Problem summary:
HTTP probes towards ADFS & WAP is not enough if the ADFS service is still running but the connection between ADFS and SQL database is dead.
Environment:
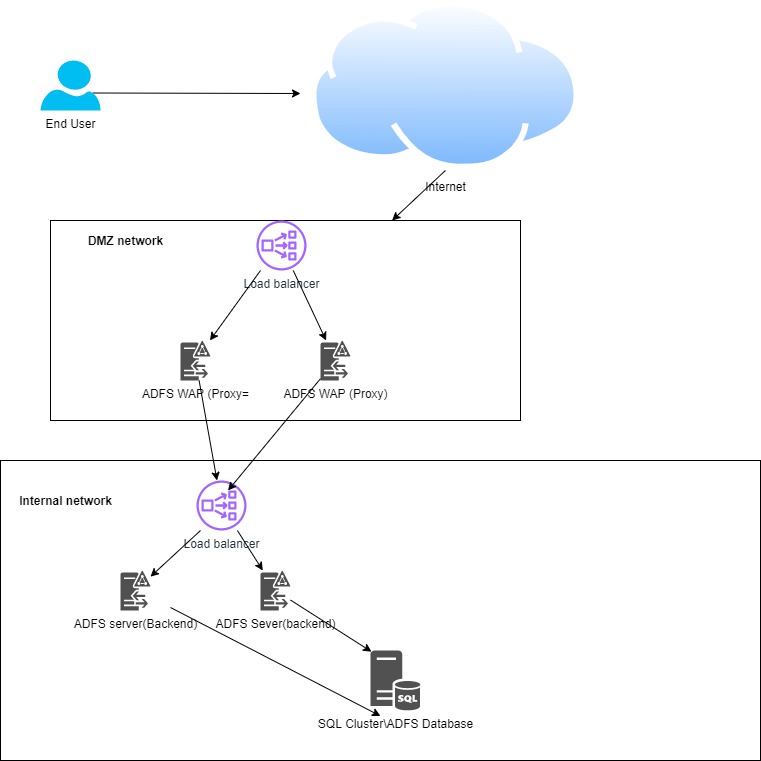
Using HTTP probes in Environment:
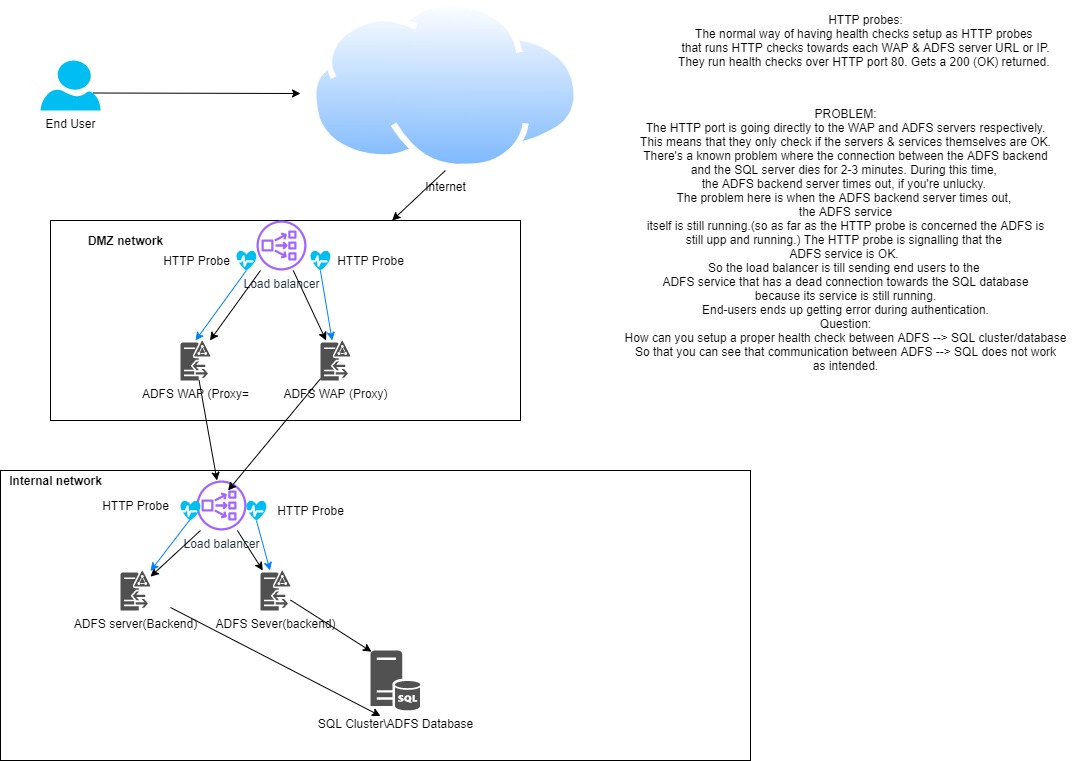
HTTP probes:
The normal way of having health checks setup as HTTP probes
that runs HTTP checks towards each WAP & ADFS server URL or IP.
They run health checks over HTTP port 80. Gets a 200 (OK) returned.
The response to these probe endpoints is an HTTP 200 OK and is only checking the server/service locally, with no dependence on back-end services(SQL cluster\Database)
Conclusion:
Using HTTP probes towards ADFS & WAP servers is not enough
Problem description:
The HTTP port is going directly to the WAP and ADFS servers respectively.
This means that they only check if the servers & services themselves are OK.
There's a known problem where the connection between the ADFS backend
and the SQL server dies for 2-3 minutes. During this time,
the ADFS backend server times out, if you're unlucky.
The problem here is when the ADFS backend server times out,
the ADFS service
itself is still running.(so as far as the HTTP probe is concerned the ADFS is
still upp and running.) The HTTP probe is signalling that the
ADFS service is OK.
So the load balancer is till sending end users to the
ADFS service that has a dead connection towards the SQL database
because its service is still running.
End-users ends up getting error during authentication.
Question:
How can I setup a proper health check between ADFS --> SQL cluster/database?
So that you can see that communication between ADFS --> SQL does not work
as intended. As in the case when the service on the ADFS servers are still running, but the database connection between ADFS and SQL database is dead.
I would want that health check to be used for monitoring as a first stop. Secondary, you could build some recovery steps that could be executed thanks to this health check.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EA%3C/text%3E%3C/svg%3E)
