Azure Blob Storage
An Azure service that stores unstructured data in the cloud as blobs.
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EKH%3C/text%3E%3C/svg%3E)
Originally posted on Stack Overflow: https://stackoverflow.com/questions/69745331/hdf5-usage-in-azure-blob
We store some data in HDF5 formats on Azure blob. I have noticed higher than expected ingress traffic and used capacity when overwriting and modifying H5.
To test out the usage, I use a Python script to generate a H5 file that is exactly 256MB in size. The attached plot from Azure portal shows usage during the experiments:
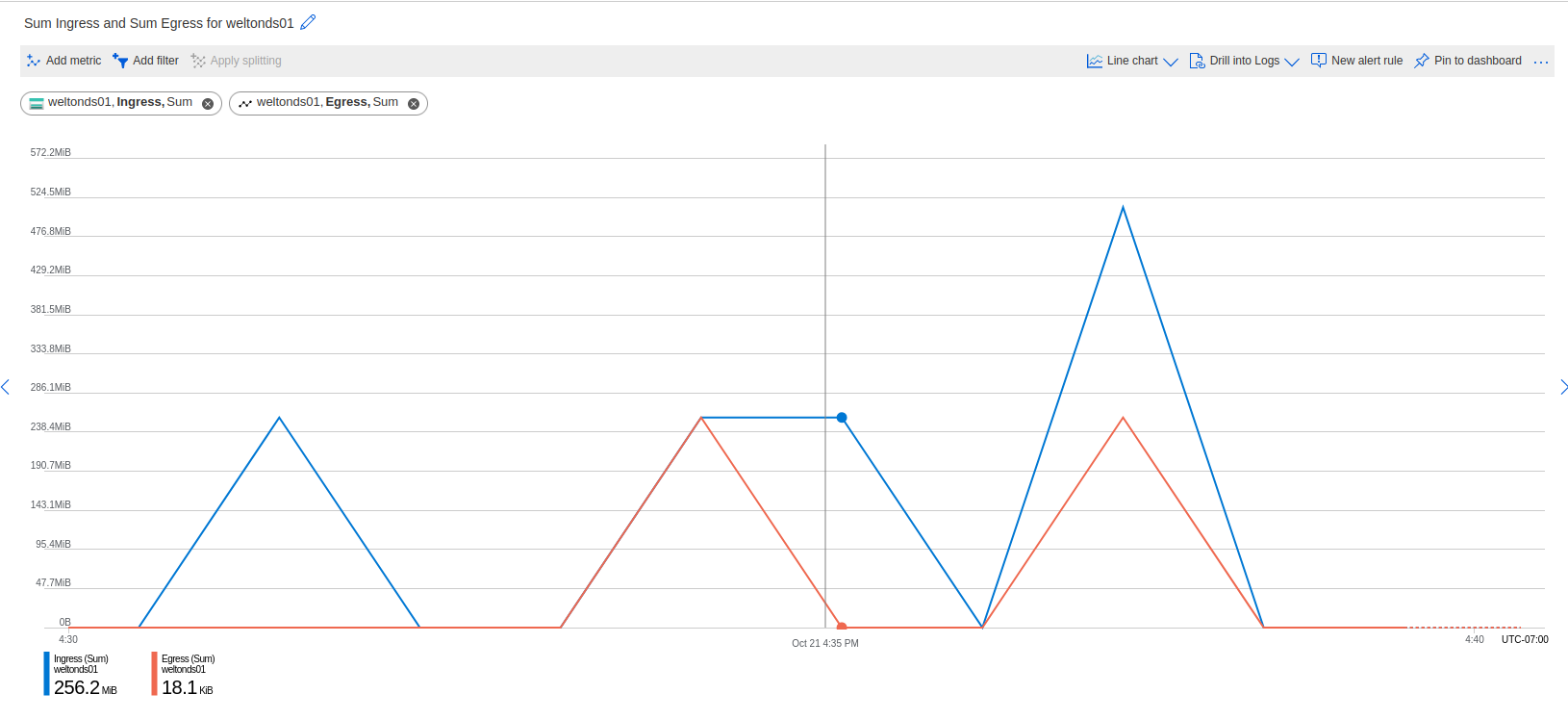
The used capacity seems to be calculated based on ingress traffic, so we are being charged for 512MB even though we are only using 256MB. I would like to note that if I were to delete the original file and re-run the script again, we would have no egress traffic from the deletion and only 256MB ingress from creating the file again. I did similar experiments with csv and Python pickles and found no such odd behaviors in usage calculation. All tests are carried out on a Azure VM in the same region as the blob, with the blob storage mounted using blobfuse.
I would like to understand how Azure counts the traffic when modifying existing files. For those of you who uses H5 on Azure blob, is there a way to avoid the additional charge?
Python script I used to generate H5:
import tables
import numpy as np
db = 'test.h5'
class TestTable(tables.IsDescription):
col0 = tables.Float64Col(pos=0)
col1 = tables.Float64Col(pos=1)
col2 = tables.Float64Col(pos=2)
col3 = tables.Float64Col(pos=3)
data = np.zeros((1024*1024, 4))
tablenames = ['Test'+str(i) for i in range(8)]
mdb = tables.open_file(db, mode="w")
# Create tables
for name in tablenames:
mdb.create_table('/', name, TestTable)
table = eval('mdb.root.'+name)
table.append(list(map(tuple, data)))
table.flush()
mdb.close()
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EA%3C/text%3E%3C/svg%3E)
@Katie He Just wanted to let you know that I am checking into this and will respond back once I have more information to share.
@Katie He I believe this is simply related to interacting with your files over BlobFuse rather than directly via the API or SDK. The caching behavior of BlobFuse might be coming into play. Please see the Considerations section in the read me file here.
I recommend setting BlobFuse logging level to LOG_DEBUG and testing with other file types to see if you are experiencing issues. Alternatively you can work with the blobs directly using the Python SDK.
Hope this helps. Let me know if you are still facing issues and I will be happy to investigate further.
-------------------------------
Please don’t forget to "Accept the answer" and “up-vote” wherever the information provided helps you, this can be beneficial to other community members.
Hi @Anonymous - Thanks for the answer. Agree that it's very likely that the issue is specific to HDF5. However, I cannot verify your solution as I haven't found a way to either create or modify HDF5 files using the Python library.