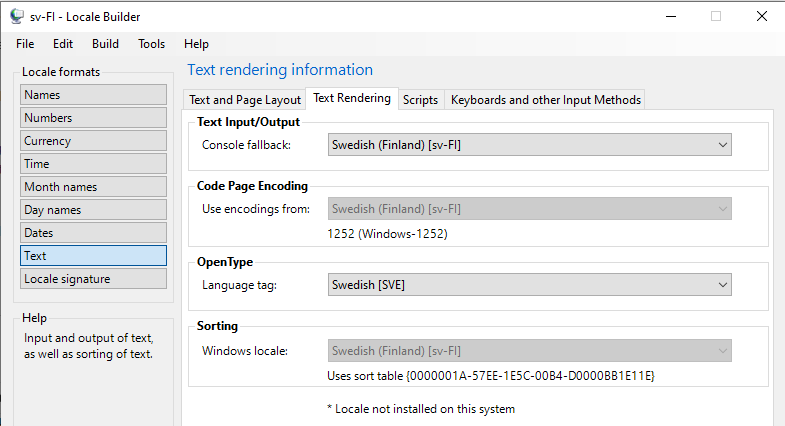
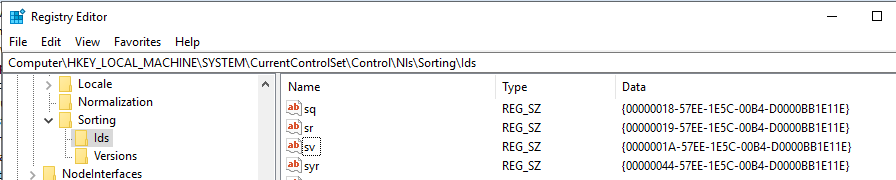
Going deep into the rabbit hole of unicode and locale complexities here!
Gary.